In [1]:
%pylab inline
import pandas as pd
Credit Card Dataset¶
In [2]:
#LOAD IN CREDIT CARD DATA
import pickle
CCdata = pickle.load(open("data/CCdata.p", "rb"))
X_train = CCdata['X_train']
y_train = CCdata['y_train']
X_test = CCdata['X_test']
y_test = CCdata['y_test']
In [3]:
hist(y_train,3)
show()

In [4]:
hist(y_test,3)
show()

Linear Discriminant Analysis¶
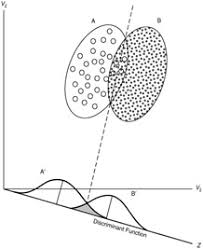
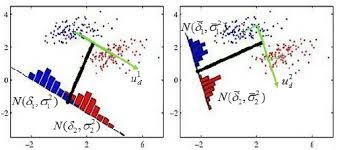
http://srdas.github.io/MLBook/DiscriminantFactorAnalysis.html#discriminant-analysis
Discriminant Function¶
$$ D = a_1 x_1 + a_2 x_2 + ... + a_K x_K = \sum_{k=1}^K a_k x_k $$
$D$ is often replace by $Z$, which leads to the notion of "Z-score" or discriminant score.
In [5]:
#FIT THE LDA MODEL
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
model = LDA()
model.fit(X_train, y_train)
Out[5]:
In [6]:
#PREDICTION ON TEST DATA
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from sklearn.metrics import roc_curve,auc
from sklearn.metrics import confusion_matrix
y_hat = model.predict(X_test)
In [7]:
#ACCURACY
#Out of sample
accuracy_score(y_test,y_hat)
Out[7]:
In [8]:
#CLASSIFICATION REPORT
print(classification_report(y_test, y_hat))
In [9]:
#ROC, AUC
y_score = model.predict_proba(X_test)[:,1]
fpr, tpr, _ = roc_curve(y_test, y_score)
title('ROC curve')
xlabel('FPR (Precision)')
ylabel('TPR (Recall)')
plot(fpr,tpr)
plot((0,1), ls='dashed',color='black')
plt.show()
print('Area under curve (AUC): ', auc(fpr,tpr))

In [10]:
#CONFUSION MATRIX
cm = confusion_matrix(y_test, y_hat)
cm
Out[10]:
NCAA Dataset¶
In [11]:
ncaa = pd.read_table("data/ncaa.txt")
yy = append(list(ones(32)), list(zeros(32)))
ncaa["y"] = yy
ncaa.head()
Out[11]:
In [12]:
#CREATE FEATURES
y = ncaa['y']
X = ncaa.iloc[:,2:13]
X.head()
Out[12]:
In [13]:
#FIT MODEL
model = LDA()
model.fit(X,y)
ypred = model.predict(X)
In [14]:
#CONFUSION MATRIX
cm = confusion_matrix(y, ypred)
cm
Out[14]:
In [15]:
#ACCURACY
accuracy_score(y,ypred)
Out[15]:
In [16]:
#CLASSIFICATION REPORT
print(classification_report(y, ypred))
In [17]:
#ROC, AUC
y_score = model.predict_proba(X)[:,1]
fpr, tpr, _ = roc_curve(y, y_score)
title('ROC curve')
xlabel('FPR (Precision)')
ylabel('TPR (Recall)')
plot(fpr,tpr)
plot((0,1), ls='dashed',color='black')
plt.show()
print('Area under curve (AUC): ', auc(fpr,tpr))
