
49. Algorithmic Fairness#
Related slides presented at the JOIM Conference (Fall 2023) are here.
Paper titled “Algorithmic Fairness” (with Richard Stanton and Nancy Wallace) published in the Annual Review of Financial Economics, v15, 2023.
References from the Ethics Center at SCU: https://www.scu.edu/ethics/internet-ethics-blog/readings-in-ai-ethics/
from google.colab import drive
drive.mount('/content/drive') # Add My Drive/<>
import os
os.chdir('drive/My Drive')
os.chdir('Books_Writings/NLPBook/')
Mounted at /content/drive
%%capture
%pylab inline
import pandas as pd
import os
from IPython.display import Image
49.1. Pillars of Responsible AI#
An umbrella construct encompassing Fairness
Includes model Interpretability (methods such as SHAP, Integrated Gradients, TCAV, etc.), aka explainability (XAI)
Governance (model cards), https://modelcards.withgoogle.com/about
Robustness (model monitoring)
Security (tamper-proof models)
PII, differential privacy, promotes fairness
Transparency (model cards, open source)
Labor (solidarity)
Sustainability
49.2. Applies to Generative AI as well#
Image('NLP_images/character_ai.png', width=800)
49.3. Overview/Assumptions#
What is bias/fairness depends on a socio-ethical-legal-economic value system. (e.g., fair markets depend on information sets.)
Various legal frameworks : US Civil Rights Act of 1964, the European Union’s General Data Protection Regulation (GDPR), the Fair Credit Reporting Act (FCRA), the Equal Credit Opportunity Act (ECOA), SR-11 regulation, and Reg B, to name a few.
Humans and machines can be biased.
Data may be biased
Algorithms can perpetrate bias at scale, and through cascading, since the decisions feed back into the data.
And, explaining machine bias may be easier than explaining human bias
There are two sides to this issue, technical and ethical.
Image('NLP_images/two_hands.png', width=800)

49.4. AI/ML and Bias#
The modality of the data is related to the kinds of bias we see:
Tabular - in lending models
Text - NLP models associate men with construction, women with nursing
Images - lack of training data of certain groups can lower accuracy for those groups
We will assume the simplest type of ML algorithm, a binary classifier, and we see the myriad forms of bias that may occur even with the simplest of models.
An algorithm’s bias emanates from
Bias in the data (pre-processing)
Biased predictions from the model/algorithm (post-processing)
Constrained fairness (in-processing)
49.5. Antecedents#
Bias in labels: human labelers make errors
Bias in features: humans make errors in feature selection
Bias in objective functions: e.g., loss functions that may focus on outliers, which occur more in one group than the other
Machines perpetuate bias, through incrementing data, i.e., homogenization bias
Active bias, intended and deliberate human actions
Random bias from lack of constraints on models, e.g., eradicating poverty
Image('NLP_images/antecedents.png', width=800)

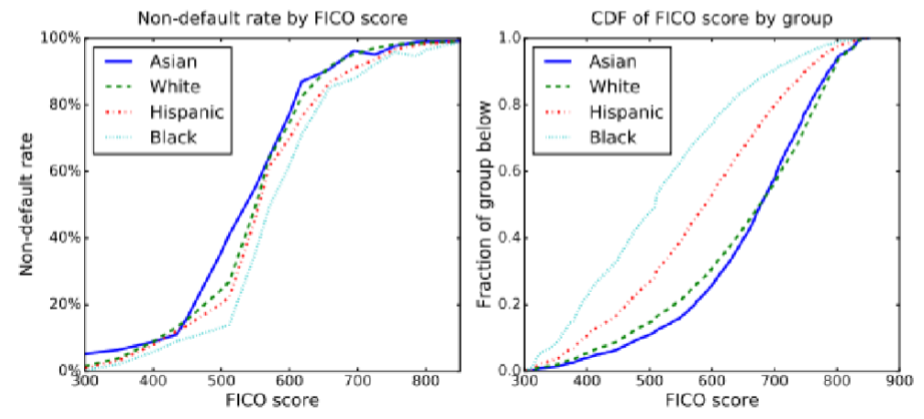
49.6. Group vs Individual Fairness#
Hardt, Price, Srebro (2016): https://arxiv.org/pdf/1610.02413.pdf
We see below that even though the default rates are the same for all groups, the FICO score distributions are not.
