Chapter 14 Reinforcement Learning
Reinforcement Learning (RL) has become popular in the pantheon of deep learning with video games, checkers, and chess playing algorithms. DeepMind trained an RL algorithm to play Atari, Mnih et al. (2013). More recently, just two years ago, DeepMind’s Go playing system used RL to beat the world’s leading player, Lee Sedol, and Silver et al. (2016) provides a good overview of their approach. There are many good books one may refer to for RL. See for example, Sutton and Barto (1998); Sugiyama, Hachiya, and Morimura (2013). In the area of finance, there has been intermittent progress over the years, as dynamic programming has been scaled up using RL, as evidenced by many papers: Moody and Saffell (2001); Dempster and Leemans (2006); Corazza and Bertoluzzo (2014); Duarte (2017); and Jiang, Xu, and Liang (2017).
RL is the deep learning application of the broader arena of dynamic programming. It is an algorithm that attempts to maximize the long-term value of a strategy by optimal action at every point in time, where the action taken depends on the state of the observed system. All these constructs are determined by functions of the state \(S\) of the system. The value of the long-term strategy is called the “value” function \(V(S)\),and the optimal action at any time is known as the decision or “policy” function \(P(S)\). Note that the state may also include the time \(t\) at which the system is observed.
14.1 Dynamic Programming
Dynamic programming (DP) was formalized by Richard Bellman in his pioneering book, see Bellman (1957). See also Howard (1966). We initiate our discussion here with an example of dynamic programming.
Take a standard deck of 52 playing cards, and shuffle it. Given a randomly shuffled set of cards, you are allowed to pick one at a time, replace and reshuffle the deck, and draw again, up to a maximum of 10 cards. You may stop at any time, and collect money as follows. If you have an ace, you get \(\$14\). Likewise, a king, queen, and jack return you \(\$13, \$12, \$11\), respectively. The remaining cards give you their numeric value. Every time you draw a card, you can decide if you want to terminate the game and cash in the value you hold, or discard the card and try again.
The problem you are faced with is to know when to stop and cash in, which depends on the number of remaining draws \(n\), and the current card value \(x\) that you hold. Therefore, the state of the system at draw \(t\) is defined by the current card value \(x_t\) and the number of remaining draws, \(10-t\), i.e., \(S = (x_t,10-t)\). The policy function is binary as follows:
\[ P(x_t,10-t) = \{\mbox{Halt} = x_t,\mbox{Continue}=\max[P(x_{t+1},10-(t+1))]\} \]
The value function is likewise a function of the state, i.e., \(V(x_t,10-t)\).
These problems are solved using backward recursion. To begin we assume we are at the last draw (\(\#10\)), having decided to reject all preceding 9 values. The expected value of the draw will be the average of the value of all 13 cards ranging from 2 to 14, i.e., \((2+3+...+13+14)/13 = 8\). The expected value of the strategy is
\[ E_{10}[V(x_{10},0)] = 8 \]
Now, roll back to \(t=9\), and work out the optimal policy function. We already know that if we hold on till \(t=10\), our expected value is 8. So if \(x_9 < 8\), we hold on, else we terminate the strategy if \(x_9 \geq 8\). (Note that if we are risk averse, we prefer 8 now than the expected value of 8 in the next draw.) The expected value of the strategy is:
\[ E_9[V(x_9,1)] = (8+9+10+11+12+13+14) \cdot \frac{1}{13} + 8 \cdot \frac{6}{13} = 9.615385 \]
Now, roll back to \(t=8\). We have worked out that if we hold on till \(t=9\), our expected value is 9.62. So if \(x_8 \leq 9\), we “Continue”, else we “Halt” the strategy if \(x_8 \geq 10\). The expected value of the strategy is:
\[ E_8[V(x_8,2)] = (10+11+12+13+14) \cdot \frac{1}{13} + 9.615385 \cdot \frac{8}{13} = 10.53254 \] And so on …
We can write a small program to solve the entire problem with the policy cutoffs at each \(t\).
