Chapter 2 Got Math? The Very Beginning
Business analytics requires the use of various quantitative tools, from algebra and calculus, to statistics and econometrics, with implementations in various programming languages and software. It calls for technical expertise as well as good judgment, and the ability to ask insightful questions and to deploy data towards answering the questions.
The presence of the web as the primary platform for business and marketing has spawned huge quantities of data, driving firms to attempt to exploit vast stores of information in honing their competitive edge. As a consequence, firms in Silicon Valley (and elsewhere) are hiring a new breed of employee known as “data scientist” whose role is to analyze “Big Data” using tools such as the ones you will learn in this course.
This chapter will review some of the mathematics, statistics, linear algebra, and calculus you might have not used in many years. It is more fun than it looks. We will also learn to use some mathematical packages along the way. We’ll revisit some standard calculations and analyses that you will have encountered in previous courses you might have taken. You will refresh some old concepts, learn new ones, and become technically adept with the tools of the trade.
2.1 Logarithms and Exponentials, Continuous Compounding
It is fitting to begin with the fundamental mathematical constant, \(e = 2.718281828...\), which is also the function \(\exp(\cdot)\). We often write this function as \(e^x\), where \(x\) can be a real or complex variable. It shows up in many places, especially in Finance, where it is used for continuous compounding and discounting of money at a given interest rate \(r\) over some time horizon \(t\).
Given \(y=e^x\), a fixed change in \(x\) results in the same continuous percentage change in \(y\). This is because \(\ln(y) = x\), where \(\ln(\cdot)\) is the natural logarithm function, and is the inverse function of the exponential function. Recall also that the first derivative of this function is \(\frac{dy}{dx} = e^x\), i.e., the function itself.
The constant \(e\) is defined as the limit of a specific function:
\[ e = \lim_{n \rightarrow \infty} \left( 1 + \frac{1}{n} \right)^n \]
Exponential compounding is the limit of successively shorter intervals over discrete compounding.
x = c(1,2,3)
y = exp(x)
print(y)## [1] 2.718282 7.389056 20.085537print(log(y))## [1] 1 2 32.2 Calculus
EXAMPLE: Bond Mathematics
Given a horizon \(t\) divided into \(n\) intervals per year, one dollar compounded from time zero to time \(t\) years over these \(n\) intervals at per annum rate \(r\) may be written as \(\left(1 + \frac{r}{n} \right)^{nt}\). Continuous-compounding is the limit of this equation when the number of periods \(n\) goes to infinity:
\[ \lim_{n \rightarrow \infty} \left(1 + \frac{r}{n} \right)^{nt} = \lim_{n \rightarrow \infty} \left[ \left(1 + \frac{1}{n/r} \right)^{n/r}\right]^{tr} = e^{rt} \]
This is the forward value of one dollar. Present value is just the reverse. Therefore, the price today of a dollar received \(t\) years from today is \(P = e^{-rt}\). The yield of a bond is:
\[ r = -\frac{1}{t} \ln(P) \]
In bond mathematics, the negative of the percentage price sensitivity of a bond to changes in interest rates is known as “Duration”:
\[ -\frac{dP}{dr}\frac{1}{P} = -\left(-t e^{-rt}\frac{1}{P}\right) = t P\frac{1}{P} = t \]
The derivative \(\frac{dP}{dr}\) is the price sensitivity of the bond to changes in interest rates, and is negative. Further dividing this by \(P\) gives the percentage price sensitivity. The minus sign in front of the definition of duration is applied to convert the negative number to a positive one.
The “Convexity” of a bond is its percentage price sensitivity relative to the second derivative, i.e.,
\[ \frac{d^2P}{dr^2}\frac{1}{P} = t^2 P\frac{1}{P} = t^2 \]
Because the second derivative is positive, we know that the bond pricing function is convex.
2.3 Normal Distribution
This distribution is the workhorse of many models in the social sciences, and is assumed to generate much of the data that comprises the Big Data universe. Interestingly, most phenomena (variables) in the real world are not normally distributed. They tend to be “power law” distributed, i.e., many observations of low value, and very few of high value. The probability distribution declines from left to right and does not have the characteristic hump shape of the normal distribution. An example of data that is distributed thus is income distribution (many people with low income, very few with high income). Other examples are word frequencies in languages, population sizes of cities, number of connections of people in a social network, etc.
Still, we do need to learn about the normal distribution because it is important in statistics, and the central limit theorem does govern much of the data we look at. Examples of approximately normally distributed data are stock returns, and human heights.
If \(x \sim N(\mu,\sigma^2)\), that is, \(x\) is normally distributed with mean \(\mu\) and variance \(\sigma^2\), then the probability “density” function for \(x\) is:
\[ f(x) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left[-\frac{1}{2}\frac{(x-\mu)^2}{\sigma^2} \right] \]
The cumulative probability is given by the “distribution” function
\[ F(x) = \int_{-\infty}^x f(u) du \]
and
\[ F(x) = 1 - F(-x) \]
because the normal distribution is symmetric. We often also use the notation \(N(\cdot)\) or \(\Phi(\cdot)\) instead of \(F(\cdot)\).
The “standard normal” distribution is: \(x \sim N(0,1)\). For the standard normal distribution: \(F(0) = \frac{1}{2}\). The normal distribution has continuous support, i.e., a range of values of \(x\) that goes continuously from \(-\infty\) to \(+\infty\).
