%pylab inline
import pandas as pd
Limited Dependent Variables¶
The dependent variable may be discrete, and could be binomial or multinomial. That is, the dependent variable is limited. In such cases, we need a different approach.
Discrete dependent variables are a special case of limited dependent variables. The Logit model we look at here is a discrete dependent variable model. Such models are also often called qualitative response (QR) models.
The Logistic Function¶
$$ y = \frac{1}{1+e^{-f(x_1,x_2,...,x_n)}} \in (0,1) $$
where
$$ f(x_1,x_2,...,x_n) = a_0 + a_1 x_1 + ... + a_n x_n \in (-\infty,+\infty) $$
#Sigmoid Function
def logit(fx):
return exp(fx)/(1+exp(fx))
fx = linspace(-4,4,100)
y = logit(fx)
plot(fx,y)
xlabel('f(x)')
ylabel('Logit value')
grid()

#Import the SBA Loans dataset
sba = pd.read_csv("data/SBA.csv")
print(sba.columns)
#Feature engineering
sba["GuaranteePct"] = sba.SBAGuaranteedApproval.astype("float")/sba.GrossApproval.astype("float")
X = sba[['ApprovalFiscalYear', 'InitialInterestRate', 'TermInMonths',
'RevolverStatus','JobsSupported','GuaranteePct']]
x1 = pd.get_dummies(sba.subpgmdesc)
#x1 = x1.drop(x1.columns[0],axis=1)
X = pd.concat([X,x1],axis=1)
x2 = pd.get_dummies(sba.BusinessType)
#x2 = x2.drop(x1.columns[0],axis=1)
X = pd.concat([X,x2],axis=1)
X.head()
#Dependent categorical variable
y = pd.get_dummies(sba.LoanStatus)
y.head()
y.sum()
idx1 = list(where(y.CHGOFF==1)[0])
idx2 = list(where(y.PIF==1)[0])
idx = append(idx1,idx2)
print(len(idx))
X = X.iloc[idx]
X["Intercept"] = 1.0
y = y.CHGOFF.iloc[idx]
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
from sklearn import metrics
from sklearn.cross_validation import cross_val_score
# instantiate a logistic regression model, and fit with X and y
model = LogisticRegression()
model = model.fit(X, y)
# check the accuracy on the training set
model.score(X, y)
pd.DataFrame({'X':X.columns, 'Coeff':model.coef_[0]})
Odds Ratio¶
What are odds ratios? An odds ratio (OR) is the ratio of probability of success to the probability of failure. If the probability of success is $p$, then
$$ OR = \frac{p}{1-p}; \quad \quad p = \frac{OR}{1+OR} $$
Odds Ratio Coefficients¶
In a linear regression, it is easy to see how the dependent variable changes when any right hand side variable changes. Not so with nonlinear models. A little bit of pencil pushing is required (add some calculus too).
The coefficient of an independent variable in a logit regression tell us by how much the log odds of the dependent variable change with a one unit change in the independent variable. If you want the odds ratio, then simply take the exponentiation of the log odds.
#Example
p = 0.3
OR = p/(1-p)
print('OR old =', OR)
beta = 2
OR_new = OR * exp(beta)
print('OR new =', OR_new)
p_new = OR_new/(1+OR_new)
print('p new =', p_new)
# Evaluate the model by splitting into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
model2 = LogisticRegression()
model2.fit(X_train, y_train)
# Predict class labels for the test set
predicted = model2.predict(X_test)
print(predicted)
# Generate class probabilities
probs = model2.predict_proba(X_test)
print(probs)
Metrics¶
Accuracy: the number of correctly predicted class values.
ROC and AUC: The Receiver-Operating Characteristic (ROC) curve is a plot of the True Positive Rate (TPR) against the False Positive Rate (FPR) for different levels of the cut-off posterior probability. This is an essential trade-off in all classification systems.
