Chapter 8 Much More: Word Embeddings
8.1 Word Embeddings with text2vec
See the original vignette from which this is abstracted. https://cran.r-project.org/web/packages/text2vec/vignettes/text-vectorization.html
suppressMessages(library(text2vec))8.2 How to process data quickly using text2vec
8.2.1 Read in the provided data.
suppressMessages(library(data.table))
data("movie_review")
setDT(movie_review)
setkey(movie_review, id)
set.seed(2016L)
all_ids = movie_review$id
train_ids = sample(all_ids, 4000)
test_ids = setdiff(all_ids, train_ids)
train = movie_review[J(train_ids)]
test = movie_review[J(test_ids)]
print(head(train))## id sentiment
## 1: 11912_2 0
## 2: 11507_10 1
## 3: 8194_9 1
## 4: 11426_10 1
## 5: 4043_3 0
## 6: 11287_3 0
## review
## 1: The story behind this movie is very interesting, and in general the plot is not so bad... but the details: writing, directing, continuity, pacing, action sequences, stunts, and use of CG all cheapen and spoil the film.<br /><br />First off, action sequences. They are all quite unexciting. Most consist of someone standing up and getting shot, making no attempt to run, fight, dodge, or whatever, even though they have all the time in the world. The sequences just seem bland for something made in 2004.<br /><br />The CG features very nicely rendered and animated effects, but they come off looking cheap because of how they are used.<br /><br />Pacing: everything happens too quickly. For example, \\"Elle\\" is trained to fight in a couple of hours, and from the start can do back-flips, etc. Why is she so acrobatic? None of this is explained in the movie. As Lilith, she wouldn't have needed to be able to do back flips - maybe she couldn't, since she had wings.<br /><br />Also, we have sequences like a woman getting run over by a car, and getting up and just wandering off into a deserted room with a sink and mirror, and then stabbing herself in the throat, all for no apparent reason, and without any of the spectators really caring that she just got hit by a car (and then felt the secondary effects of another, exploding car)... \\"Are you okay?\\" asks the driver \\"yes, I'm fine\\" she says, bloodied and disheveled.<br /><br />I watched it all, though, because the introduction promised me that it would be interesting... but in the end, the poor execution made me wish for anything else: Blade, Vampire Hunter D, even that movie with vampires where Jackie Chan was comic relief, because they managed to suspend my disbelief, but this just made me want to shake the director awake, and give the writer a good talking to.
## 2: I remember the original series vividly mostly due to it's unique blend of wry humor and macabre subject matter. Kolchak was hard-bitten newsman from the Ben Hecht school of big-city reporting, and his gritty determination and wise-ass demeanor made even the most mundane episode eminently watchable. My personal fave was \\"The Spanish Moss Murders\\" due to it's totally original storyline. A poor,troubled Cajun youth from Louisiana bayou country, takes part in a sleep research experiment, for the purpose of dream analysis. Something goes inexplicably wrong, and he literally dreams to life a swamp creature inhabiting the dark folk tales of his youth. This malevolent manifestation seeks out all persons who have wronged the dreamer in his conscious state, and brutally suffocates them to death. Kolchak investigates and uncovers this horrible truth, much to the chagrin of police captain Joe \\"Mad Dog\\" Siska(wonderfully essayed by a grumpy Keenan Wynn)and the head sleep researcher played by Second City improv founder, Severn Darden, to droll, understated perfection. The wickedly funny, harrowing finale takes place in the Chicago sewer system, and is a series highlight. Kolchak never got any better. Timeless.
## 3: Despite the other comments listed here, this is probably the best Dirty Harry movie made; a film that reflects -- for better or worse -- the country's socio-political feelings during the Reagan glory years of the early '80's. It's also a kickass action movie.<br /><br />Opening with a liberal, female judge overturning a murder case due to lack of tangible evidence and then going straight into the coffee shop encounter with several unfortunate hoodlums (the scene which prompts the famous, \\"Go ahead, make my day\\" line), \\"Sudden Impact\\" is one non-stop roller coaster of an action film. The first time you get to catch your breath is when the troublesome Inspector Callahan is sent away to a nearby city to investigate the background of a murdered hood. It gets only better from there with an over-the-top group of grotesque thugs for Callahan to deal with along with a sherriff with a mysterious past. Superb direction and photography and a at-times hilarious script help make this film one of the best of the '80's.
