
6. Linear Algebra, Gradients, Optimization#
“Unfortunately, no one can be told what the Matrix is. You have to see it for yourself.” – Morpheus
6.1. Paradigm#
Data Analytics = Problem + Data + Linear Algebra + Probability/Statistics + Calculus + Optimization
A spreadsheet is a matrix
These matrices are huge
… and high-dimensional! Get used to living in hyperspace.
%pylab inline
Populating the interactive namespace from numpy and matplotlib
6.2. Scalars#
Data must be arranged in \(n\)-dimensional arrays known as tensors. There are different types of tensors.
Scalars are single numbers. In Python, we use the numpy package to handle scalars, vectors, and tensors. Let’s create a scalar. We may also think of a scalar as a zero-dimensional array. The function ndim in Python gives you the dimension, as follows.
Note: We did not need to explicitly import the numpy package with all its functions because the command “%pylab inline” above included an import of numpy.
x = array(8)
print('x =',x)
print(type(x))
print('dimension =',x.ndim)
x = 8
<class 'numpy.ndarray'>
dimension = 0
6.3. Vectors#
Vectors are single-dimension arrays. They may contain a large number of elements.
x = array([4,2,6,8,5])
print(type(x))
print('dimension =',x.ndim)
<class 'numpy.ndarray'>
dimension = 1
With vectors, we can also get the shape of the array, and since it is has one dimension, it is also its length.
print('Shape of x =',x.shape)
Shape of x = (5,)
6.4. Matrices#
A matrix is a two-dimensional array. We create a random array below.
x = zeros((5,3))
for i in range(5):
for j in range(3):
x[i,j] = randn()
print(x)
print('Dimension =',x.ndim)
print('Shape = ',x.shape)
[[-0.16200453 0.78232895 0.04786321]
[-1.1244397 -0.29768051 -0.20657126]
[-0.353976 0.63721966 0.20079509]
[ 0.63115897 -0.17553216 0.44293979]
[ 0.60757373 -0.62989199 -0.96329342]]
Dimension = 2
Shape = (5, 3)
6.5. Tensors#
An array that is of dimension three or greater is denoted as a “tensor.” Though, vectors and matrices are also special cases of tensors. We create a 3-D tensor below.
Images are examples of 3-D and 4-D tensors.
x = zeros((5,3,2))
for i in range(5):
for j in range(3):
for k in range(2):
x[i,j,k] = i+j+k
print(x)
print('Dimension =',x.ndim)
print('Shape =',x.shape)
[[[0. 1.]
[1. 2.]
[2. 3.]]
[[1. 2.]
[2. 3.]
[3. 4.]]
[[2. 3.]
[3. 4.]
[4. 5.]]
[[3. 4.]
[4. 5.]
[5. 6.]]
[[4. 5.]
[5. 6.]
[6. 7.]]]
Dimension = 3
Shape = (5, 3, 2)
# Random Tensors
x = random.random((2,3,2,4))
print(x)
print('Dimension =',x.ndim)
print('Shape =',x.shape)
[[[[0.15983878 0.58261791 0.83051153 0.08386798]
[0.91310318 0.39090653 0.28911216 0.02637948]]
[[0.95047391 0.22876563 0.40964133 0.48405095]
[0.65561873 0.22179765 0.5510944 0.78122707]]
[[0.71065569 0.5358939 0.37235327 0.1584908 ]
[0.51639935 0.48146831 0.63951073 0.98220494]]]
[[[0.52227406 0.36737387 0.02262277 0.40974115]
[0.77561438 0.24843458 0.88807052 0.82406117]]
[[0.46369898 0.19504413 0.91355493 0.2132806 ]
[0.60643143 0.05997681 0.34321966 0.70220428]]
[[0.46569707 0.63304796 0.30408648 0.19827645]
[0.55498963 0.04253001 0.83558694 0.08438247]]]]
Dimension = 4
Shape = (2, 3, 2, 4)
6.6. Dot Product#
The dot product of two vectors is the element-wise multiplication of the vectors and then a sum of the products. We write this as
#dot product
x = array([1,2,3])
y = array([4,1,7])
print(x.dot(y)) #Method approach
print(dot(x,y)) #Functional syntax
27
27
6.7. Norm of a vector#
For a vector \(x = [x_1,x_2,...,x_n]^\top\), the norm is written as
6.8. Euclidian Distance#
This is a line of sight distance between two points in any dimension system. Given two coordinate points in space, \(x = [x_1,...,x_n]\) and \(y = [y_1,...,y_n]\), the distance is
distance = sqrt(sum((x-y)**2))
print(distance)
linalg.norm(x-y)
5.0990195135927845
np.float64(5.0990195135927845)
6.9. Cosine of the angle between vectors#
This is written as follows for the angle \(\theta\) between two vectors, \(x\) and \(y\):
Where is this used?