Image('NLP_images/fico_bias.png', width=800)
49.7. Notation#
Image('NLP_images/notation.png', width=800)

Image('NLP_images/ml_metrics.png', width=800)
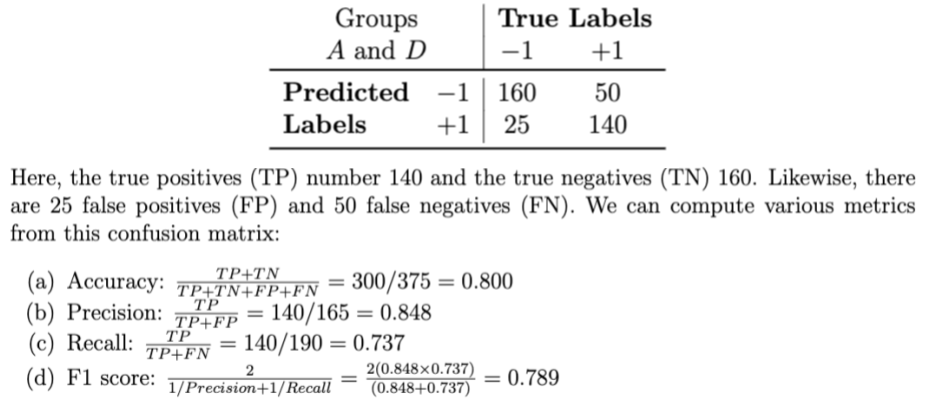
49.8. Metrics by Group#
Image('NLP_images/metrics_by_group.png', width=800)

49.9. Dataset Fairness#
Image('NLP_images/dataset_fairness.png', width=800)

49.10. Group Fairness#
Image('NLP_images/group_fairness1.png', width=800)

Image('NLP_images/group_fairness2.png', width=800)

Image('NLP_images/group_fairness3.png', width=800)

49.11. Individual Fairness#
Image('NLP_images/individual_fairness.png', width=800)

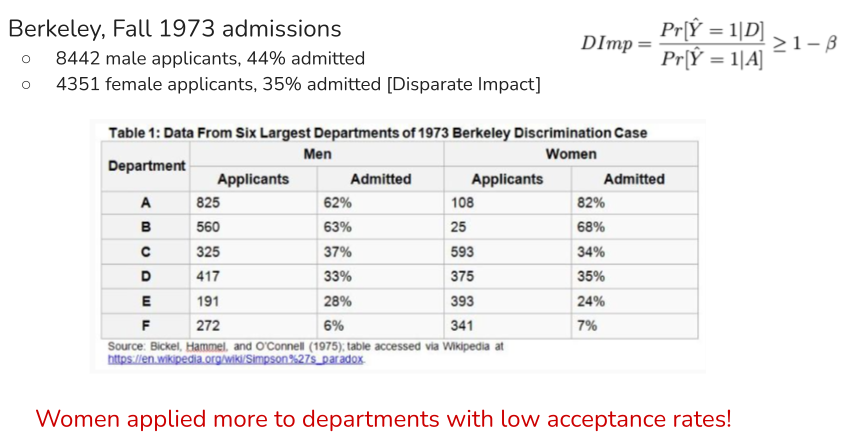
49.12. Simpson’s Paradox and Bias#
Image('NLP_images/simpsons_paradox.png', width=800)
49.13. Some References#
Image('NLP_images/ARfairness_references.png', width=800)

49.14. Application: Mortgage Data#
Automated underwriting (AU) technology has provided accurate and readily scalable risk assessment tools, without which lenders of consumer credit could not have successfully reduced loan defaults, underwriting costs, and loan pricing; expanded access to credit; and leveled the competitive playing-field for small, medium-sized, and large lenders (see Thomas 2009, Avery et al. 2009, Abduo & Pointon 2011, FinRegLab 2021).