## 4: I think this movie would be more enjoyable if everyone thought of it as a picture of colonial Africa in the 50's and 60's rather than as a story. Because there is no real story here. Just one vignette on top of another like little points of light that don't mean much until you have enough to paint a picture. The first time I saw Chocolat I didn't really \\"get it\\" until having thought about it for a few days. Then I realized there were lots of things to \\"get\\", including the end of colonialism which was but around the corner, just no plot. Anyway, it's one of my all-time favorite movies. The scene at the airport with the brief shower and beautiful music was sheer poetry. If you like \\"exciting\\" movies, don't watch this--you'll be bored to tears. But, for some of you..., you can thank me later for recommending it to you.
## 5: The film begins with promise, but lingers too long in a sepia world of distance and alienation. We are left hanging, but with nothing much else save languid shots of grave and pensive male faces to savour. Certainly no rope up the wall to help us climb over. It's a shame, because the concept is not without merit.<br /><br />We are left wondering why a loving couple - a father and son no less - should be so estranged from the real world that their own world is preferable when claustrophobic beyond all imagining. This loss of presence in the real world is, rather too obviously and unnecessarily, contrasted with the son having enlisted in the armed forces. Why not the circus, so we can at least appreciate some colour? We are left with a gnawing sense of loss, but sadly no enlightenment, which is bewildering given the film is apparently about some form of attainment not available to us all.
## 6: This is a film that had a lot to live down to . on the year of its release legendary film critic Barry Norman considered it the worst film of the year and I'd heard nothing but bad things about it especially a plot that was criticised for being too complicated <br /><br />To be honest the plot is something of a red herring and the film suffers even more when the word \\" plot \\" is used because as far as I can see there is no plot as such . There's something involving Russian gangsters , a character called Pete Thompson who's trying to get his wife Sarah pregnant , and an Irish bloke called Sean . How they all fit into something called a \\" plot \\" I'm not sure . It's difficult to explain the plots of Guy Ritchie films but if you watch any of his films I'm sure we can all agree that they all posses one no matter how complicated they may seem on first viewing . Likewise a James Bond film though the plots are stretched out with action scenes . You will have a serious problem believing RANCID ALUMINIUM has any type of central plot that can be cogently explained <br /><br />Taking a look at the cast list will ring enough warning bells as to what sort of film you'll be watching . Sadie Frost has appeared in some of the worst British films made in the last 15 years and she's doing nothing to become inconsistent . Steven Berkoff gives acting a bad name ( and he plays a character called Kant which sums up the wit of this movie ) while one of the supporting characters is played by a TV presenter presumably because no serious actress would be seen dead in this <br /><br />The only good thing I can say about this movie is that it's utterly forgettable . I saw it a few days ago and immediately after watching I was going to write a very long a critical review warning people what they are letting themselves in for by watching , but by now I've mainly forgotten why . But this doesn't alter the fact that I remember disliking this piece of crap immenselyThe processing steps are:
- Lower case the documents and then tokenize them.
- Create an iterator. (Step 1 can also be done while making the iterator, as the itoken function supports this, see below.)
- Use the iterator to create the vocabulary, which is nothing but the list of unique words across all documents.
- Vectorize the vocabulary, i.e., create a data structure of words that can be used later for matrix factorizations needed for various text analytics.
- Using the iterator and vectorized vocabulary, form text matrices, such as the Document-Term Matrix (DTM) or the Term Co-occurrence Matrix (TCM).
- Use the TCM or DTM to undertake various text analytics such as classification, word2vec, topic modeling using LDA (Latent Dirichlet Allocation), and LSA (Latent Semantic Analysis).