x = array([1,2,3])
y = array([4,1,7])
cos_ine = x.dot(y)/sqrt(x.dot(x) * y.dot(y))
print('Cos(theta) =',cos_ine)
from scipy import spatial
cos_ine = 1 - spatial.distance.cosine(x,y)
print('Check = ',cos_ine)
Cos(theta) = 0.8882347881956881
Check = 0.8882347881956881
6.10. Matrix Products#
We can also take the product of a matrix and a vector. The shapes have to be compatible, i.e., the inner dimensions must match as we see in the next example.
x = array([[1,2,3],[4,5,6]])
y = array([4,1,7])
print(x.shape, y.shape)
print(x.dot(y))
(2, 3) (3,)
[27 63]
Here is the product of a matrix and another matrix. The result has the dimension of the left dimension of the first matrix and the right dimension of the second.
#matrix multiply
x = array([[1,2,3],[4,5,6]])
y = array([[4,1,7,4],[1,2,3,4],[4,6,8,1]])
print(x.shape, y.shape)
z = x.dot(y)
print('z =',z)
print(z.shape)
(2, 3) (3, 4)
z = [[18 23 37 15]
[45 50 91 42]]
(2, 4)
#tensor products with matrix
x = random.random((2,3,2,4))
y = random.random((4,2))
print(x.shape, y.shape)
z = x.dot(y)
print(z)
print(z.shape)
(2, 3, 2, 4) (4, 2)
[[[[0.98665299 1.01905555]
[1.08593253 1.35326031]]
[[0.68584939 0.43611016]
[1.44141468 1.3617148 ]]
[[1.46097994 1.36403753]
[1.0952081 1.17115212]]]
[[[1.10709595 1.04003445]
[1.28615038 1.2547219 ]]
[[1.18023265 1.24981444]
[0.96851308 1.10685196]]
[[0.48319574 0.44754988]
[1.13351557 0.90092627]]]]
(2, 3, 2, 2)
x = random.random((2,3,4))
y = random.random((4,3))
print(x.shape, y.shape)
z = x.dot(y)
print(z)
print(z.shape)
(2, 3, 4) (4, 3)
[[[1.90841348 1.7922434 0.828617 ]
[1.70630754 1.3860632 0.55857831]
[1.19413711 0.99705278 0.60627032]]
[[1.3518279 1.43054538 0.39908749]
[1.23943769 0.80165486 0.82414443]
[0.46772297 0.19883133 0.3290058 ]]]
(2, 3, 3)
6.11. Reshaping tensors#
It is easy to do this in numpy.
z.reshape((2,9))
array([[1.90841348, 1.7922434 , 0.828617 , 1.70630754, 1.3860632 ,
0.55857831, 1.19413711, 0.99705278, 0.60627032],
[1.3518279 , 1.43054538, 0.39908749, 1.23943769, 0.80165486,
0.82414443, 0.46772297, 0.19883133, 0.3290058 ]])
6.12. Transpose#
When we transpose a matrix, we interchange its rows and columns.