#DENSITY FUNCTION
x = seq(-4,4,0.001)
plot(x,dnorm(x),type="l",col="red")
grid(lwd=2)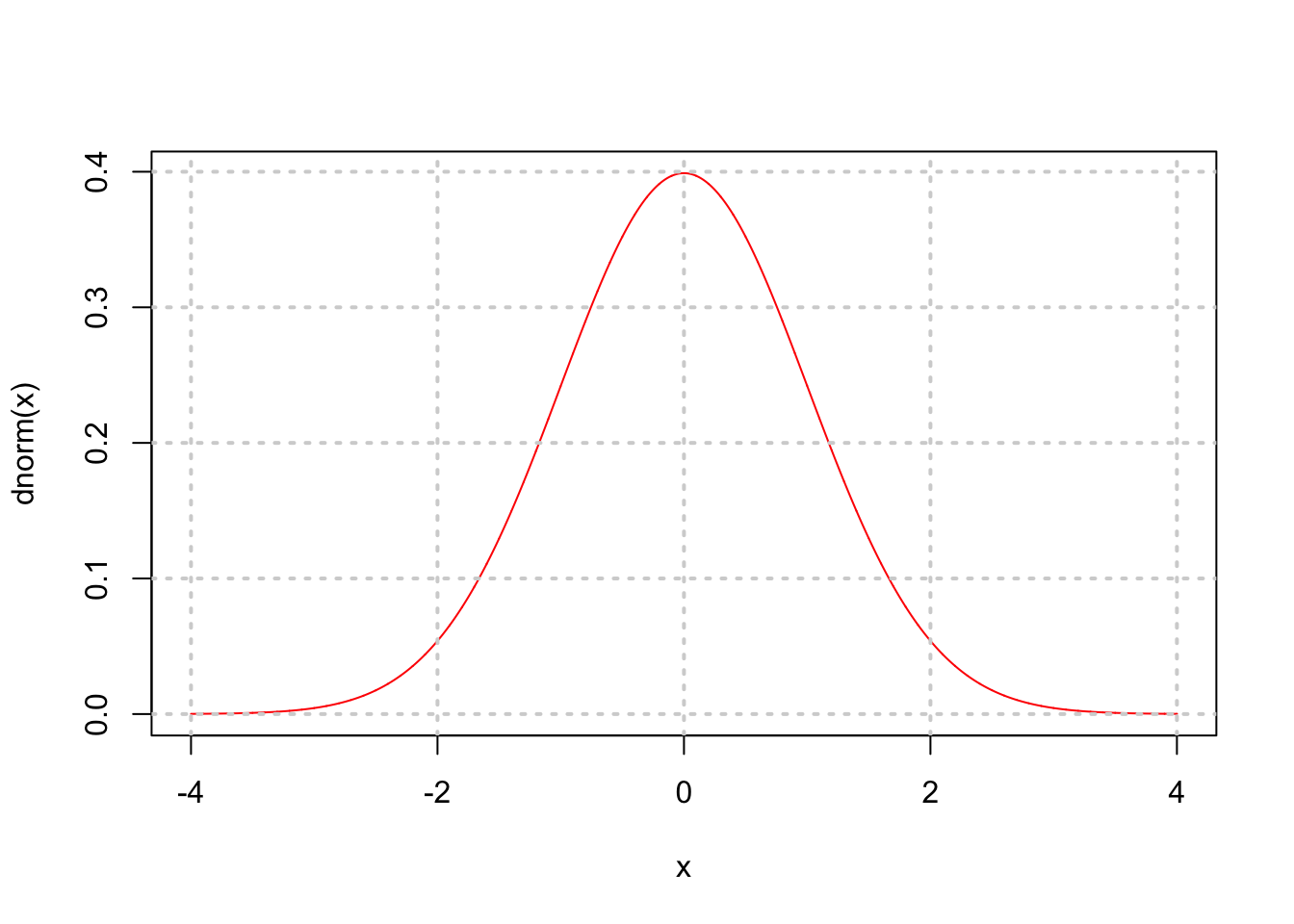
print(dnorm(0))## [1] 0.3989423fx = dnorm(x)
Fx = pnorm(x)
plot(x,Fx,type="l",col="blue",main="Normal Probability",ylab="f(x) and F(x)")
lines(x,fx,col="red")
grid(col="green",lwd=2)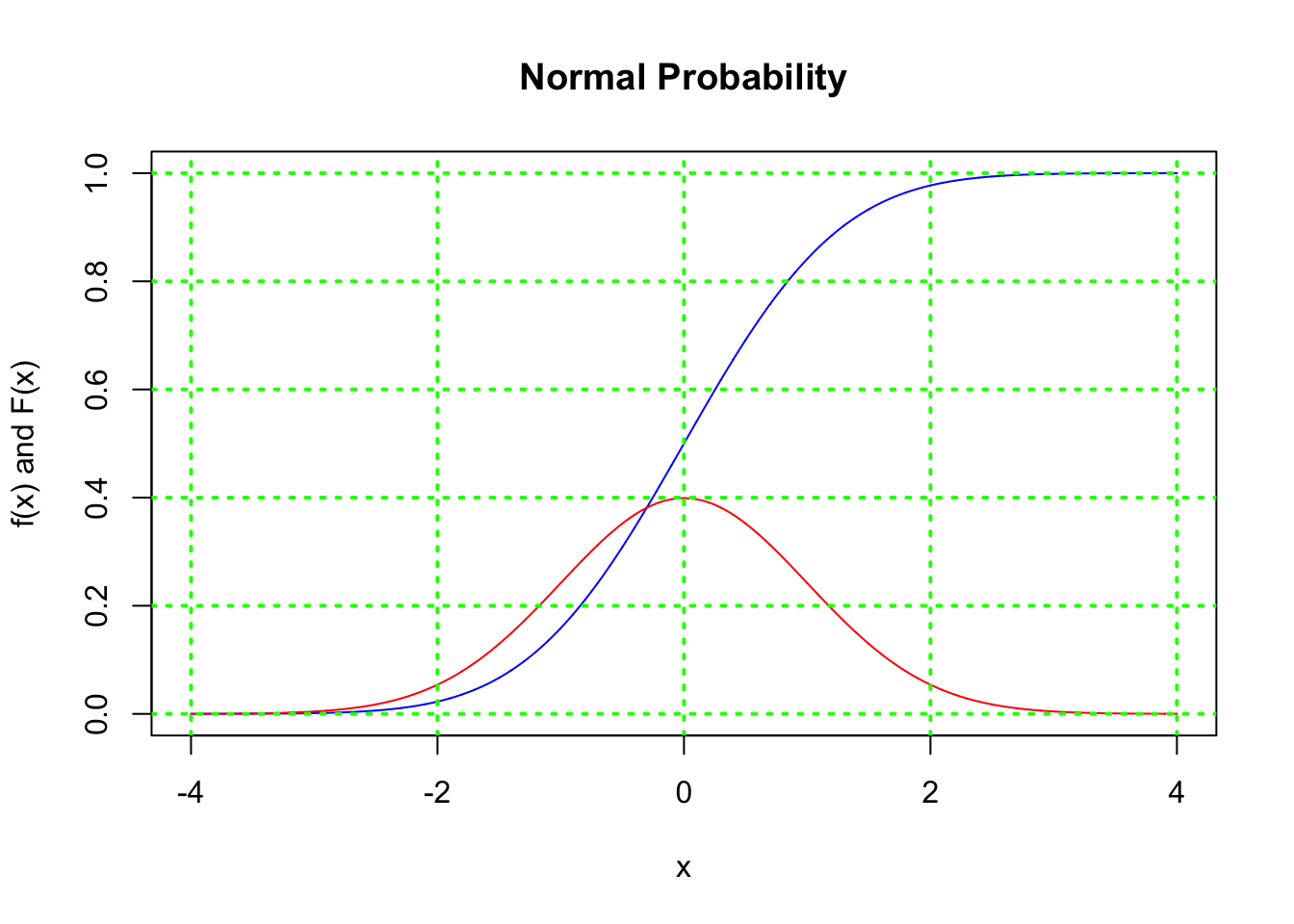
res = c(pnorm(-6),pnorm(0),pnorm(6))
print(round(res,6))## [1] 0.0 0.5 1.02.4 Poisson Distribution
The Poisson is also known as the rare-event distribution. Its density function is:
\[ f(n; \lambda) = \frac{e^{-\lambda} \lambda^n}{n!} \]
where there is only one parameter, i.e., the mean \(\lambda\). The density function is over discrete values of \(n\), the number of occurrences given the mean number of outcomes \(\lambda\). The mean and variance of the Poisson distribution are both \(\lambda\). The Poisson is a discrete-support distribution, with a range of values \(n=\{0,1,2, \ldots\}\).