8.3 Preprocessing and Tokenization
prep_fun = tolower
tok_fun = word_tokenizer
#Create an iterator to pass to the create_vocabulary function
it_train = itoken(train$review,
preprocessor = prep_fun,
tokenizer = tok_fun,
ids = train$id,
progressbar = FALSE)
#Now create a vocabulary
vocab = create_vocabulary(it_train)
print(vocab)## Number of docs: 4000
## 0 stopwords: ...
## ngram_min = 1; ngram_max = 1
## Vocabulary:
## terms terms_counts doc_counts
## 1: overturned 1 1
## 2: disintegration 1 1
## 3: vachon 1 1
## 4: interfered 1 1
## 5: michonoku 1 1
## ---
## 35592: penises 2 2
## 35593: arabian 1 1
## 35594: personal 102 94
## 35595: end 921 743
## 35596: address 10 108.4 Iterator
An iterator is an object that traverses a container. A list is iterable. See: https://www.r-bloggers.com/iterators-in-r/
8.5 Vectorize
vectorizer = vocab_vectorizer(vocab)8.6 Document Term Matrix (DTM)
dtm_train = create_dtm(it_train, vectorizer)
print(dim(as.matrix(dtm_train)))## [1] 4000 355968.7 N-Grams
n-grams are phrases made by coupling words that co-occur. For example, a bi-gram is a set of two consecutive words.
vocab = create_vocabulary(it_train, ngram = c(1, 2))
print(vocab)## Number of docs: 4000
## 0 stopwords: ...
## ngram_min = 1; ngram_max = 2
## Vocabulary:
## terms terms_counts doc_counts
## 1: bad_characterization 1 1
## 2: few_step 1 1
## 3: also_took 1 1
## 4: in_graphics 1 1
## 5: like_poke 1 1
## ---
## 397499: original_uncut 1 1
## 397500: settle_his 2 2
## 397501: first_blood 2 1
## 397502: occasional_at 1 1
## 397503: the_brothers 14 14This creates a vocabulary of both single words and bi-grams. Notice how large it is compared to the unigram vocabulary from earlier. Because of this we go ahead and prune the vocabulary first, as this will speed up computation.
8.7.1 Redo classification with n-grams.