#Dynamic Program to solve the cards problem
T = 10
cards = 2:14
n = length(cards)
V = rep(0,10) #Value of optimal policy at each t
P = matrix(0,13,10) #Policy {0,1} for all possible cards x at all t
t = 10
V[t] = mean(cards)
print(c(t,V[t]))## [1] 10 8for (t in 9:1) {
idx = which(cards >= V[t+1])
V[t] = sum(cards[idx])/n + V[t+1]*(n-length(idx))/n
P[idx,t] = 1
print(c(t,V[t]))
}## [1] 9.000000 9.615385
## [1] 8.00000 10.53254
## [1] 7.00000 11.13792
## [1] 6.00000 11.56763
## [1] 5.00000 11.89817
## [1] 4.00000 12.15244
## [1] 3.00000 12.35976
## [1] 2.00000 12.53518
## [1] 1.00000 12.68361As we can see from the first set of values, \(V_t\), the expected value of the strategy is the highest with a large number of remaining draws. And then declines as we get closer to the end. The table of the policy function \(P_t\) shown next, has the card values on the rows and the draw number on the columns.
P = cbind(2:14,P)
P[,T+1] = 1
P## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11]
## [1,] 2 0 0 0 0 0 0 0 0 0 1
## [2,] 3 0 0 0 0 0 0 0 0 0 1
## [3,] 4 0 0 0 0 0 0 0 0 0 1
## [4,] 5 0 0 0 0 0 0 0 0 0 1
## [5,] 6 0 0 0 0 0 0 0 0 0 1
## [6,] 7 0 0 0 0 0 0 0 0 0 1
## [7,] 8 0 0 0 0 0 0 0 0 1 1
## [8,] 9 0 0 0 0 0 0 0 0 1 1
## [9,] 10 0 0 0 0 0 0 0 1 1 1
## [10,] 11 0 0 0 0 0 0 1 1 1 1
## [11,] 12 0 0 0 1 1 1 1 1 1 1
## [12,] 13 1 1 1 1 1 1 1 1 1 1
## [13,] 14 1 1 1 1 1 1 1 1 1 1The first column above gives the card values. The next 10 columns show the 10 draws, with each column containing values \(\{0,1\}\), where \(0\) stands for “Continue” and \(1\) stands for “Halt”. Clearly if you draw a high value card, you will halt sooner.
To summarize, the vector \(V\) showed the value function at each \(t\), and the matrix \(P\) shows the decision rule for each \(x_t\). Notice that the problem was solved using “backward recursion”. The value of the entire 10 draws at the beginning of the strategy is \(12.68\), and is obtained from the value function.
Where does deep learning (specifically RL) enter this problem setting? The short answer is that when the state space \(S\) becomes too large, it is hard to find explicit functions for the optimal policy function and the value function. These are then approximated using deep neural nets.
14.2 Random Policy Generation
In the preceding analysis, we have calculated the exact policy for all states \((x_t,T-t)\). This is in the form of the policy function \(P(x_t,T-t)\), which in the example above was a decision to terminate the game (value 1) or continue (value 0), presented in a grid \(P\) of dimension \(13 \times 10\).
Rather than use backward recursion, we may instead employ random policy generation. This would entail random generation of policies in a grid of the same dimension, i.e., populate the grid with values \(\{0,1\}\), and then assess the value function using the policy grid for a large random set of draws. Hence, the random policy is discovered in two steps:
- Generate 10,000 paths of 10 card draws, i.e., a sequence of 10 numbers randomly generated from values \(2,3,...,13,14\).
- Generate 1,000 random policy grids, and assess each one for expected value, i.e., determine the value function.
First, we generate the random draws.
#Generate the random paths of card draws
T = 10
m = 10000
draws = matrix(sample(2:14,m*T,replace=TRUE),m,T)Next, we generate the policy functions and assess them for which one is best.
#Generate random policy functions in a list
n_policies = 1000
policies = list()
for (j in 1:n_policies) {
pol = matrix(round(runif(13*T)),13,T)
pol[,T] = 1
policies[[j]] = pol
}We write a function that evaluates each policy for its expected value over all 10,000 games in the draws matrix.
