In [1]:
%pylab inline
import pandas as pd
What is kNN?¶
This is one of the simplest algorithms for classification and grouping.
Simply define a distance metric over a set of observations, each with $M$ characteristics, i.e., $x_1,x_2,...,x_M$.
- Compute the pairwise distance between each pair of observations, using any of the standard metrics. For example, Euclidian distance between data $x$ and $y$:
$$ d = \sqrt{\sum_{i=1}^M (x_i - y_i)^2} $$
Next, fix $k$, the number of nearest neighbors in the population to be considered.
Finally, assign the category based on which one has the majority of nearest neighbors to the case we are trying to classify.
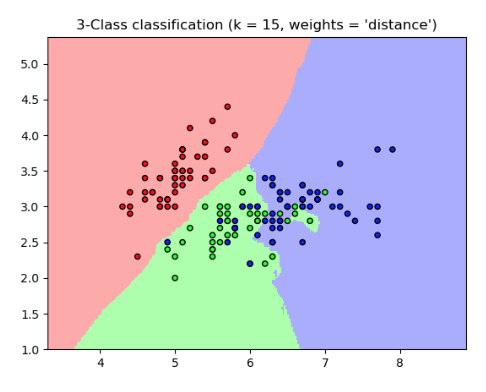
Classified Neighborhoods¶
In [2]:
#PREDICTION ON TEST DATA
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from sklearn.metrics import roc_curve,auc
from sklearn.metrics import confusion_matrix
NCAA Dataset¶
In [3]:
ncaa = pd.read_table("data/ncaa.txt")
yy = append(list(ones(32)), list(zeros(32)))
ncaa["y"] = yy
ncaa.head()
Out[3]:
In [4]:
#CREATE FEATURES
y = ncaa['y']
X = ncaa.iloc[:,2:13]
X.head()
Out[4]:
In [36]:
#FIT MODEL
from sklearn.neighbors import NearestNeighbors as KNN
model = KNN(n_neighbors=5, algorithm='ball_tree')
model.fit(X)
distances, indices = model.kneighbors(X)
print(indices[:6])
In [24]:
nn_sum = [sum(y[j]) for j in indices]
ypred = [1 if j>2 else 0 for j in nn_sum]
print(ypred)
In [25]:
#CONFUSION MATRIX
cm = confusion_matrix(y, ypred)
cm
Out[25]:
In [26]:
#ACCURACY
accuracy_score(y,ypred)
Out[26]:
In [29]:
#CLASSIFICATION REPORT
print(classification_report(y, ypred))
Credit Card Dataset¶
In [31]:
#LOAD IN CREDIT CARD DATA
import pickle
CCdata = pickle.load(open("data/CCdata.p", "rb"))
X_train = CCdata['X_train']
y_train = CCdata['y_train']
X_test = CCdata['X_test']
y_test = CCdata['y_test']
In [43]:
#FIT MODEL
from sklearn.neighbors import KNeighborsClassifier as KNNC
model = KNNC(n_neighbors=5, algorithm='ball_tree')
model.fit(X_train, y_train)
Out[43]:
In [44]:
#CONFUSION MATRIX
ypred = model.predict(X_test)
cm = confusion_matrix(y_test, ypred)
cm
Out[44]:
In [45]:
#ACCURACY
accuracy_score(y_test,ypred)
Out[45]:
In [46]:
#CLASSIFICATION REPORT
print(classification_report(y_test, ypred))
In [47]:
#ROC, AUC
y_score = model.predict_proba(X_test)[:,1]
fpr, tpr, _ = roc_curve(y_test, y_score)
title('ROC curve')
xlabel('FPR (Precision)')
ylabel('TPR (Recall)')
plot(fpr,tpr)
plot((0,1), ls='dashed',color='black')
plt.show()
print('Area under curve (AUC): ', auc(fpr,tpr))