library(glmnet)## Loading required package: Matrix## Loading required package: foreach## Loaded glmnet 2.0-5NFOLDS = 5
vocab = vocab %>% prune_vocabulary(term_count_min = 10,
doc_proportion_max = 0.5)
print(vocab)## Number of docs: 4000
## 0 stopwords: ...
## ngram_min = 1; ngram_max = 2
## Vocabulary:
## terms terms_counts doc_counts
## 1: morvern 14 1
## 2: race_films 10 1
## 3: bazza 11 1
## 4: thunderbirds 10 1
## 5: mary_lou 21 1
## ---
## 17866: br_also 36 36
## 17867: a_better 96 89
## 17868: tourists 10 10
## 17869: in_each 14 14
## 17870: the_brothers 14 14bigram_vectorizer = vocab_vectorizer(vocab)
dtm_train = create_dtm(it_train, bigram_vectorizer)
res = cv.glmnet(x = dtm_train, y = train[['sentiment']],
family = 'binomial',
alpha = 1,
type.measure = "auc",
nfolds = NFOLDS,
thresh = 1e-3,
maxit = 1e3)
plot(res)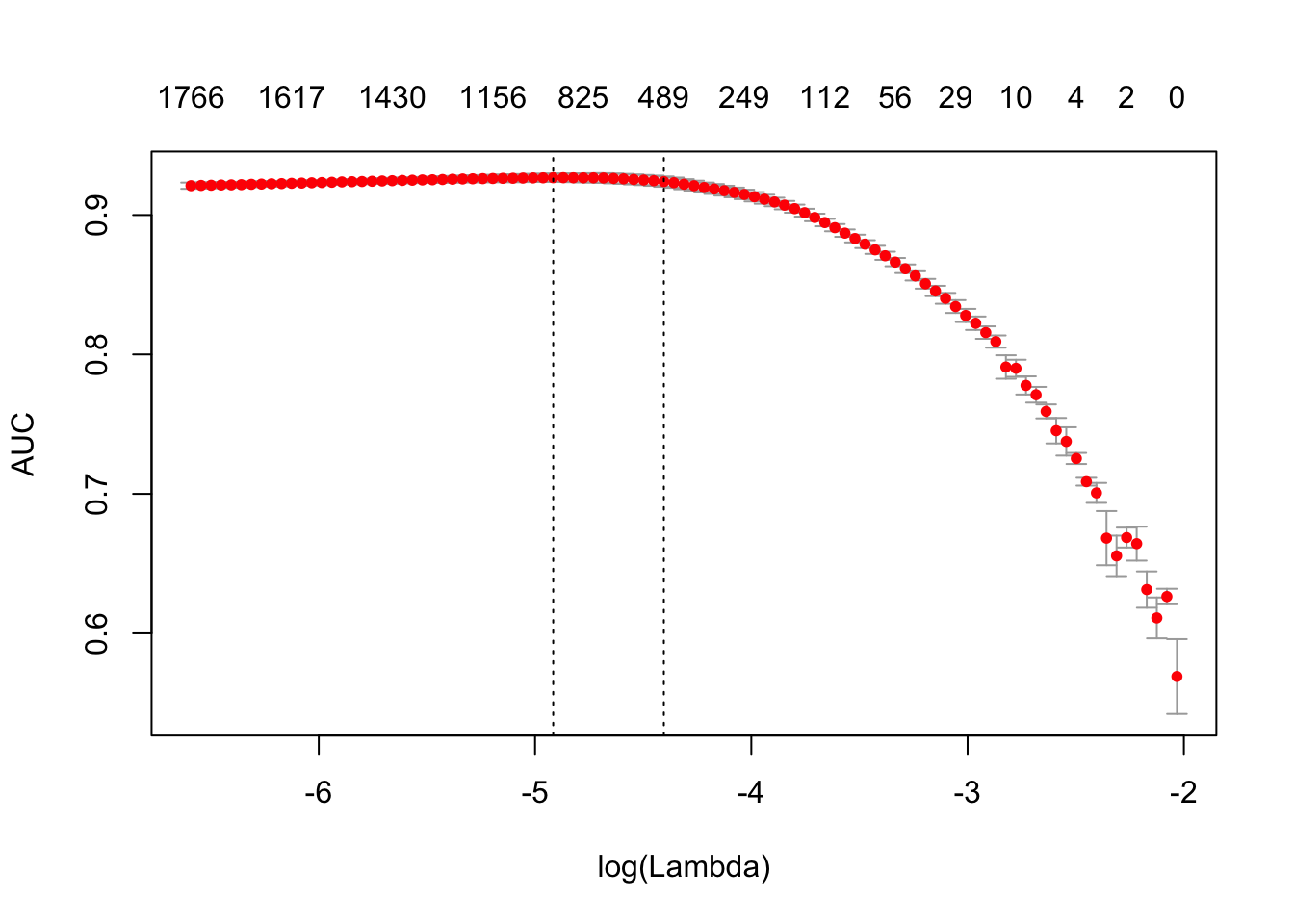
print(names(res))## [1] "lambda" "cvm" "cvsd" "cvup" "cvlo"
## [6] "nzero" "name" "glmnet.fit" "lambda.min" "lambda.1se"#AUC (area under curve)
print(max(res$cvm))## [1] 0.92677768.7.2 Out-of-sample test
it_test = test$review %>%
prep_fun %>%
tok_fun %>%
itoken(ids = test$id,
# turn off progressbar because it won't look nice in rmd
progressbar = FALSE)
dtm_test = create_dtm(it_test, bigram_vectorizer)
preds = predict(res, dtm_test, type = 'response')[,1]
glmnet:::auc(test$sentiment, preds)## [1] 0.93092958.8 TF-IDF
We have seen the TF-IDF discussion earlier, and here we see how to implement it using the text2vec package.
vocab = create_vocabulary(it_train)
vectorizer = vocab_vectorizer(vocab)
dtm_train = create_dtm(it_train, vectorizer)
tfidf = TfIdf$new()
dtm_train_tfidf = fit_transform(dtm_train, tfidf)
dtm_test_tfidf = create_dtm(it_test, vectorizer) %>% transform(tfidf)Now we take the TF-IDF adjusted DTM and run the classifier.