#game is a row of 10 cards; policy is a 13x10 matrix
valueGP = function(game,policy) {
t = 0
for (card in game) {
t = t + 1
if (policy[card-1,t]==1) { break }
}
res = card
}
valueFN = function(draws,policy) {
v = rep(0,m)
for (j in 1:m) {
v[j] = valueGP(draws[j,],policy)
}
result = mean(v)
}We test all policies over all games.
value_functions = rep(0,n_policies)
for (j in 1:n_policies) {
value_functions[j] = valueFN(draws,policies[[j]])
}Find the policy with the highest value.
idx = which(value_functions==max(value_functions))
print(c("Value function for best policy = ",value_functions[idx]))
policies[[idx]][1] "Value function for best policy = " "10.1212"
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 0 0 0 0 0 1 0 0 1 1
[2,] 0 0 1 0 0 0 0 1 0 1
[3,] 0 0 1 0 1 1 1 1 1 1
[4,] 0 0 0 0 0 0 0 0 0 1
[5,] 0 0 0 1 0 0 0 0 0 1
[6,] 1 0 0 0 0 0 1 1 0 1
[7,] 1 0 0 1 0 0 1 0 1 1
[8,] 0 1 1 0 1 1 0 1 1 1
[9,] 1 0 1 0 1 0 1 0 1 1
[10,] 1 1 0 0 0 0 0 1 0 1
[11,] 0 0 1 1 1 1 0 1 1 1
[12,] 1 1 1 1 0 1 0 0 0 1
[13,] 1 0 1 1 1 0 1 0 1 1We can see that this is hardly an optimal policy, as the analytical solution has a value function of \(12.68361\). We can see that the policy grid is very different from the optimal one, which has 0s in the upper region and 1s in the lower region.
14.3 Policy Gradient Search
In this modeling approach we assess each point in the \(13 \times 10\) policy grid and determine if flipping the value improves the value function. In this way we hope to use gradient approach in a simple way. To start with we randomly generate policy matrix \(P\). We will work this by going down the columns of the policy matrix \(P\). Starting with the first element of the first column, holding all other cells of \(P\) constant, we evaluate the policy for both values of \(P(1,1) \in \{0,1\}\), and then we set it to be the value that returns the best value function. We then move on to trying both values of \(P(2,1)\) and again choose the best one. We proceed like this through all cells of the policy matrix. This completes one epoch, and generates a new policy matrix. We can repeat this process for as many epochs as we like, till the improvement in the value function is immaterially small.
#Randomly generate an initial policy function
pol = matrix(round(runif(13*T)),13,T)
pol[,T] = 1
v = valueFN(draws, pol) #Initial value function
for (epoch in 1:3) {
for (j in 1:(T-1)) {
for (i in 1:13) {
x = pol[i,j]
pol_new = pol
pol_new[i,j] = abs(x-1) #Flips the bit
v_new = valueFN(draws,pol_new)
if (v_new >= v) {
v = v_new
pol = pol_new
}
}
}
print(paste("Epoch",epoch,"value function = ",v))
}## [1] "Epoch 1 value function = 10.7533"
## [1] "Epoch 2 value function = 12.2858"
## [1] "Epoch 3 value function = 12.6539"This simple approach is run over three epochs, i.e., we adjust each of the policy function weights thrice, taking one weight gradient at a time. The final value function is very close to the optimal value from the analytical solution. The policy function is as follows.
pol## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
## [1,] 0 0 0 0 0 0 0 0 0 1
## [2,] 0 0 0 0 0 0 0 0 0 1
## [3,] 0 0 0 0 0 0 0 0 0 1
## [4,] 0 0 0 0 0 0 0 0 0 1
## [5,] 0 0 0 0 0 0 0 0 0 1
## [6,] 0 0 0 0 0 0 0 0 0 1
## [7,] 0 0 0 0 0 0 0 0 1 1
## [8,] 0 0 0 0 0 0 0 0 1 1
## [9,] 0 0 0 0 0 0 0 1 1 1
## [10,] 0 0 0 0 0 0 1 1 1 1
## [11,] 0 0 1 1 1 1 1 1 1 1
## [12,] 1 1 1 1 1 1 1 1 1 1
## [13,] 1 1 1 1 1 1 1 1 1 1It appears to be very close to the one generated analytically.
14.4 Q-Learning
Here is a Deep RL formulation of the problem that we discussed above. We will use a grid-based function to describe the relationship between the state, policy, and value function. (Later, we will use deep learning nets (DLNs) to approximate this function.) We determine the “state-action” function, also known as the \(Q(S,A)\) function, where \(S\) is the state, and \(A\) is the action (both possibly residing in high-dimension tensors). In our cards problem, state \(S=\{x,n\}\) and action \(A=\{0,1\}\). A didactic exposition follows. The function \(Q(S,A)\) stores the current best learned value of optimal action \(A\) at each state \(S\), and through iteration over simulated game play, it gets better and better. This is the essence of reinforcement \(Q\)-learning.