x = seq(0,25)
lambda = 4
fx = dpois(x,lambda)
barplot(fx,names.arg=x)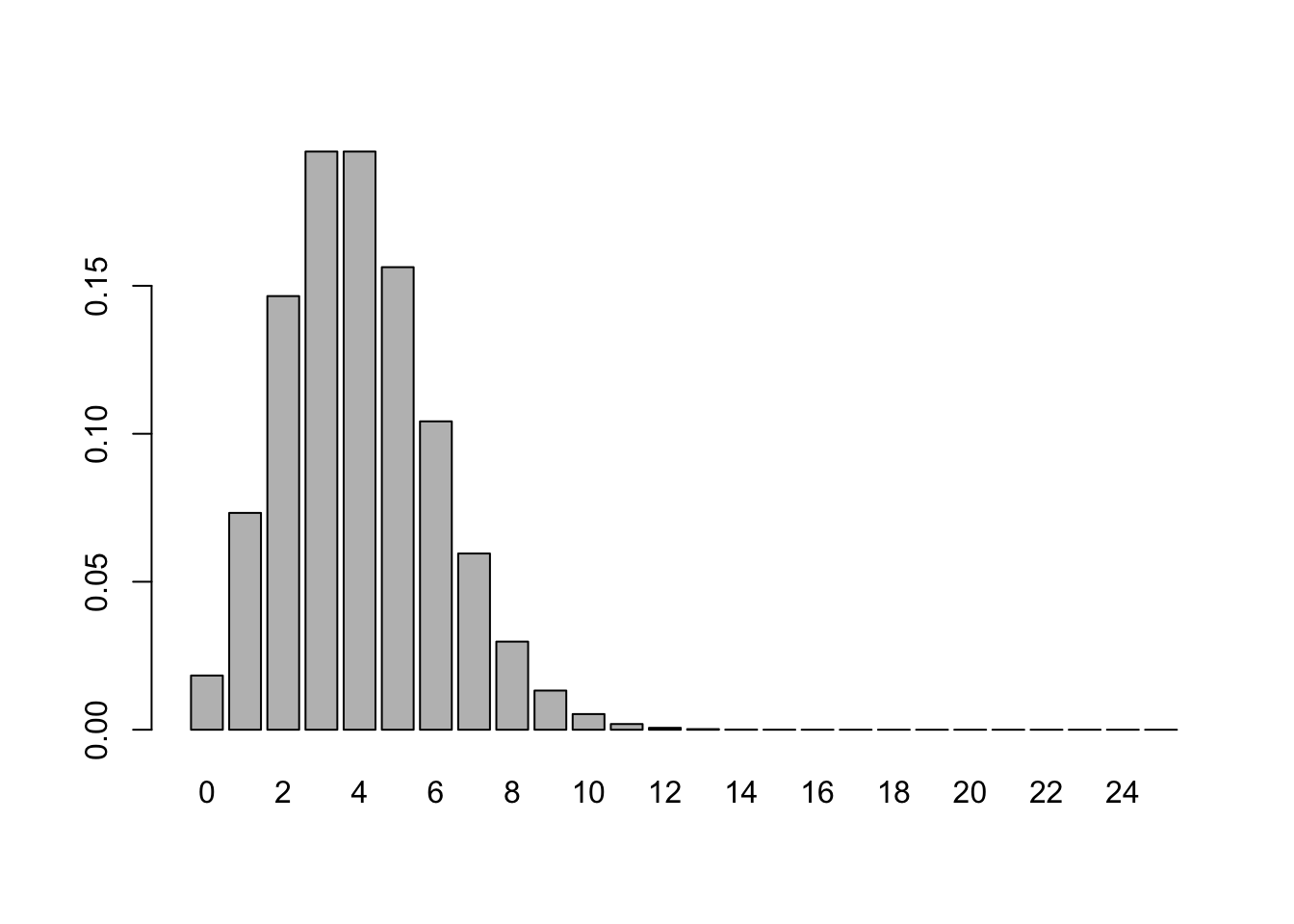
print(sum(fx))## [1] 1#Check that the mean is lambda
print(sum(x*fx))## [1] 4#Check that the variance is lambda
print(sum(x^2*fx)-sum(x*fx)^2)## [1] 4There are of course, many other probability distributions. Figure 2.1 displays them succinctly.
Figure 2.1: Probability Distributions
2.5 Moments of Random Variables
The following formulae are useful to review because any analysis of data begins with descriptive statistics, and the following statistical “moments” are computed in order to get a first handle on the data. Given a random variable \(x\) with probability density function \(f(x)\), then the following are the first four moments.
\[ \mbox{Mean (first moment or average)} = E(x) = \int x f(x) dx \]
In like fashion, powers of the variable result in higher (\(n\)-th order) moments. These are “non-central” moments, i.e., they are moments of the raw random variable \(x\), not its deviation from its mean, i.e., \([x - E(x)]\).
\[ n^{th} \mbox{ moment} = E(x^n) = \int x^n f(x) dx \]
Central moments are moments of de-meaned random variables. The second central moment is the variance:
\[ \mbox{Variance } = Var(x) = E[x-E(x)]^2 = E(x^2) - [E(x)]^2 \]
The standard deviation is the square-root of the variance, i.e., \(\sigma = \sqrt{Var(x)}\).
The third central moment, normalized by the standard deviation to a suitable power is the skewness:
\[ \mbox{Skewness } = \frac{E[x-E(x)]^3}{Var(x)^{3/2}} \]
The absolute value of skewness relates to the degree of asymmetry in the probability density. If more extreme values occur to the left than the right, the distribution is left-skewed. And vice-versa, the distribution is right-skewed.
Correspondingly, the fourth central, normalized moment is kurtosis.
\[ \mbox{Kurtosis } = \frac{E[x-E(x)]^4}{[Var(x)]^2} \]
Kurtosis in the normal distribution has value \(3\). We define “Excess Kurtosis” to be Kurtosis minus 3. When a probability distribution has positive excess kurtosis we call it “leptokurtic”. Such distributions have fatter tails (either or both sides) than a normal distribution.