x = random.random((5,3))
print('x =',x)
print('Transpose =',x.T)
x = [[0.97662609 0.33487366 0.11371403]
[0.22039645 0.73620222 0.20576212]
[0.28634413 0.30648751 0.99208471]
[0.62753711 0.49660017 0.43124998]
[0.36059471 0.56750492 0.88211686]]
Transpose = [[0.97662609 0.22039645 0.28634413 0.62753711 0.36059471]
[0.33487366 0.73620222 0.30648751 0.49660017 0.56750492]
[0.11371403 0.20576212 0.99208471 0.43124998 0.88211686]]
6.13. Rank#
The rank of a matrix is the minimum number of independent rows and columns it has. Within numpy is a linear algebra module linalg which we call below.
rank_x = linalg.matrix_rank(x)
print('Rank =',rank_x)
Rank = 3
x = array([[1,2,3],[2,4,6],[5,3,1]])
rank_x = linalg.matrix_rank(x)
print('Rank =',rank_x)
Rank = 2
6.14. Inverse by hand#
Let’s take a 2x2 matrix \(A\), and it’s inverse is denoted as \(A^{-1}\), such that \(A · A^{-1} = I\), where \(I\) is the identity matrix, i.e.,
A = array([[1,4],[3,2]])
print(A)
print(inv(A))
byhand = 1/(1*2-4*3)*array([[2,-4],[-3,1]])
print(byhand)
[[1 4]
[3 2]]
[[-0.2 0.4]
[ 0.3 -0.1]]
[[-0.2 0.4]
[ 0.3 -0.1]]
6.15. Inverse in higher dimension#
The inverse of a matrix is its “reciprocal” in a sense. So if we multiply a matrix by its inverse, we get the matrix form of 1, i.e., the identity matrix.
x = random.random((3,3))
print('x =',x)
rank_x = linalg.matrix_rank(x)
print('Rank =',rank_x)
inv_x = inv(x)
print('Inverse =',inv_x)
print('x times inverse(x)')
print(x.dot(inv_x).round(2))
x = [[0.62614009 0.77432052 0.41211118]
[0.87475501 0.59186713 0.97458777]
[0.97771788 0.06728219 0.72405027]]
Rank = 3
Inverse = [[ 1.39365579 -2.04619583 1.96099134]
[ 1.22677198 0.19362494 -0.95887119]
[-1.99591403 2.74507839 -1.17779301]]
x times inverse(x)
[[ 1. 0. -0.]
[-0. 1. -0.]
[-0. 0. 1.]]
You cannot take the inverse of a matrix if it is not of full rank, try this with the previous example and check.
6.16. Applications of the Inverse#
We may solve systems of linear equations using the matrix inverse. In finance, this is used in bond markets to get the prices of unit bonds.
Example: bonds paying interest every half year.
0.5 year bond, price = 100, coupon = 5%
1.0 year bond, price = 100, coupon = 6%
1.5 year bond, price = 101, coupon = 7%
2.0 year bond, price = 99.5, coupon = 7.5%
What is the price of a 2 year bond that pays 25 every half year?
Cmat = array([[102.5,0,0,0],[3,103,0,0],[3.5,3.5,103.5,0],[3.75,3.75,3.75,103.75]])
print("Rank = ",linalg.matrix_rank(Cmat))
Pmat = array([100,100,101,99.5])
Qmat = inv(Cmat).dot(Pmat)
print(Qmat)
newC = ones(4)*25
print('Price new = ',newC.dot(Qmat))
Rank = 4
[0.97560976 0.94245797 0.91098322 0.85678129]
Price new = 92.14580581727638
6.17. Basis#
\({\hat i}\) is the vector \([1,0]^\top\) in a 2-D system. Likewise, \({\hat j}\) is the vector \([0,1]^\top\).
Any vector can be written in terms of these two vectors, i.e., a vector \([4,-3]^\top\) may be written as
Thus, the coordinate system can be reframed in terms of the two standard vectors, which we call “basis vectors.” The set of basis vectors is simply called “the basis.”
All vectors in the system are linear combinations of the basis vectors.