TPR = sensitivity or recall = TP/(TP+FN)
FPR = (1 − specificity) = FP/(FP+TN)
AUC of the ROC curve¶
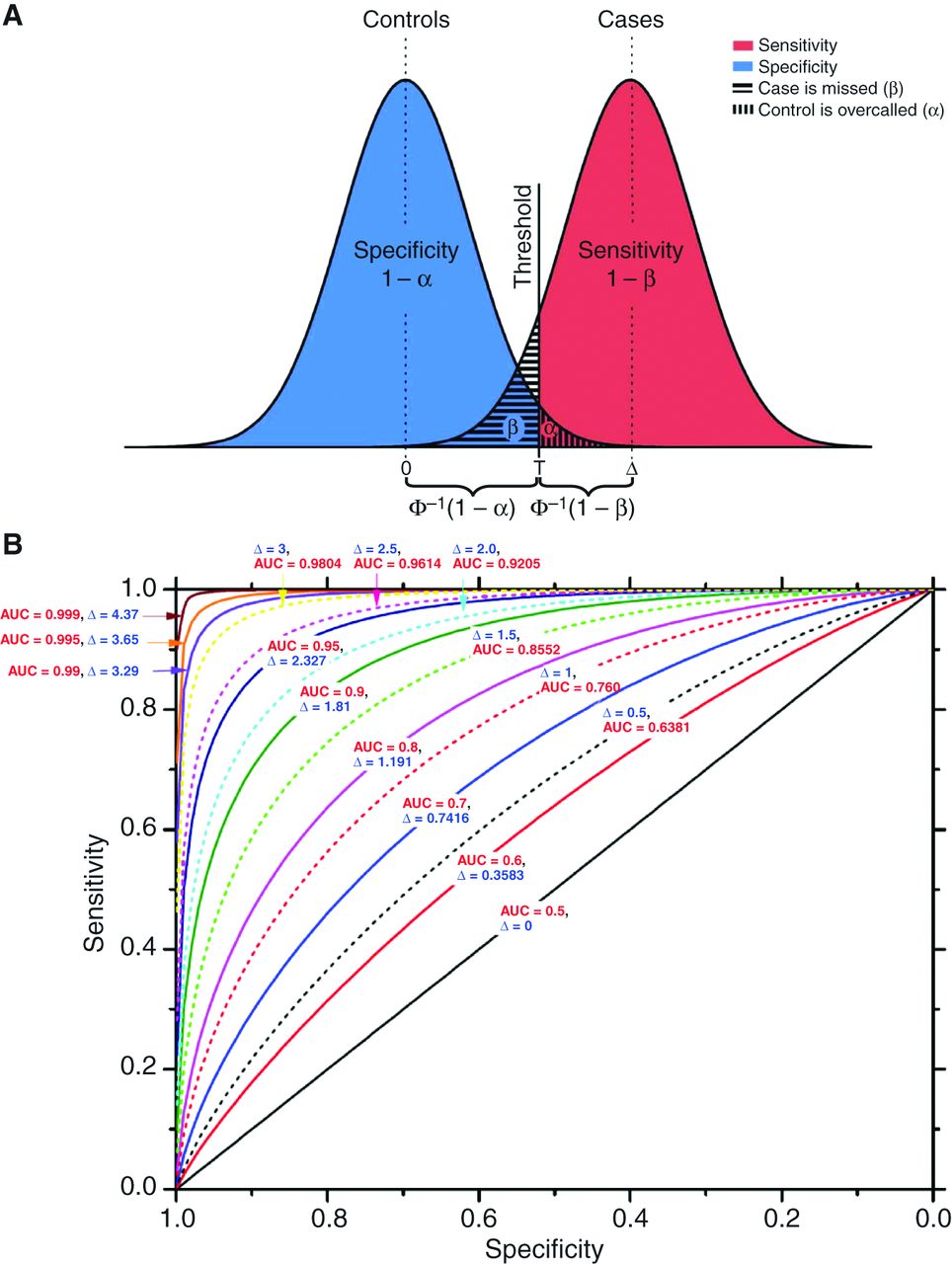
# generate evaluation metrics
print(metrics.accuracy_score(y_test, predicted))
print(metrics.roc_auc_score(y_test, probs[:, 1]))
More Metrics¶
Precision = $\frac{TP}{TP+FP}$
Recall = $\frac{TP}{TP+FN}$
F1 score = $\frac{2}{\frac{1}{Precision} + \frac{1}{Recall}}$
(F1 is the harmonic mean of precision and recall.)
print(metrics.confusion_matrix(y_test, predicted))
print(metrics.classification_report(y_test, predicted))
Using R¶
We can also use the R programming language as it if often better suited to econometrics.
We will use a basketball data set this time for a change of pace.
The rpy2 package allows us to call R from a Python notebook. https://rpy2.bitbucket.io/
#Load R interface
%load_ext rpy2.ipython
%%R
#Read in the data
ncaa = read.table("data/ncaa.txt",header=TRUE)
print(dim(ncaa))
head(ncaa)
%%R
#Create the discrete dependent variable
y = c(rep(1,32),rep(0,32))
print(y)
%%R
#FIT THE MODEL
x = as.matrix(ncaa[4:14])
h = glm(y~x, family=binomial(link="logit"))
names(h)
%%R
#RESULTS
summary(h)
Multinomial Logit¶
The probability of each class $(0,1,...,k)$ for $(k+1)$ classes is as follows:
$$ Pr[y=j] = \frac{e^{a_j^\top x}}{\sum_{i=1}^k e^{a_i^\top x}} $$
and
$$ Pr[y=0] = \frac{1}{\sum_{i=1}^k e^{a_i^\top x}} $$
Note that $\sum_{i=1}^k Pr[y=i] = 1$.
%%R
#CREATE 4 CLASSES THIS TIME
y = c(rep(3,16),rep(2,16),rep(1,16),rep(0,16))
print(y)
%%R
#FIT THE MODEL
library(nnet)
res = multinom(y~x)
%%R
#SHOW RESULTS
res
%%R
#SHOW FITTED PROBABILITIES
res$fitted.values