#EXAMPLES
dx = 0.001
x = seq(-5,5,dx)
fx = dnorm(x)
mn = sum(x*fx*dx)
print(c("Mean=",mn))## [1] "Mean=" "3.20341408642798e-19"vr = sum(x^2*fx*dx)-mn^2
print(c("Variance=",vr))## [1] "Variance=" "0.999984596641201"sk = sum((x-mn)^3*fx*dx)/vr^(3/2)
print(c("Skewness=",sk))## [1] "Skewness=" "4.09311659106139e-19"kt = sum((x-mn)^4*fx*dx)/vr^2
print(c("Kurtosis=",kt))## [1] "Kurtosis=" "2.99967533661497"2.6 Combining Random Variables
Since we often have to deal with composites of random variables, i.e., more than one random variable, we review here some simple rules for moments of combinations of random variables. There are several other expressions for the same equations, but we examine just a few here, as these are the ones we will use more frequently.
First, we see that means are additive and scalable, i.e.,
\[ E(ax + by) = a E(x) + b E(y) \]
where \(x, y\) are random variables, and \(a, b\) are scalar constants. The variance of scaled, summed random variables is as follows:
\[ Var(ax + by) = a^2 Var(x) + b^2 Var(y) + 2ab Cov(x,y) \]
And the covariance and correlation between two random variables is
\[ Cov(x,y) = E(xy) - E(x)E(y) \]
\[ Corr(x,y) = \frac{Cov(x,y)}{\sqrt{Var(x)Var(y)}} \]
Students of finance will be well-versed with these expressions. They are facile and easy to implement.
#CHECK MEAN
x = rnorm(1000)
y = runif(1000)
a = 3; b = 5
print(c(mean(a*x+b*y),a*mean(x)+b*mean(y)))## [1] 2.488377 2.488377#CHECK VARIANCE
vr = var(a*x+b*y)
vr2 = a^2*var(x) + b^2*var(y) + 2*a*b*cov(x,y)
print(c(vr,vr2))## [1] 11.03522 11.03522#CHECK COVARIANCE FORMULA
cv = cov(x,y)
cv2 = mean(x*y)-mean(x)*mean(y)
print(c(cv,cv2))## [1] 0.0008330452 0.0008322121corr = cov(x,y)/(sd(x)*sd(y))
print(corr)## [1] 0.002889551print(cor(x,y))## [1] 0.0028895512.7 Vector Algebra
We will be using linear algebra in many of the models that we explore in this book. Linear algebra requires the manipulation of vectors and matrices. We will also use vector calculus. Vector algebra and calculus are very powerful methods for tackling problems that involve solutions in spaces of several variables, i.e., in high dimension. The parsimony of using vector notation will become apparent as we proceed. This introduction is very light and meant for the reader who is mostly uninitiated in linear algebra.
Rather than work with an abstract exposition, it is better to introduce ideas using an example. We’ll examine the use of vectors in the context of stock portfolios. We define the returns for each stock in a portfolio as:
\[ {\bf R} = \left(\begin{array}{c} R_1 \\ R_2 \\ : \\ : \\ R_N \end{array} \right) \]
This is a random vector, because each return \(R_i, i = 1,2, \ldots, N\) comes from its own distribution, and the returns of all these stocks are correlated. This random vector’s probability is represented as a joint or multivariate probability distribution. Note that we use a bold font to denote the vector \({\bf R}\).
We also define a Unit vector:
\[ {\bf 1} = \left(\begin{array}{c} 1 \\ 1 \\ : \\ : \\ 1 \end{array} \right) \]
The use of this unit vector will become apparent shortly, but it will be used in myriad ways and is a useful analytical object.
A portfolio vector is defined as a set of portfolio weights, i.e., the fraction of the portfolio that is invested in each stock:
\[ {\bf w} = \left(\begin{array}{c} w_1 \\ w_2 \\ : \\ : \\ w_N \end{array} \right) \]
The total of portfolio weights must add up to 1.
\[ \sum_{i=1}^N w_i = 1, \;\;\; {\bf w}'{\bf 1} = 1 \]
Pay special attention to the line above. In it, there are two ways in which to describe the sum of portfolio weights. The first one uses summation notation, and the second one uses a simple vector algebraic statement, i.e., that the transpose of \({\bf w}\), denoted \({\bf w'}\) times the unit vector \({\bf 1}\) equals 1.27 The two elements on the left-hand-side of the equation are vectors, and the 1 on the right hand side is a scalar. The dimension of \({\bf w'}\) is \((1 \times N)\) and the dimension of \({\bf 1}\) is \((N \times 1)\). And a \((1 \times N)\) vector multiplied by a \((N \times 1)\) results in a \((1 \times 1)\) vector, i.e., a scalar.
We may also invest in a risk free asset (denoted as asset zero, \(i=0\)), with return \(R_0 = r_f\). In this case, the total portfolio weights including that of the risk free asset must sum to 1, and the weight \(w_0\) is:
\[ w_0 = 1 - \sum_{i=1}^N w_i = 1 - {\bf w}^\top {\bf 1} \]
Now we can use vector notation to compute statistics and quantities of the portfolio. The portfolio return is
\[ R_p = \sum_{i=1}^N w_i R_i = {\bf w}' {\bf R} \]
Again, note that the left-hand-side quantity is a scalar, and the two right-hand-side quantities are vectors. Since \({\bf R}\) is a random vector, \(R_p\) is a random (scalar, i.e., not a vector, of dimension \(1 \times 1\)) variable. Such a product is called a scalar product of two vectors. In order for the calculation to work, the two vectors or matrices must be “conformable”, i.e., the inner dimensions of the matrices must be the same. In this case we are multiplying \({\bf w}'\) of dimension \(1 \times N\) with \({\bf R}\) of dimension \(N \times 1\) and since the two “inside” dimensions are both \(n\), the calculation is proper as the matrices are conformable. The result of the calculation will take the size of the “outer” dimensions, i.e., in this case \(1 \times 1\). Now, suppose
\[ {\bf R} \sim MVN[{\boldsymbol \mu}; {\bf \Sigma}] \]
That is, returns are multivariate normally distributed with mean vector \(E[{\bf R}] = {\boldsymbol \mu} = [\mu_1,\mu_2,\ldots,\mu_N]' \in R^N\) and covariance matrix \({\bf \Sigma} \in R^{N \times N}\). The notation \(R^N\) stands for a ``real-valued matrix of dimension \(N\).’’ If it’s just \(N\), then it means a vector of dimension \(N\). If it’s written as \(N \times M\), then it’s a matrix of that dimension, i.e., \(N\) rows and \(M\) columns.