Useful References
- https://en.wikipedia.org/wiki/Markov_decision_process
- https://en.wikipedia.org/wiki/Q-learning
- https://en.wikipedia.org/wiki/Temporal_difference_learning
- https://en.wikipedia.org/wiki/State%E2%80%93action%E2%80%93reward%E2%80%93state%E2%80%93action
- http://mnemstudio.org/path-finding-q-learning-tutorial.htm
Our implementation will be in Python. We first establish some basic input parameters that we will need. We designate the vector “cards” to hold the value of each card, where recall that, aces equal 14. We define the number of periods \(N=10\) and the number of card values \(M=13\) as constants for our problem.
cards = [2,3,4,5,6,7,8,9,10,11,12,13,14] #2 to Ace
N = 10 # number of periods
M = 13 # cardsSince simulation will be used to solve the problem, we need to generate a set of \(N\) card draws, which constitutes one instance of a game. We use the randint function here.
#Function to return a set of sequential card draws with replacement
from random import randint
def onecard():
return randint(2,M+1)
def game(N):
game = [onecard() for j in range(N)]
return game
print(game(N))The output is a random set of \(N\) card values, drawn with replacement. Every time this code block is run, we will get a different set of \(N\) cards.
[5, 10, 6, 3, 9, 13, 13, 8, 5, 14]14.5 State-Action Reward and \(Q\) Tensors
We set up two matrices (tensors) for the \(Q(x,n;A)\) function and the reward function \(R(x,n;A)\). These are 3D matrices, one dimension for each of the arguments. The reward matrix is static and is set up once and never changed. This is because it is a one-step reward matrix between \((x,n;A)\) and \((x',n-1;A')\), with the reward in between. (\(x'\) and \(A'\) are the next period state and action, respectively.) It is often known as the SARSA structure, i.e., the state-action-reward-state-action algorithm.
We initialize the “reward” matrix which contains the reward in every possible state in the 3D tensor.
#Reward matrix (static)
#initialize
R = zeros((M,N,2)) #for cards, remaining draws, actions
#When the action is 0="continue" then leave the reward as zero
#When the action is 1="halt" then take card value
for j in range(13):
R[j,:,1] = j+2
R[:,N-1,0] = cards
#Check
RWe print out the result below, which is a rather long 2D rendition of the 3D tensor. The structure of the three dimensions is \([x, n, a]\), so that each tableau segment below is for one \(x\) (card value). The rows below are for each draw \(n\) and the columns are for each action \(a=\{0,1\}\). Note that for all \(n<N\), the reward value of action \(a=0\) is zero, as the player does not cash out. For all \(n<N\), the reward is \(x\), the card value. Only at \(n=N\) do we see that \(R(x,n;a)=x\), because you will take whatever you get in the final card draw (see that the entire last row in each tableau is \(x\)). The reward matrix remains fixed throughout the run of the algorithm.