8.9 Refit classifier
res = cv.glmnet(x = dtm_train_tfidf, y = train[['sentiment']],
family = 'binomial',
alpha = 1,
type.measure = "auc",
nfolds = NFOLDS,
thresh = 1e-3,
maxit = 1e3)
print(paste("max AUC =", round(max(res$cvm), 4)))## [1] "max AUC = 0.9115"#Test on hold-out sample
preds = predict(res, dtm_test_tfidf, type = 'response')[,1]
glmnet:::auc(test$sentiment, preds)## [1] 0.90399658.10 Embeddings (word2vec)
From: http://stackoverflow.com/questions/39514941/preparing-word-embeddings-in-text2vec-r-package
Do the entire creation of the TCM (Term Co-occurrence Matrix)
suppressMessages(library(magrittr))
suppressMessages(library(text2vec))
data("movie_review")
tokens = movie_review$review %>% tolower %>% word_tokenizer()
it = itoken(tokens)
v = create_vocabulary(it) %>% prune_vocabulary(term_count_min=10)
vectorizer = vocab_vectorizer(v, grow_dtm = FALSE, skip_grams_window = 5)
tcm = create_tcm(it, vectorizer)
print(dim(tcm))## [1] 7797 7797Now fit the word embeddings using GloVe See: http://nlp.stanford.edu/projects/glove/
model = GlobalVectors$new(word_vectors_size=50, vocabulary=v,
x_max=10, learning_rate=0.20)
model$fit(tcm,n_iter=25)## 2017-03-24 11:41:55 - epoch 1, expected cost 0.0820## 2017-03-24 11:41:55 - epoch 2, expected cost 0.0508## 2017-03-24 11:41:56 - epoch 3, expected cost 0.0433## 2017-03-24 11:41:56 - epoch 4, expected cost 0.0390## 2017-03-24 11:41:56 - epoch 5, expected cost 0.0359## 2017-03-24 11:41:56 - epoch 6, expected cost 0.0337## 2017-03-24 11:41:56 - epoch 7, expected cost 0.0321## 2017-03-24 11:41:57 - epoch 8, expected cost 0.0307## 2017-03-24 11:41:57 - epoch 9, expected cost 0.0296## 2017-03-24 11:41:57 - epoch 10, expected cost 0.0288## 2017-03-24 11:41:57 - epoch 11, expected cost 0.0281## 2017-03-24 11:41:57 - epoch 12, expected cost 0.0275## 2017-03-24 11:41:58 - epoch 13, expected cost 0.0269## 2017-03-24 11:41:58 - epoch 14, expected cost 0.0264## 2017-03-24 11:41:58 - epoch 15, expected cost 0.0260## 2017-03-24 11:41:58 - epoch 16, expected cost 0.0257## 2017-03-24 11:41:59 - epoch 17, expected cost 0.0253## 2017-03-24 11:41:59 - epoch 18, expected cost 0.0251## 2017-03-24 11:41:59 - epoch 19, expected cost 0.0248## 2017-03-24 11:41:59 - epoch 20, expected cost 0.0246## 2017-03-24 11:41:59 - epoch 21, expected cost 0.0243## 2017-03-24 11:42:00 - epoch 22, expected cost 0.0242## 2017-03-24 11:42:00 - epoch 23, expected cost 0.0240## 2017-03-24 11:42:00 - epoch 24, expected cost 0.0238## 2017-03-24 11:42:00 - epoch 25, expected cost 0.0236wv = model$get_word_vectors() #Dimension words x wvec_size8.11 Distance between words (or find close words)
#Make distance matrix
d = dist2(wv, method="cosine") #Smaller values means closer
print(dim(d))## [1] 7797 7797#Pass: w=word, d=dist matrix, n=nomber of close words
findCloseWords = function(w,d,n) {
words = rownames(d)
i = which(words==w)
if (length(i) > 0) {
res = sort(d[i,])
print(as.matrix(res[2:(n+1)]))
}
else {
print("Word not in corpus.")
}
}Example: Show the ten words close to the word “man” and “woman”.
findCloseWords("man",d,10)## [,1]
## woman 0.2009660
## girl 0.2371918
## guy 0.2802020
## who 0.3009101
## young 0.3341396
## person 0.3397372
## boy 0.3733406
## hit 0.3953263
## old 0.4037096
## he 0.4111968findCloseWords("woman",d,10)## [,1]
## young 0.1754151
## man 0.2009660
## girl 0.2546709
## boy 0.2981061
## who 0.3186094
## guy 0.3222383
## named 0.3372591
## kid 0.3728761
## child 0.3759926
## doctor 0.3941979This is a very useful feature of word embeddings, as it is often argued that in the embedded space, words that are close to each other, also tend to have semantic similarities, even though the closeness is computed simply by using their co-occurence frequencies.