We can write the portfolio’s mean return as:
\[ E[{\bf w}' {\bf R}] = {\bf w}' E[{\bf R}] = {\bf w}'{\boldsymbol \mu} = \sum_{i=1}^N w_i \mu_i \]
The portfolio’s return variance is
\[ Var(R_p) = Var({\bf w}'{\bf R}) = {\bf w}'{\bf \Sigma}{\bf w} \]
Showing why this is true is left as an exercise to the reader. Take a case where \(N=2\) and write out the expression for the variance of the portfolio using equation . Then also undertake the same calculation using the variance formula \({\bf w' \Sigma w}\) and see the equivalence. Also note carefully that this expression works because \({\bf \Sigma}\) is a symmetric matrix. The multivariate normal density function is:
\[ f({\bf R}) = \frac{1}{2\pi^{N/2}\sqrt{|\Sigma|}} \exp\left[-\frac{1}{2} \boldsymbol{(R-\mu)'\Sigma^{-1}(R-\mu)} \right] \]
Now, we take a look at some simple applications expressed in terms of vector notation.
2.8 Basic Regression Model (OLS)
We assume here that you are conversant with a linear regression and how to interpret the outputs of the regression. This subsection only serves to demonstrate how to run the simple ordinary least squares (OLS) regression in R. We create some random data and then find the relation between \(Y\) (the dependent variable) and \(X\) (the independent variable).
#STATISTICAL REGRESSION
x = rnorm(1000)
y = 3 + 4*x + 0.5*x^2 + rt(1000,5)
res = lm(y~x)
print(summary(res))##
## Call:
## lm(formula = y ~ x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.0031 -0.9200 -0.0879 0.7987 10.2941
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.53187 0.04591 76.94 <2e-16 ***
## x 3.91528 0.04634 84.49 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.451 on 998 degrees of freedom
## Multiple R-squared: 0.8774, Adjusted R-squared: 0.8772
## F-statistic: 7139 on 1 and 998 DF, p-value: < 2.2e-16plot(x,y)
abline(res,col="red")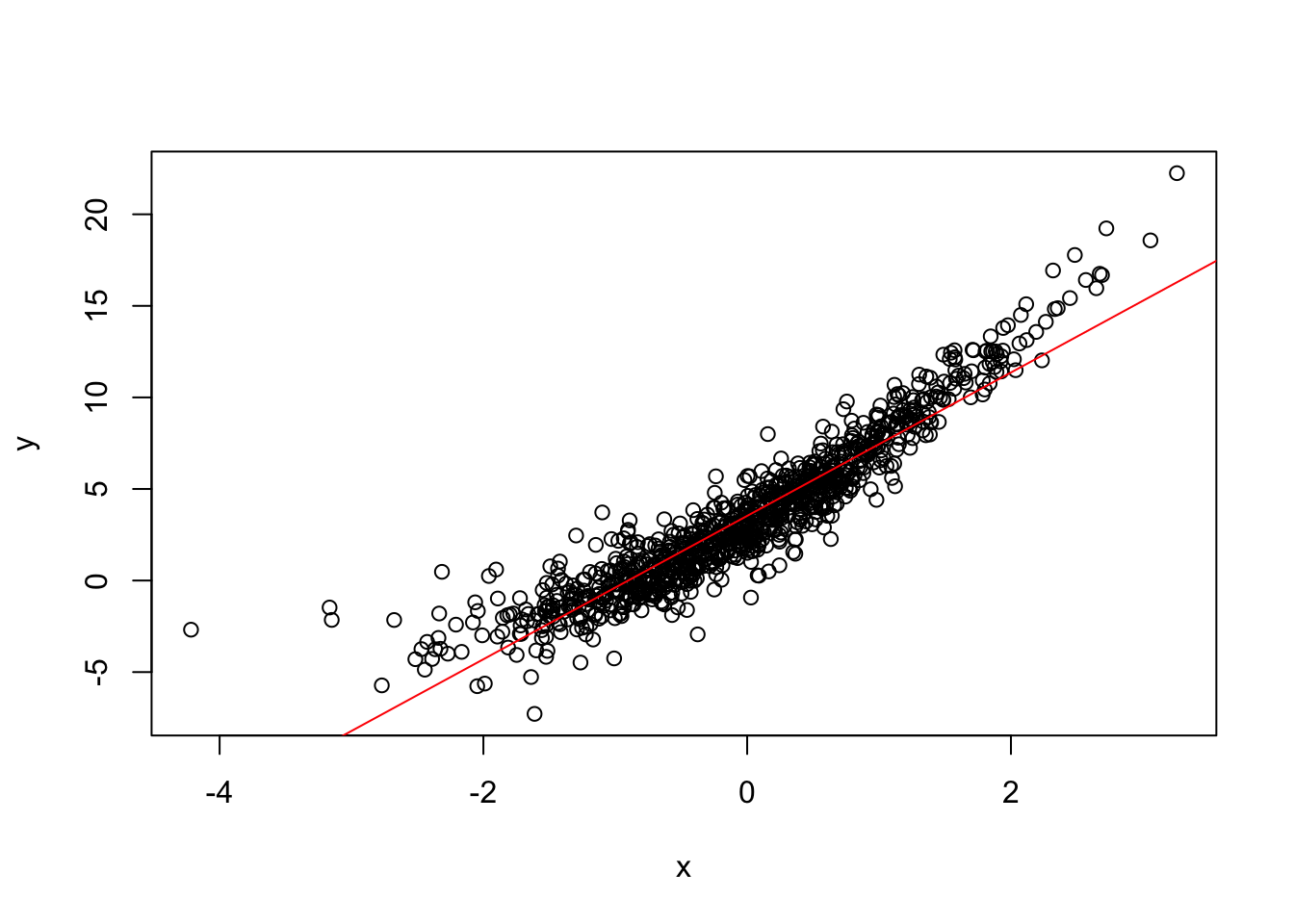
The plot of the data and the best fit regression line shows a good fit. The regression \(R^2=88\%\), which means that the right-hand-side (RHS, independent) variables explain 88% of the variation in the left-hand-side (LHS, dependent) variable. The \(t\)-statistics are highly significant, suggesting that the RHS variables are useful in explaining the LHS variable. Also, the \(F\)-statistic has a very small \(p\)-value, meaning that the collection of RHS variables form a statistically good model for explaining the LHS variable.