array([[[ 0., 2.],
[ 0., 2.],
[ 0., 2.],
[ 0., 2.],
[ 0., 2.],
[ 0., 2.],
[ 0., 2.],
[ 0., 2.],
[ 0., 2.],
[ 2., 2.]],
[[ 0., 3.],
[ 0., 3.],
[ 0., 3.],
[ 0., 3.],
[ 0., 3.],
[ 0., 3.],
[ 0., 3.],
[ 0., 3.],
[ 0., 3.],
[ 3., 3.]],
[[ 0., 4.],
[ 0., 4.],
[ 0., 4.],
[ 0., 4.],
[ 0., 4.],
[ 0., 4.],
[ 0., 4.],
[ 0., 4.],
[ 0., 4.],
[ 4., 4.]],
[[ 0., 5.],
[ 0., 5.],
[ 0., 5.],
[ 0., 5.],
[ 0., 5.],
[ 0., 5.],
[ 0., 5.],
[ 0., 5.],
[ 0., 5.],
[ 5., 5.]],
[[ 0., 6.],
[ 0., 6.],
[ 0., 6.],
[ 0., 6.],
[ 0., 6.],
[ 0., 6.],
[ 0., 6.],
[ 0., 6.],
[ 0., 6.],
[ 6., 6.]],
[[ 0., 7.],
[ 0., 7.],
[ 0., 7.],
[ 0., 7.],
[ 0., 7.],
[ 0., 7.],
[ 0., 7.],
[ 0., 7.],
[ 0., 7.],
[ 7., 7.]],
[[ 0., 8.],
[ 0., 8.],
[ 0., 8.],
[ 0., 8.],
[ 0., 8.],
[ 0., 8.],
[ 0., 8.],
[ 0., 8.],
[ 0., 8.],
[ 8., 8.]],
[[ 0., 9.],
[ 0., 9.],
[ 0., 9.],
[ 0., 9.],
[ 0., 9.],
[ 0., 9.],
[ 0., 9.],
[ 0., 9.],
[ 0., 9.],
[ 9., 9.]],
[[ 0., 10.],
[ 0., 10.],
[ 0., 10.],
[ 0., 10.],
[ 0., 10.],
[ 0., 10.],
[ 0., 10.],
[ 0., 10.],
[ 0., 10.],
[10., 10.]],
[[ 0., 11.],
[ 0., 11.],
[ 0., 11.],
[ 0., 11.],
[ 0., 11.],
[ 0., 11.],
[ 0., 11.],
[ 0., 11.],
[ 0., 11.],
[11., 11.]],
[[ 0., 12.],
[ 0., 12.],
[ 0., 12.],
[ 0., 12.],
[ 0., 12.],
[ 0., 12.],
[ 0., 12.],
[ 0., 12.],
[ 0., 12.],
[12., 12.]],
[[ 0., 13.],
[ 0., 13.],
[ 0., 13.],
[ 0., 13.],
[ 0., 13.],
[ 0., 13.],
[ 0., 13.],
[ 0., 13.],
[ 0., 13.],
[13., 13.]],
[[ 0., 14.],
[ 0., 14.],
[ 0., 14.],
[ 0., 14.],
[ 0., 14.],
[ 0., 14.],
[ 0., 14.],
[ 0., 14.],
[ 0., 14.],
[14., 14.]]])Our reinforcement algorithm learns \(Q(x,n;a)\) by playing the game over and over, refining the \(Q\)-tensor through one epoch after another. The algorithm is described below.
- System State: \((x, n)\), where \(x\) is the number of the card drawn at random, \(n\) is the number of steps to go. For example \(n = 10\) at the start of experiment, and the experiment stops when \(n = 0\).
- Iteration (below) is used to compute \(Q(x,n; A)\), where \(A\) is the action and can take on take values of (i) \(A = 0\), i.e., continue the experiment and transition to the next state \((x', n-1)\), with a reward = \(0\); (ii) \(A = 1\), i.e., stop the experiment, reward = \(x\).
- Initialize the \(Q\)-tensor to some initial values (\(=0\)), initialize to some state \((x, n)\), and repeat the following steps in a loop until remaining draws \(n = 0\):
- Compute \(Q(x,n;0)\) and \(Q(x,n;1)\).
- If \(Q(x,n, 0) > Q(x, n, 1)\), then choose Action 0, otherwise choose Action 1.
- If the Action chosen is 0, then transition to next state \((x',n-1)\), where \(x'\) is chosen using a transition probability model. In the cards case, this probability is uniform across all states.
- Compute \(Q(x',n-1,0)\) and \(Q(x',n-1,1)\) using the DLN. Choose the next Action \(A'\) depending upon which of these is larger.
- Update the \(Q\) value of the original state using
- \(Q(x,n,0) \leftarrow Q(x,n,0) + \alpha[0 + \gamma Q(x',n-1,A')-Q(x,n,0)]\)
- \(Q(x,n,1) \leftarrow (1-\alpha) Q(x,n,1) + \alpha x\)
- \(\gamma \leq 1\).
- If \(A = 1\) or \(n = 0\), then re-initialize to some random \(x\) and go back to step 1. Otherwise set \(x \leftarrow x'\) and \(A \leftarrow A'\) and go back to step 1.