8.12 word2vec (explained)
For more details, see: https://www.quora.com/How-does-word2vec-work
A geometrical interpretation: word2vec is a shallow word embedding model. This means that the model learns to map each discrete word id (0 through the number of words in the vocabulary) into a low-dimensional continuous vector-space from their distributional properties observed in some raw text corpus. Geometrically, one may interpret these vectors as tracing out points on the outside surface of a manifold in the “embedded space”. If we initialize these vectors from a spherical gaussian distribution, then you can imagine this manifold to look something like a hypersphere initially.
Let us focus on the CBOW for now. CBOW is trained to predict the target word t from the contextual words that surround it, c, i.e. the goal is to maximize P(t | c) over the training set. I am simplifying somewhat, but you can show that this probability is roughly inversely proportional to the distance between the current vectors assigned to t and to c. Since this model is trained in an online setting (one example at a time), at time T the goal is therefore to take a small step (mediated by the “learning rate”) in order to minimize the distance between the current vectors for t and c (and thereby increase the probability P(t |c)). By repeating this process over the entire training set, we have that vectors for words that habitually co-occur tend to be nudged closer together, and by gradually lowering the learning rate, this process converges towards some final state of the vectors.
By the Distributional Hypothesis (Firth, 1957; see also the Wikipedia page on Distributional semantics), words with similar distributional properties (i.e. that co-occur regularly) tend to share some aspect of semantic meaning. For example, we may find several sentences in the training set such as “citizens of X protested today” where X (the target word t) may be names of cities or countries that are semantically related.
You can therefore interpret each training step as deforming or morphing the initial manifold by nudging the vectors for some words somewhat closer together, and the result, after projecting down to two dimensions, is the familiar t-SNE visualizations where related words cluster together (e.g. Word representations for NLP).
For the skipgram, the direction of the prediction is simply inverted, i.e. now we try to predict P(citizens | X), P(of | X), etc. This turns out to learn finer-grained vectors when one trains over more data. The main reason is that the CBOW smooths over a lot of the distributional statistics by averaging over all context words while the skipgram does not. With little data, this “regularizing” effect of the CBOW turns out to be helpful, but since data is the ultimate regularizer the skipgram is able to extract more information when more data is available.
There’s a bit more going on behind the scenes, but hopefully this helps to give a useful geometrical intuition as to how these models work.
8.13 Topic Analysis
Uses Latent Dirichlet Allocation.
suppressMessages(library(tm))
suppressMessages(library(text2vec))
stopw = stopwords('en')
stopw = c(stopw,"br","t","s","m","ve","2","d","1")
#Make DTM
data("movie_review")
tokens = movie_review$review %>% tolower %>% word_tokenizer()
it = itoken(tokens)
v = create_vocabulary(it, stopwords = stopw) %>%
prune_vocabulary(term_count_min=5)
vectrzr = vocab_vectorizer(v, grow_dtm = TRUE, skip_grams_window = 5)
dtm = create_dtm(it, vectrzr)
print(dim(dtm))## [1] 5000 12733#Do LDA
lda = LatentDirichletAllocation$new(n_topics=5, v)
lda$fit(dtm,n_iter = 25)
doc_topics = lda$fit_transform(dtm,n_iter = 25)
print(dim(doc_topics))## [1] 5000 5#Get word vectors by topic
topic_wv = lda$get_word_vectors()
print(dim(topic_wv))## [1] 12733 5#Plot LDA
suppressMessages(library(LDAvis))
lda$plot()## Loading required namespace: servrThis produces a terrific interactive plot.
8.14 Latent Semantic Analysis (LSA)
lsa = LatentSemanticAnalysis$new(n_topics = 5)
res = lsa$fit_transform(dtm)
print(dim(res))## [1] 5000 5Biblio at: http://srdas.github.io/Das_TextAnalyticsInFinance.pdf