The output of the regression is stored in an output object res and it has various components (in R, we call these “attributes”). The names function is used to see what these components are.
names(res)## [1] "coefficients" "residuals" "effects" "rank"
## [5] "fitted.values" "assign" "qr" "df.residual"
## [9] "xlevels" "call" "terms" "model"We might be interested in extracting the coefficients of the regression, which are a component in the output object. These are addressed using the “$” extractor, i.e., follow the output object with a “$” and then the name of the attribute you want to extract. Here is an example.
res$coefficients## (Intercept) x
## 3.531866 3.9152772.9 Regression with Dummy Variables
In R, we may “factor” a variable that has levels (categorical values instead of numerical values). These categorical values are often encountered in data, for example, we may have a data set of customers and they are classified into gender, income category, etc. If you have a column of such data, then you want to “factor” the data to make it clear to R that this is categorical. Here is an example.
x1 = rnorm(1000)
w = ceiling(3*runif(1000))
y = 4 + 5*x + 6*w + rnorm(1000)*0.2
x2 = factor(w)
print(head(x2,20))## [1] 3 1 2 3 2 3 3 1 1 1 2 1 2 2 1 1 2 2 3 2
## Levels: 1 2 3We took the data w and factored it, so that R would treat it as categorical even thought the data itself was originally numerical. The way it has been coded up, will lead to three categories: \(x_2 = \{1,2,3\}\). We then run a regression of \(y\) on \(x_1\) (numerical) and \(x_2\) (categorical).
res = lm(y~x1+x2)
summary(res)##
## Call:
## lm(formula = y ~ x1 + x2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -20.9459 -3.3428 -0.0159 3.2414 16.2667
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 9.73486 0.27033 36.01 <2e-16 ***
## x1 -0.03866 0.15478 -0.25 0.803
## x22 6.37973 0.38186 16.71 <2e-16 ***
## x23 11.95114 0.38658 30.91 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.968 on 996 degrees of freedom
## Multiple R-squared: 0.4905, Adjusted R-squared: 0.4889
## F-statistic: 319.6 on 3 and 996 DF, p-value: < 2.2e-16Notice that the categorical \(x_2\) variable has been split into two RHS variables x22 and x23. However, there are 3 levels, not 2? The way to think of this is to treat category 1 as the “baseline” and then the dummy variables x22 and x23 capture the difference between category 1 and 2, and 1 and 3, respectively. We see that both are significant and positive implying that both categories 2 and 3 increase the LHS variable by their coefficients over and above the effect of category 1.
How is the regression actually run internally? What R does with a factor variable that has \(N\) levels is to create \(N-1\) columns of dummy variables, for categories 2 to \(N\), where each column is for one of these categories and takes value 1 if the column corresponds to the category and 0 otherwise. In order to see this, let’s redo the regression but create the dummy variable columns without factoring the data in R. This will serve as a cross-check of the regression above.
#CHECK THE DUMMY VARIABLE REGRESSION
idx = which(w==2); x22 = y*0; x22[idx] = 1
idx = which(w==3); x23 = y*0; x23[idx] = 1
res = lm(y~x1+x22+x23)
summary(res)##
## Call:
## lm(formula = y ~ x1 + x22 + x23)
##
## Residuals:
## Min 1Q Median 3Q Max
## -20.9459 -3.3428 -0.0159 3.2414 16.2667
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 9.73486 0.27033 36.01 <2e-16 ***
## x1 -0.03866 0.15478 -0.25 0.803
## x22 6.37973 0.38186 16.71 <2e-16 ***
## x23 11.95114 0.38658 30.91 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.968 on 996 degrees of freedom
## Multiple R-squared: 0.4905, Adjusted R-squared: 0.4889
## F-statistic: 319.6 on 3 and 996 DF, p-value: < 2.2e-16As we see, the regressions are identical. It is of course much easier to factor a variable and have R make the entire set of dummy variable columns than to write separate code to do so.
2.10 Matrix Calculations
Since the representation of data is usually in the form of tables, these are nothing but matrices and vectors. Therefore, it is a good idea to review basic matrix math, equations, calculus, etc. We start with a simple example where we manipulate economic quantities stored in matrices and vectors. We have already seen vectors for finance in an earlier section, and here we will get some practice manipulating these vectors in R.
Example: Financial Portfolios. A portfolio is described by its holdings, i.e., the proportions of various securities you may hold. These proportions are also called “weights”. The return you get on a portfolio is random, because each security has some average return, but also has a standard deviation of movement around this mean return, and for a portfolio, each security also covaries with the others. Hence, the basic information about all securities is stored in a mean return vector, which has the average return for each security. There is also a covariance matrix of returns, generated from data, and finally, the portfolio itself is described by the vector of weights.
We create these matrices below for a small portfolio comprised of four securities. We then calculate the expected return on the portfolio and the standrd deviation of portfolio return.
#PORTFOLIO CALCULATIONS
w = matrix(c(0.3,0.4,0.2,0.1),4,1) #PORTFOLIO WEIGHTS
mu = matrix(c(0.01,0.05,0.10,0.20),4,1) #MEAN RETURNS
cv = matrix(c(0.002,0.001,0.001,0.001,0.001,0.02,0.01,0.01,0.001,
0.01,0.04,0.01,0.001,0.01,0.01,0.09),4,4)
print(w)## [,1]
## [1,] 0.3
## [2,] 0.4
## [3,] 0.2
## [4,] 0.1print(mu)## [,1]
## [1,] 0.01
## [2,] 0.05
## [3,] 0.10
## [4,] 0.20print(cv)## [,1] [,2] [,3] [,4]
## [1,] 0.002 0.001 0.001 0.001
## [2,] 0.001 0.020 0.010 0.010
## [3,] 0.001 0.010 0.040 0.010
## [4,] 0.001 0.010 0.010 0.090print(c("Mean return = ",t(w)%*%mu))## [1] "Mean return = " "0.063"print(c("Return Std Dev = ",sqrt(t(w)%*%cv%*%w)))## [1] "Return Std Dev = " "0.0953939201416946"2.10.1 Diversification of a Portfolio
It is useful to examine the power of using vector algebra with an application. Here we use vector and summation math to understand how diversification in stock portfolios works. Diversification occurs when we increase the number of non-perfectly correlated stocks in a portfolio, thereby reducing portfolio variance. In order to compute the variance of the portfolio we need to use the portfolio weights \({\bf w}\) and the covariance matrix of stock returns \({\bf R}\), denoted \({\bf \Sigma}\). We first write down the formula for a portfolio’s return variance:
\[\begin{equation} Var(\boldsymbol{w'R}) = \boldsymbol{w'\Sigma w} = \sum_{i=1}^n \boldsymbol{w_i^2 \sigma_i^2} + \sum_{i=1}^n \sum_{j=1,i \neq j}^n \boldsymbol{w_i w_j \sigma_{ij}} \end{equation}\]Readers are strongly encouraged to implement this by hand for \(n=2\) to convince themselves that the vector form of the expression for variance \(\boldsymbol{w'\Sigma w}\) is the same thing as the long form on the right-hand side of the equation above. If returns are independent, then the formula collapses to:
\[\begin{equation} Var(\bf{w'R}) = \bf{w'\Sigma w} = \sum_{i=1}^n \boldsymbol{w_i^2 \sigma_i^2} \end{equation}\]If returns are dependent, and equal amounts are invested in each asset (\(w_i=1/n,\;\;\forall i\)):
\[\begin{eqnarray*} Var(\bf{w'R}) &=& \frac{1}{n}\sum_{i=1}^n \frac{\sigma_i^2}{n} + \frac{n-1}{n}\sum_{i=1}^n \sum_{j=1,i \neq j}^n \frac{\sigma_{ij}}{n(n-1)}\\ &=& \frac{1}{n} \bar{\sigma_i}^2 + \frac{n-1}{n} \bar{\sigma_{ij}}\\ &=& \frac{1}{n} \bar{\sigma_i}^2 + \left(1 - \frac{1}{n} \right) \bar{\sigma_{ij}} \end{eqnarray*}\]The first term is the average variance, denoted \(\bar{\sigma_1}^2\) divided by \(n\), and the second is the average covariance, denoted \(\bar{\sigma_{ij}}\) multiplied by factor \((n-1)/n\). As \(n \rightarrow \infty\),
\[\begin{equation} Var({\bf w'R}) = \bar{\sigma_{ij}} \end{equation}\]This produces the remarkable result that in a well diversified portfolio, the variances of each stock’s return does not matter at all for portfolio risk! Further the risk of the portfolio, i.e., its variance, is nothing but the average of off-diagonal terms in the covariance matrix.