Learning rate \(\alpha\) is a hyperparameter, we start by setting it to 0.1. Also \(\gamma\) is the discount factor in the reward function.
In the following code, we develop the \(Q\)-function via Monte Carlo simulation. The function below contains the logic for executing one card draw, and the learning procedure therefrom. Given the state \(S=\{x,n\}\), the action \(A=\{0,1\}\) is drawn at random with equal probability to generate the reward \(R\) and also generate the next state \(S'=\{x',n+1\}\). We then consider the reward from optimal action \(A'\) next period. This reward will be the better of the two possible \(Q\) values next period, i.e., \(\max[Q(x',n+1;A=0), Q(x',n+1;A=1)]\). The functional form is as follows when \(A=0\), i.e., when the action is to hold on for another draw.
\[\begin{equation} Q(x,n;A=0) = Q(x,n;A=0) + R(x,n;A=0) \\ \quad + \gamma \cdot \max[Q(x',n+1;A'=0), Q(x',n+1;A'=1)], \tag{14.1} \\ \quad \quad \quad \quad \mbox{if } A=0 \end{equation}\]The current “quality” function \(Q\) is equal to current reward plus the discounted optimized reward in the following period, based on the conditional randomized state \((x',n+1 | x,n)\) chosen in the following period. Notice that \(\gamma\) here is the discount rate. The equation (14.1) above leads to constantly increasing values in the \(Q\) tensor, and to normalize the values to be stable, the equation above is updated instead as follows.
\[ \begin{equation} Q(x,n;A=0) = (1-\alpha) Q(x,n;A=0) + \alpha \left[ R(x,n;A=0) \\ + \gamma \cdot \max[Q(x',n+1;A'=0), Q(x',n+1;A'=1)] \right] \end{equation} \]
Here, \(\alpha\) is the “learning rate” of \(Q\)-learning. Notice that we can further rewrite the equation above as
\[ \begin{equation} Q(x,n;A=0) = Q(x,n;A=0) + \alpha \left[ R(x,n;A=0) \\ + \gamma \cdot \max[Q(x',n+1;A'=0), Q(x',n+1;A'=1)] \\ - Q(x,n;A=0) \right] \end{equation} \]
The analogous equation to this is used when action \(A'=1\) and the game terminates and the reward is collected.
\[ Q(x,n;A=1) = (1-\alpha) Q(x,n;A=1) + \alpha R(x,n;A=0) \]
All these functions are embedded in the code below.
def doOneDraw(x0,n0): #assumes that n0<10
#now, given x0,n0
a0 = randint(0,1) #index of action
#next
x1 = randint(0,M-1) #next state
Q[x0,n0,0] = Q[x0,n0,0] + alpha*(R[x0,n0,0] +
gamma*max(Q[x1,n0+1,0],Q[x1,n0+1,1]) - Q[x0,n0,0])
Q[x0,n0,1] = (1-alpha)*Q[x0,n0,1] + alpha*R[x0,n0,1]
if a0==0:
return [x1,n0+1] #draw another card
else:
return [x0,N] #terminate and take value of current cardThis function is then called repeatedly to complete one game, which is called an “epoch”. The function that does one epoch is below.
def doOneGame(x):
n = 0
while n<(N-1):
[x,n] = doOneDraw(x,n)
if n==(N-1):
Q[x,n,0] = (1-alpha)*Q[x,n,0] + alpha*R[x,n,0] #in both actions it is the end
Q[x,n,1] = (1-alpha)*Q[x,n,1] + alpha*R[x,n,1]Now we can initialize the \(Q\) matrix and \(\alpha, \gamma\).
#State-Action Value function
#Q-matrix
Q = zeros((M,N,2))
alpha = 0.25 #Learning rate
gamma = 1.00 #Discount rateFinally, we run the entire algorithm for a large number of epochs.
%%time
#Run the epochs
epochs = 100000
Qdiff = zeros(epochs)
for j in range(epochs):
Q0 = copy(Q)
x = randint(0,M-1)
doOneGame(x)
Qdiff[j] = sum(((Q - Q0))**2)The run time is a few seconds.