For secondary-market securitizers, who purchase loans, AU systems have greatly reduced the extent of principal-agent-based adverse selection that has long been a risk of aggregating loans from numerous counter-parties (see Straka 2000).
The current era of automated underwriting 2.0 increasingly relies on advanced artificial intelligence (AI) technology that electronically undertakes the decision making process for scoring and managing credit applications.
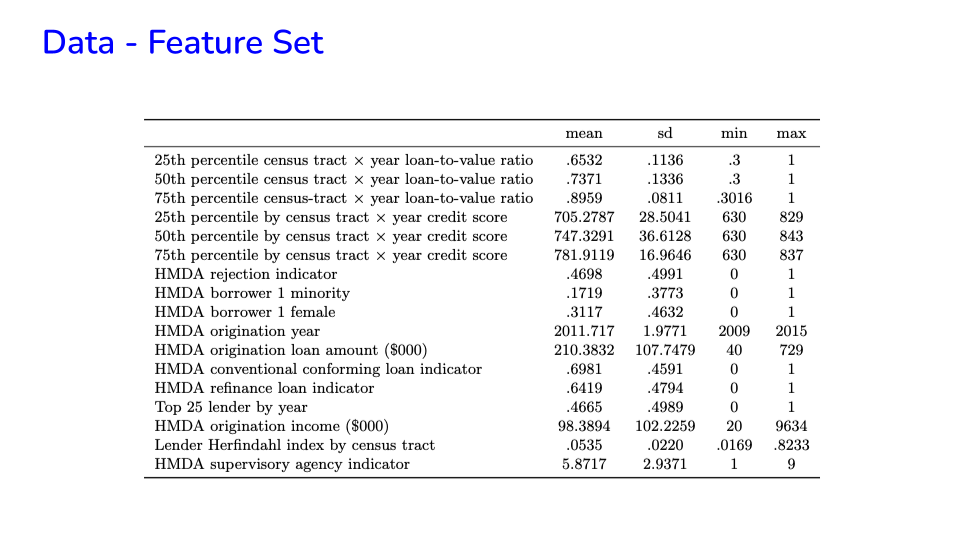
Image('NLP_images/mortgage_feature_set.png', width=800)
Image('NLP_images/mortgage_ml.png', width=800)

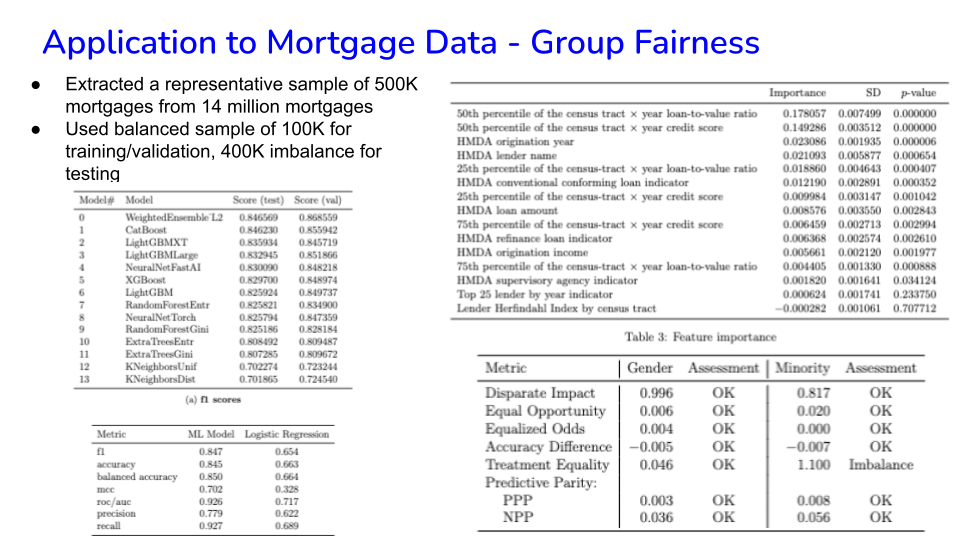
49.15. Mortgages - Group Fairness#
Image('NLP_images/mortgage_group_fairness.png', width=800)
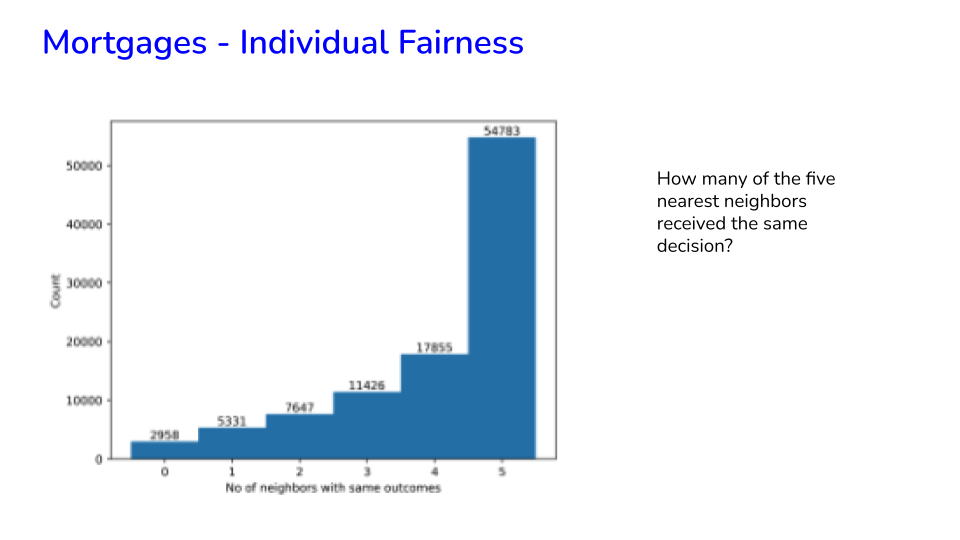
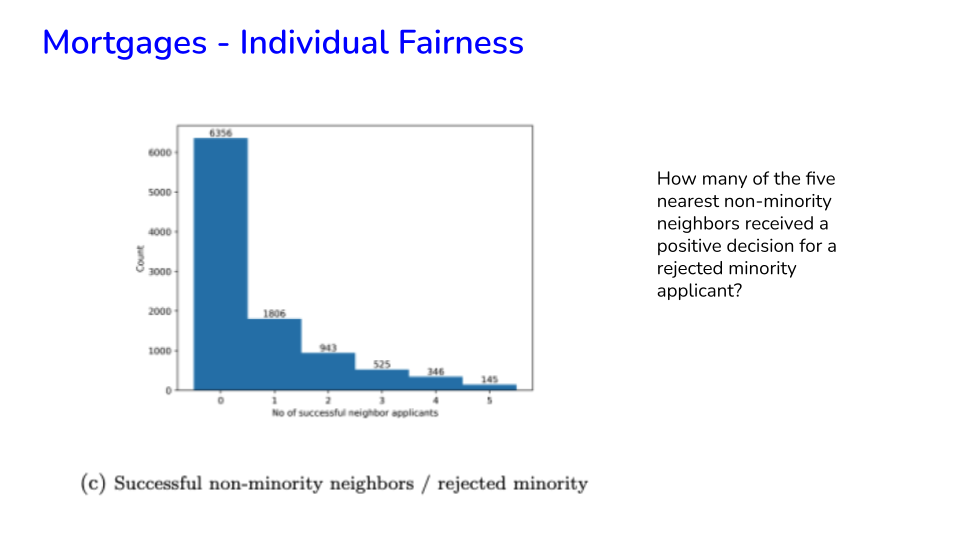
49.16. Mortgages - Individual Fairness#
Image('NLP_images/mortgage_individual_fairness1.png', width=800)