sd=0.20; cv=0.01
n = seq(1,100)
sd_p = matrix(0,length(n),1)
for (j in n) {
cv_mat = matrix(cv,j,j)
diag(cv_mat) = sd^2
w = matrix(1/j,j,1)
sd_p[j] = sqrt(t(w) %*% cv_mat %*% w)
}
plot(n,sd_p,type="l",col="blue")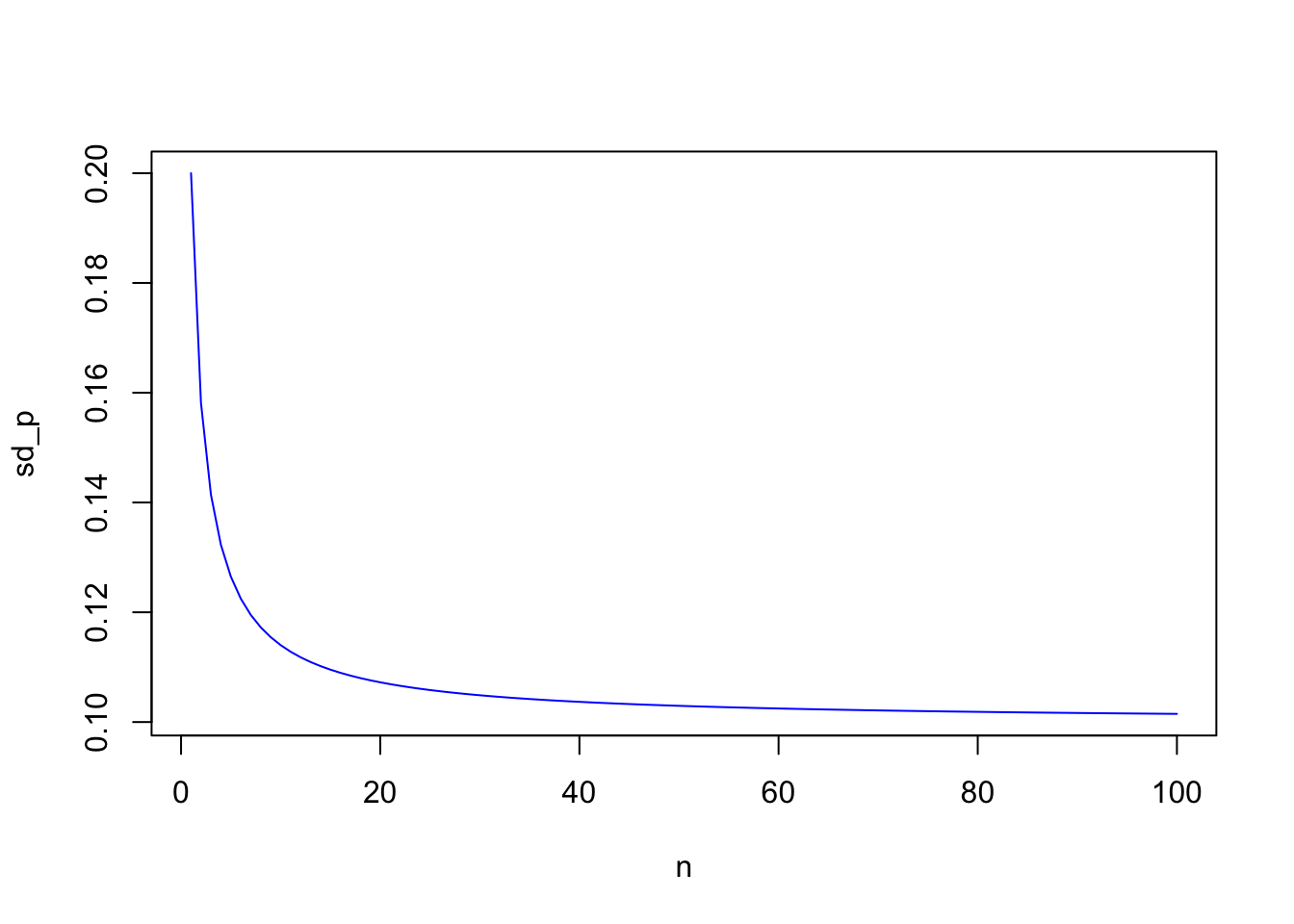
2.10.2 Diversification exercise
Implement the math above using R to compute the standard deviation of a portfolio of \(n\) identical securities with variance 0.04, and pairwise covariances equal to 0.01. Keep increasing \(n\) and report the value of the standard deviation. What do you see? Why would this be easier to do in R versus Excel?
2.11 Matrix Equations
Here we examine how matrices may be used to represent large systems of equations easily and also solve them. Using the values of matrices \({\bf A}\), \({\bf B}\) and \({\bf w}\) from the previous section, we write out the following in long form:
\[\begin{equation} {\bf A} {\bf w} = {\bf B} \end{equation}\]That is, we have
\[\begin{equation} \left[ \begin{array}{cc} 3 & 2 \\ 2 & 4 \end{array} \right] \left[ \begin{array}{c} w_1 \\ w_2 \end{array} \right] = \left[ \begin{array}{c} 3 \\ 4 \end{array} \right] \end{equation}\]Do you get 2 equations? If so, write them out. Find the solution values \(w_1\) and \(w_2\) by hand. And then we may compute the solution for \({\bf w}\) by “dividing” \({\bf B}\) by \({\bf A}\). This is not regular division because \({\bf A}\) and \({\bf B}\) are matrices. Instead we need to multiply the inverse of \({\bf A}\) (which is its “reciprocal”) by \({\bf B}\).
The inverse of \({\bf A}\) is
\[\begin{equation} {\bf A}^{-1} = \left[ \begin{array}{cc} 0.500 & -0.250 \\ -0.250 & 0.375 \end{array} \right] \end{equation}\]Now compute by hand:
\[\begin{equation} {\bf A}^{-1} {\bf B} = \left[ \begin{array}{c} 0.50 \\ 0.75 \end{array} \right] \end{equation}\]which should be the same as your solution by hand. Literally, this is all the matrix algebra and calculus you will need for most of the work we will do.