CPU times: user 2.21 s, sys: 55.9 ms, total: 2.27 s
Wall time: 2.23 s14.5.1 Convergence
Above the squared pointwise difference between successive tensors is computed by taking the following sum, noting that each scalar value of \(Q\) comes from a 3D tensor:
\[ \mbox{Qdiff}_t = \sum_t \left[Q_t - Q_{t-1}\right]^2 \]
This is an oscillating sequence, that trends lower and lower to convergence. To smooth out the oscillations we take the moving average over 1% of the sequence at a time. See next.
#Plot the Qdiff to see if it declines
window = int(epochs*0.01)
qd = pd.Series(Qdiff)
y = qd.rolling(window).mean()
figure(figsize=(15,5))
plot(range(len(y)-window),y[window:],label='Moving window size: '+str(window))
grid()
xlabel("Epoch number")
ylabel("Squared difference between Q tensors")
# See previous block for error computation plotted here
title("Moving average squared difference between successive Q tensors")
legend()The convergence is shown in Figure 14.1.
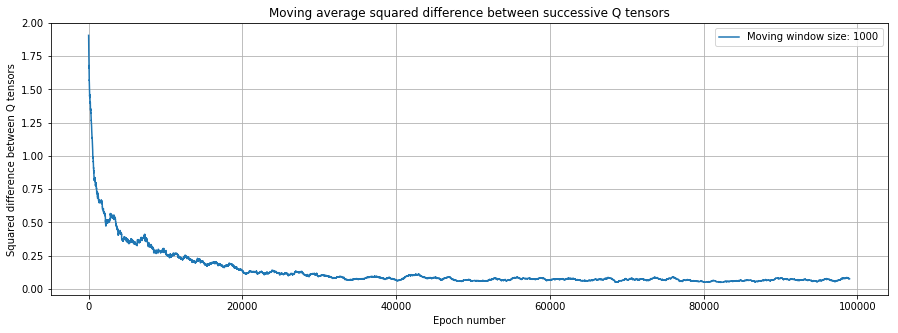
Figure 14.1: Convergence of the \(Q\)-learning algorithm
It is also useful to examine the \(Q\) tensor after the algorithm has converged. We examine one slice of the tensor here, for \(n=4\).
#Let's see what it shows for n=4
#The two columns are for A=0 and A=1, rows being card values
Q[:,4,:]
array([[ 11.17853005, 2. ],
[ 11.34889817, 3. ],
[ 11.89818914, 4. ],
[ 11.79211996, 5. ],
[ 10.95936298, 6. ],
[ 11.45246374, 7. ],
[ 10.9329109 , 8. ],
[ 11.34584907, 9. ],
[ 11.34088954, 10. ],
[ 11.47523658, 11. ],
[ 11.28113426, 12. ],
[ 11.13122788, 13. ],
[ 11.30127529, 14. ]])If you examine the grid above it is of dimension \(13 \times 2\) and is the value of \(Q(x,4,A)\) for all values of \(x,A\) at time \(n=4\). This is a 2D slice of the 3D tensor for \(Q(x,n,A)\), the state-action value function. It tells us that the optimal action is 1 if the second column is bigger than the first, else action is 0. Clearly it is more optimal to stop at higher card values because the value in column 2 (where A=1) is much higher than in column 1 (where A=0).
14.5.2 Compute the optimal policy grid from the Q grid
We can use the \(Q\) tensor to generate the optimal policy function based on whether \(A=0\) or \(A=1\) is optimal.
P = zeros((M,N))
P[:,N-1] = 1
for i in range(M):
for j in range(N):
if Q[i,j,1] > Q[i,j,0]:
P[i,j] = 1
print(P)Here is the policy grid for all states \((x,n)\).
[[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[ 0. 0. 0. 0. 0. 0. 0. 1. 1. 1.]
[ 0. 0. 0. 0. 0. 0. 0. 1. 1. 1.]
[ 0. 0. 0. 0. 0. 1. 0. 1. 1. 1.]
[ 0. 0. 1. 1. 1. 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[ 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]]We see that this is not the exact optimal \(P\) grid that we get from exact dynamic programming. So it is suboptimal. But we can assess the value function from this \(P\) grid by running samples below.
The optimal policy grid from dynamic programming was computed above, where the optimal value function is \(12.68\).
14.5.3 Compute expected value function for random sets
We now calculate the value of the optimal policy from \(Q\)-learning.