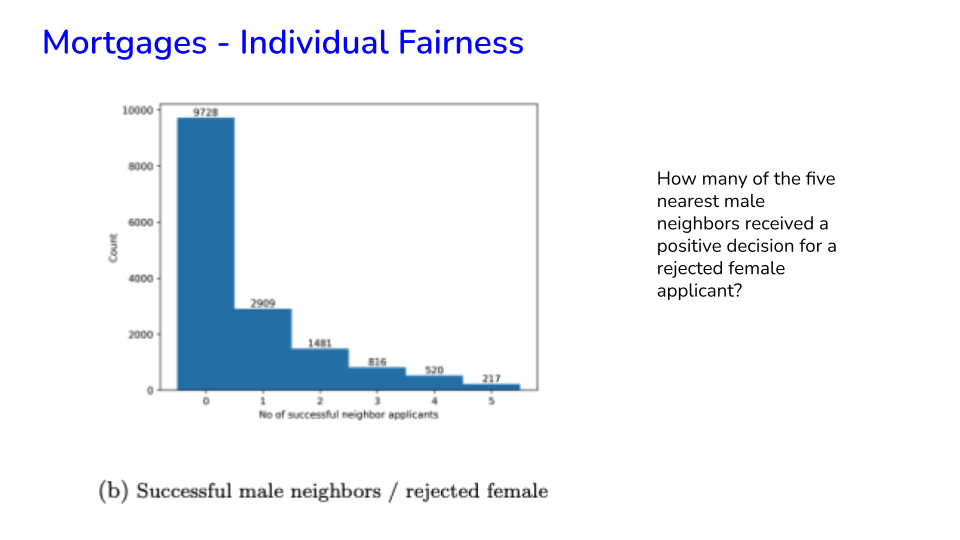
Image('NLP_images/mortgage_individual_fairness2.png', width=800)
Image('NLP_images/mortgage_individual_fairness3.png', width=800)
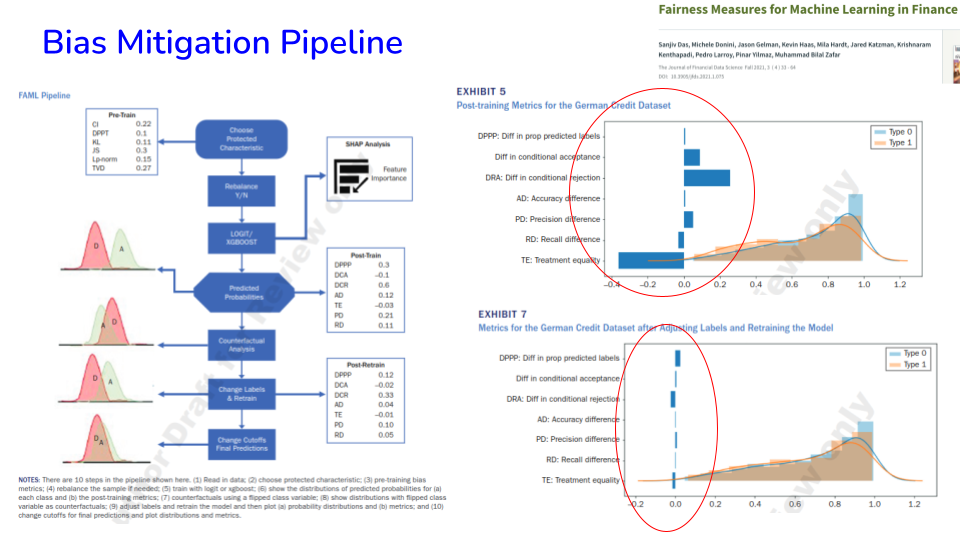
49.17. Bias Remediation/Mitigation#
Rebalancing datasets
Dropping group-correlated features/variables
Changing classifier cut offs (affirmative action)
Changing labels and retraining the classifier Others?