A = matrix(c(3,2,2,4),2,2)
B = matrix(c(3,4),2,1)
print(solve(A) %*% B)## [,1]
## [1,] 0.50
## [2,] 0.752.11.1 Matrix algebra exercise
The following brief notes will introduce you to everything you need to know about the vocabulary of vectors and matrices in a “DIY” (do-it-yourself) mode. Define \[ w = [w_1 \;\;\; w_2]' = \left[ \begin{array}{c} w_1 \\ w_2 \end{array} \right] \]
\[ I = \left[ \begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \right] \]
\[ \Sigma = \left[ \begin{array}{cc} \sigma_1^2 & \sigma_{12} \\ \sigma_{12} & \sigma_2^2 \end{array} \right] \] Do the following exercises in long hand:
- Show that \(I\;w = w\).
- Show that the dimensions make sense at all steps of your calculations.
- Show that \[ w' \; \Sigma \; w = w_1^2 \sigma_1^2 + 2 w_1 w_2 \sigma_{12} + w_2^2 \sigma_2^2 \]
2.12 Matrix Calculus
It is simple to undertake calculus when working with matrices. Calculations using matrices are mere functions of many variables. These functions are amenable to applying calculus, just as you would do in multivariate calculus. However, using vectors and matrices makes things simpler in fact, because we end up taking derivatives of these multivariate functions in one fell swoop rather than one-by-one for each variable.
An example will make this clear. Suppose
\[ {\bf w} = \left[ \begin{array}{c} w_1 \\ w_2 \end{array} \right] \] and \[ {\bf B} = \left[ \begin{array}{c} 3 \\ 4 \end{array} \right] \] Let \(f({\bf w}) = {\bf w}' {\bf B}\). This is a function of two variables \(w_1, w_2\). If we write out \(f({\bf w})\) in long form, we get \(3 w_1 + 4 w_2\). The derivative of \(f({\bf w})\) with respect to \(w_1\) is \(\frac{\partial f}{\partial w_1} = 3\). The derivative of \(f({\bf w})\) with respect to \(w_2\) is \(\frac{\partial f}{\partial w_2} = 4\). Compare these answers to vector \({\bf B}\). What do you see? What is \(\frac{df}{d{\bf w}}\)? It’s \({\bf B}\).
The insight here is that if we simply treat the vectors as regular scalars and conduct calculus accordingly, we will end up with vector derivatives. Hence, the derivative of \({\bf w}' {\bf B}\) with respect to \({\bf w}\) is just \({\bf B}\). Of course, \({\bf w}' {\bf B}\) is an entire function and \({\bf B}\) is a vector. But the beauty of this is that we can take all derivatives of function \({\bf w}' {\bf B}\) at one time!
These ideas can also be extended to higher-order matrix functions. Suppose \[ {\bf A} = \left[ \begin{array}{cc} 3 & 2 \\ 2 & 4 \end{array} \right] \] and \[ {\bf w} = \left[ \begin{array}{c} w_1 \\ w_2 \end{array} \right] \] Let \(f({\bf w}) = {\bf w}' {\bf A} {\bf w}\). If we write out \(f({\bf w})\) in long form, we get \[ {\bf w}' {\bf A} {\bf w} = 3 w_1^2 + 4 w_2^2 + 2 (2) w_1 w_2 \] Take the derivative of \(f({\bf w})\) with respect to \(w_1\), and this is \[ \frac{df}{dw_1} = 6 w_1 + 4 w_2 \] Take the derivative of \(f({\bf w})\) with respect to \(w_2\), and this is \[ \frac{df}{dw_2} = 8 w_2 + 4 w_1 \] Now, we write out the following calculation in long form: \[ 2\; {\bf A} \; {\bf w} = 2 \left[ \begin{array}{cc} 3 & 2 \\ 2 & 4 \end{array} \right] \left[ \begin{array}{c} w_1 \\ w_2 \end{array} \right] = \left[ \begin{array}{c} 6 w_1 + 4 w_2 \\ 8 w_2 + 4 w_1 \end{array} \right] \] What do you notice about this solution when compared to the previous two answers? It is nothing but \(\frac{df}{dw}\). Since \(w \in R^2\), i.e., is of dimension 2, the derivative \(\frac{df}{dw}\) will also be of that dimension. To see how this corresponds to scalar calculus, think of the function \(f({\bf w}) = {\bf w}' {\bf A} {\bf w}\) as simply \({\bf A} w^2\), where \(w\) is scalar. The derivative of this function with respect to \(w\) would be \(2{\bf A}w\). And, this is the same as what we get when we look at a function of vectors, but with the caveat below.
Note: This computation only works out because \({\bf A}\) is symmetric. What should the expression be for the derivative of this vector function if \({\bf A}\) is not symmetric but is a square matrix? It turns out that this is \[ \frac{\partial f}{\partial {\bf w}} = {\bf A}' {\bf w} + {\bf A} {\bf w} \neq 2 {\bf A} {\bf w} \] Let’s try this and see. Suppose \[ {\bf A} = \left[ \begin{array}{cc} 3 & 2 \\ 1 & 4 \end{array} \right] \] You can check that the following is all true: \[\begin{eqnarray*} {\bf w}' {\bf A} {\bf w} &=& 3 w_1^2 + 4 w_2^2 + 3 w_1 w_2 \\ \frac{\partial f}{\partial w_1} &=& 6 w_1 + 3 w_2\\ \frac{\partial f}{\partial w_2} &=& 3 w_1 + 8 w_2 \end{eqnarray*}\]and \[ {\bf A}' {\bf w} + {\bf A} {\bf w} = \left[ \begin{array}{c} 6w_1+3w_2 \\ 3w_1+8w_2 \end{array} \right] \] which is correct, but note that the formula for symmetric \({\bf A}\) is not! \[ 2{\bf A} {\bf w} = \left[ \begin{array}{c} 6w_1+4w_2 \\ 2w_1+8w_2 \end{array} \right] \]
2.12.1 More exercises
Try the following questions for practice.
What is the value of \[ {\bf A}^{-1} {\bf A} {\bf B} \] Is this vector or scalar?
What is the final dimension of \[ {\bf (w'B) (A A A^{-1} B)} \]
2.13 Complex Numbers and Euler’s Equation
You can also handle complex numbers in R. The representation is x + y*1i
\[ e^{i \pi}+1=0 \]
print(pi)## [1] 3.141593exp(1i*pi)+1## [1] 0+1.224647e-16iOften, the notation for transpose is to superscript \(T\), and in this case we would write this as \(w^\top\). We may use either notation in the rest of the book.↩