Generate 10,000 sets of 10 random card draws, and then execute the strategy in the policy grid above and compute the expected value across all 10,000 sets to get the expected value function. The following code calculates the expected value of implementing the \(Q\)-learning optimal policy on the random set of games.
def Vfunction(N):
cards = game(N)
for n in range(N):
if P[cards[n]-2,n]==1:
return cards[n]The following code generates 10,000 games with \(N\) card draws each. And then computes the expectd value function across all games.
nsets = 10000
V = zeros(nsets)
for i in range(nsets):
V[i] = Vfunction(N)
hist(V,100)
grid()
xlabel('Outcome of the game')
ylabel('Frequency')
title('Histogram of 10,000 game outcomes')
print("Expected Value Function E[V(S)] = ",mean(V))The output is:
Expected Value Function E[V(S)] = 12.6527We plot the distribution of game outcomes for all games in Figure 14.2.
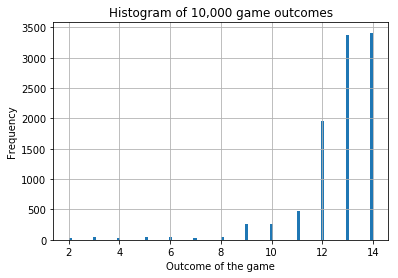
Figure 14.2: Distribution of game outcomes from the optimal \(Q\)-learning algorithm
The value function is close to the analytical solution from dynamic programming, i.e., 12.68.
We also note that the solution worsens when we use \(\gamma < 1\) because the problem is then different from the one originally solved where we did not treat outcomes at different times differently. So we set \(\gamma=1\).
What about the \(\alpha\) parameter? It seems to be working well at \(\alpha=0.25\).
14.6 Q-learning with Deep Learning Nets
Using DLNs makes sense only when the size of the state space or the action space is so large, that the usual dynamic programming (DP) procedure cannot be applied. We note also that in RL, unlike in DP, no backward recursion is necessary. Only forward simulation is applied.
References
Mnih, V., K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller. 2013. “Playing Atari with Deep Reinforcement Learning.” ArXiv E-Prints, December. http://adsabs.harvard.edu/abs/2013arXiv1312.5602M.
Silver, David, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, et al. 2016. “Mastering the Game of Go with Deep Neural Networks and Tree Search.” Nature 529 (7587). Nature Publishing Group: 484–89. doi:10.1038/nature16961.
Sutton, Richard S., and Andrew G. Barto. 1998. Reinforcement Learning: An Introduction. MIT Press. http://www.cs.ualberta.ca/~sutton/book/the-book.html.
Sugiyama, Masashi, Hirotaka Hachiya, and Tetsuro Morimura. 2013. Statistical Reinforcement Learning: Modern Machine Learning Approaches. 1st ed. Chapman & Hall/CRC.
Moody, John E., and Matthew Saffell. 2001. “Learning to Trade via Direct Reinforcement.” IEEE Transactions on Neural Networks 12 (4): 875–89.
Dempster, M. A. H., and V. Leemans. 2006. “An Automated Fx Trading System Using Adaptive Reinforcement Learning.” Expert Syst. Appl. 30 (3). Tarrytown, NY, USA: Pergamon Press, Inc.: 543–52. doi:10.1016/j.eswa.2005.10.012.
Corazza, Marco, and Francesco Bertoluzzo. 2014. “Q-Learning-Based Financial Trading Systems with Applications.” University Ca’ Foscari of Venice, Dept. of Economics Working Paper Series No. 15/WP/2014. http://dx.doi.org/10.2139/ssrn.2507826.
Duarte, Victor. 2017. “Macro, Finance, and Macro Finance: Solving Nonlinear Models in Continuous Time with Machine Learning.” Working Paper, MIT.
Jiang, Z., D. Xu, and J. Liang. 2017. “A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem.” ArXiv E-Prints, June. http://adsabs.harvard.edu/abs/2017arXiv170610059J.
Bellman, Richard. 1957. Dynamic Programming. Princeton University Press, Princeton, NJ.
Howard, Ronald A. 1966. “Dynamic Programming.” Management Science 12 (5): 317–48. doi:10.1287/mnsc.12.5.317.