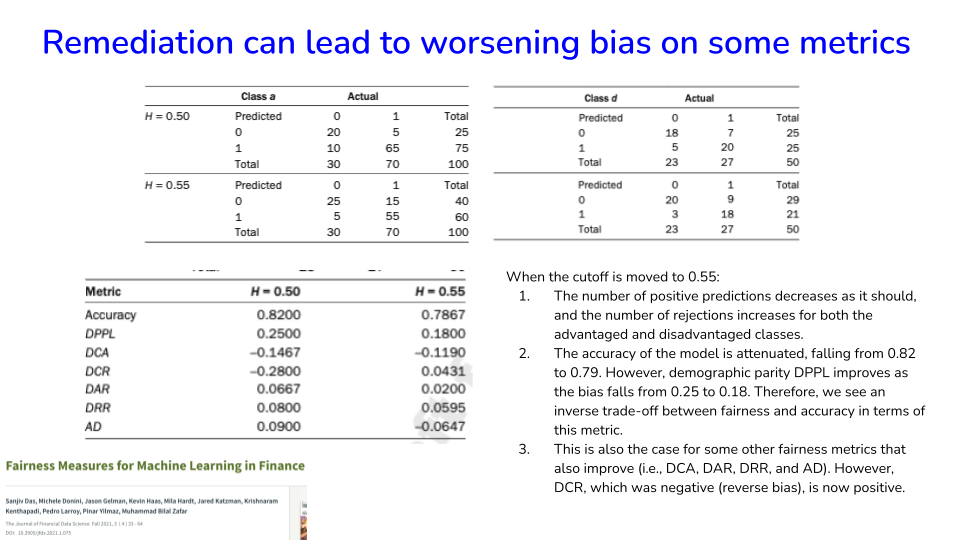
Reducing bias on one metric may increase it on others
What remedy we choose depends on our value systems
Image('NLP_images/bias_mitigation_pipeline.png', width=800)
Image('NLP_images/bias_mitigation_issues.png', width=800)
49.18. Future Issues#
Additional data modalities. Many of the metrics are feature-agnostic and are extendable to other modalities that are increasingly used in financial analyses, such as text. Future work on bias assessment in language models may soon become widespread, with metrics such as accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency suggested in Liang et al. (2022).
Regulatory harmonization for AI/ML use in consumer lending. The dominance of logistic regression in the underwriting practices of regulated financial institutions, despite increasing evidence of the superiority of more flexible machine-learning techniques in credit scoring (see Szepannek 2017, Fuster et al. 2022, Molinar 2022, FinRegLab 2021), suggests there is a need for further research to develop policies that would achieve greater regulatory harmonization under SR 11-7 for “best practice” AI/ML consumer lending applications as well as developing well-vetted standard metrics for group and individual fairness, explainability, and auditability.
De-biasing mortgage data. Many, if not all, historical mortgage data sets exhibit significant deficiencies in the quality and availability of adequate credit reporting for ethnic and racial minorities (see Blattner & Nelson 2021), evidence of the long-term negative effects of redlining on property values and access to credit (see Aliprantis et al. 2023, Aaronson et al. 2021, Cutler et al. 1999), and significant sorting and racial disparities in property valuation assessments (see Avenancio-Leon & Howard 2022, McMillen & Singh 2020, Perry et al. 2018). The effect of these imbalances in existing datasets deserves more study as does the identification of new data sources that allow for the measurement of responsible financial behavior and lower credit risks amongst poorly served borrower populations.
49.19. Summary of Algorithmic Fairness#
What is bias depends on our value system
Group Fairness vs Individual Fairness
Dataset bias vs Classifier bias
Check for Simpson’s Paradox
How we mitigate bias depends on our value system
Privacy promotes fairness
It is time to engage ethicists
References:
AWS Clarify: https://aws.amazon.com/sagemaker/clarify/
Fairness measures in finance: https://jfds.pm-research.com/content/3/4/33 (paper)
49.20. Privacy Issues#
A terrific set of slides on Privacy in AI: https://docs.google.com/presentation/d/1WzQnSjBKXR_alJpRboh87A5xm7cCzrSJZRktKyxpAes/edit#slide=id.p
Paper at Interspeech 2023: “Utility-Preserving Privacy-Enabled Speech Embeddings for Emotion Detection” https://www.isca-speech.org/archive/interspeech_2023/lavania23_interspeech.html
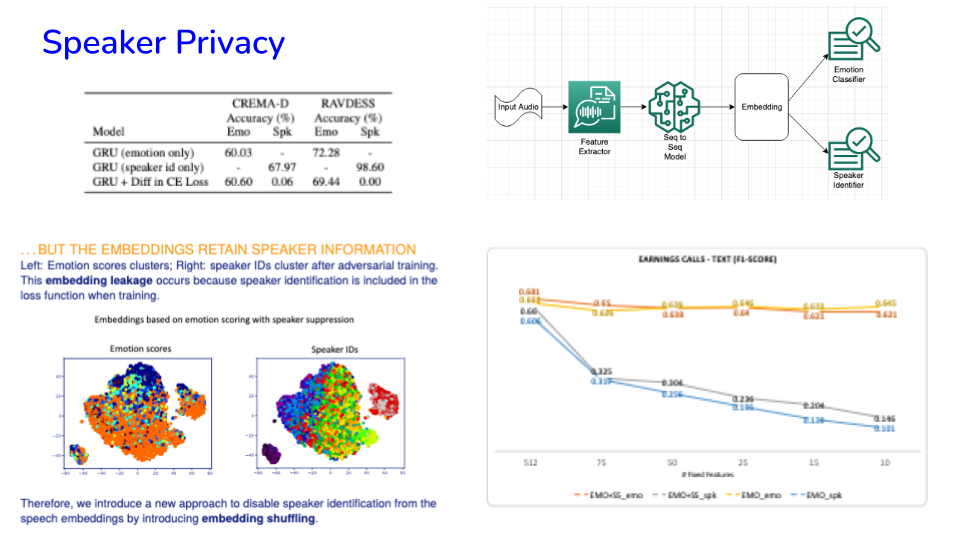
▶ Audio privacy has been undertaken using adversarial task training or adversarial models based on GANs, where the models also suppress scoring of other attributes (e.g., emotion, etc.), but embeddings still retain enough information to bypass speaker privacy.
▶ We use methods for feature importance from the explainability literature to modify embeddings from adversarial task training, providing a simple and accurate approach to generating embeddings for preserving speaker privacy while not attenuating utility for related tasks (e.g., emotion recognition).
▶ The approach selectively shuffles some dimensions of the speech embedding to achieve the paper’s goals.
▶ This enables better adherence with privacy regulations around biometrics and voiceprints, while retaining the usefulness of audio representation learning.
Image('NLP_images/speech_privacy.png', width=800)
49.21. Generative AI Issues#
Image('NLP_images/gen_ai_issues1.png', width=800)

Image('NLP_images/gen_ai_issues2.png', width=800)
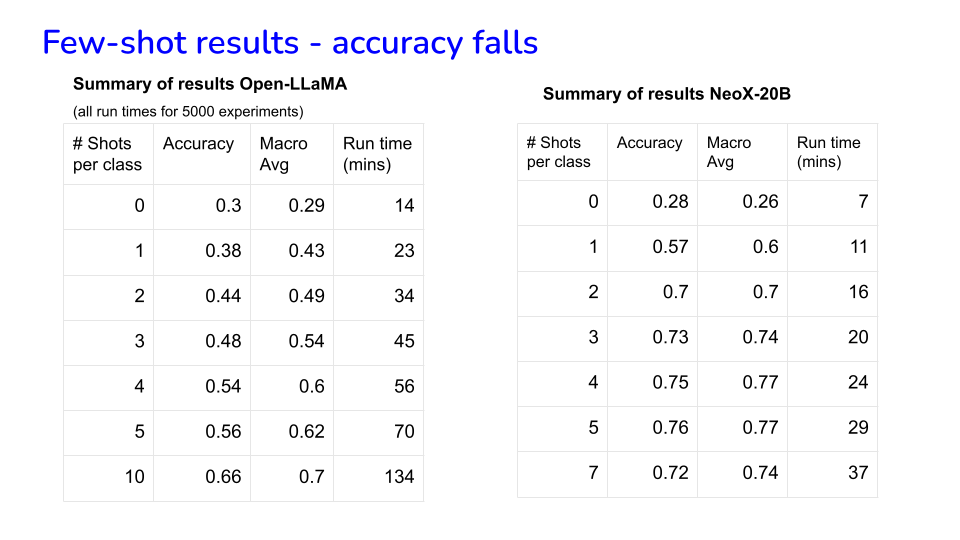
49.22. Evaluating LLMs for Bias#
There are approaches for evaluating LLMs for attributes like toxicity, bias, accuracy, etc.
Anthropic specified the Three Hs for LLMs:
Harmless: A harmless AI will not be offensive or discriminatory, and when asked to aid in a dangerous act, the AI should politely refuse.
Honest: An honest AI will give accurate information, and not hallucinate or confabulate.
Helpful: A helpful AI will attempt to perform the task or answer the question posed.
Holistic Evaluation of Language Models HELM from Stanford is a comprehensive suite for evaluating LLMs. Github: stanford-crfm/helm; Quickstart docs: https://crfm-helm.readthedocs.io/en/latest/
Another suite for evaluation is from Eleuther AI. See the Github repo for their Evaluation Harness.
49.23. AI Transparency#
The Foundation Model Transparency Index (FTMI):
https://hai.stanford.edu/news/introducing-foundation-model-transparency-index
Blog (Sayash Kapoor, lead author): https://www.aisnakeoil.com/p/how-transparent-are-foundation-model
A critique of the same:
The main critiques are:
It mainly measures documentation not transparency.
It presents a score that people may try to optimize but does not really address transparency. Transparency should be a tool not a goal.
It is biased against open models, but still shows them to be more transparent than closed models.
Does not engage with criticisms adequately. Transparency does not equate to responsibility. Trapsarency washing gives the illusion of progressive improvement in responsible AI. Transparency may be detrimental to privacy. The trade off with IP rights is not considered.
49.24. HELM Example#
Run this code below on your local machine
# Create a virtual environment.
# Only run this the first time.
conda create -n crfm-helm pip
# Activate the virtual environment.
conda activate crfm-helm
# Installation
pip install --upgrade pip
pip install crfm-helm --quiet
# Create a run specs configuration
echo 'entries: [{description: "mmlu:subject=philosophy,model=huggingface/gpt2", priority: 1}]' > run_specs.conf
# Run benchmark
helm-run --conf-paths run_specs.conf --suite v1 --max-eval-instances 10
# Summarize benchmark results
helm-summarize --suite v1
# Start a web server to display benchmark results
helm-server
The server will display on http://localhost:8000/, navigate there!
For reference see the MMLU dataset for evaluation: https://huggingface.co/datasets/lukaemon/mmlu
The HELM metrics: https://crfm-helm.readthedocs.io/en/latest/metrics/