We could have chosen any other two vectors \(v_1, v_2\) to form the basis, other than \({\hat i}, {\hat j}\). The same point in 2-D space would then be a combination of the new basis vectors with different scalar weights.
6.18. Span#
The “span” of two basis vectors \(v_1,v_2\) is the set of all possible vectors \(v\) that can be generated by linear combinations of these vectors, i.e.,
The span depends on the range of values allowed for \(a,b\). For unrestricted \(a,b\), the span is all of 2-D space.
Q: what is the span when the angle between \(v_1,v_2\) is zero?
We see that \(v_1,v_2\) are linearly independent.
Therefore, the basis of a \(n\)-dimensional vector space is a set of \(n\) linearly independent vectors than span the full \(n\)-D space.
6.19. Linear Transformations#
A linear transformation is a function that maps a vector into a new vector.
If you think of a vector as a point in \(n\)-D space, then applying the same function to all points in the point cloud will move them all around the space into a new configuration. Each original vector becomes a new one.
Note that the origin remains in place.
Suppose, in 2-D space, we had a vector \(v = a {\hat i} + b {\hat j} = \left[\begin{array}{c} a \\ b \end{array} \right]\). If we apply a linear transformation to this space that moves \({\hat i} → i\) and \({\hat j} → j\), then it will actually just move \(v \rightarrow ai + bj\).
Note that \({\hat i},{\hat j},i,j\) are all vectors in 2-D space, i.e., defined by a pair of coordinates. We can stack these into a matrix:
So we see that $\( v → a \left[\begin{array}{c} i_1 \\ i_2 \end{array} \right] + b \left[\begin{array}{c} j_1 \\ j_2 \end{array} \right] = \left[\begin{array}{c} v_1 \\ v_2 \end{array} \right] \)$
The new vector \(v\) is nothing but \(M v\).
6.20. Rotation of Axes#
Assume a 2-D vector space.
Let \({\hat i} = \left[\begin{array}{c} 1 \\ 0 \end{array} \right]\) and \({\hat j} = \left[\begin{array}{c} 0 \\ 1 \end{array} \right]\). This is the classic coordinate system.
Suppose we rotate the coordinate system 90 degrees to the left. Then \({\hat i}\) moves to \(i = \left[\begin{array}{c} 0 \\ 1 \end{array} \right]\) and \({\hat j}\) moves to \(j = \left[\begin{array}{c} -1 \\ 0 \end{array} \right]\).
Where does the vector (point) \(\left[\begin{array}{c} 4 \\ -3 \end{array} \right]\) go?
6.21. Shear#
What if both basis vectors don’t rotate equally? Then we get a “shear” or a slanted grid.
Let \({\hat i} = \left[\begin{array}{c} 1 \\ 0 \end{array} \right]\) and \({\hat j} = \left[\begin{array}{c} 0 \\ 1 \end{array} \right]\). This is the classic coordinate system.
Suppose we only rotate \({\hat j}\) 45 degrees to the right. Then \({\hat i}\) stays at \(i = \left[\begin{array}{c} 1 \\ 0 \end{array} \right]\) and \({\hat j}\) moves to \(j = \left[\begin{array}{c} 1 \\ 1 \end{array} \right]\).
Where does the vector (point) \(\left[\begin{array}{c} 4 \\ -3 \end{array} \right]\) go?
#generate many points in 2-D space
m = 200
x = randn(m)
y = rand(m)*x + randn(m)
scatter(x,y)
grid()
#Apply a linear transformation
A = array([[1,0],[1,1]])
print(A)
print(x[:5])
print(y[:5])
z = append(x,y).reshape((2,m)).T
print(z.shape)
print(z[:5])
znew = z.dot(A)
print(znew[:5])
[[1 0]
[1 1]]
[-0.13330346 1.15250321 1.08028375 0.57208931 -2.11278019]
[ 0.21449408 1.70966199 -0.1551279 0.54118473 0.30186061]
(200, 2)
[[-0.13330346 0.21449408]
[ 1.15250321 1.70966199]
[ 1.08028375 -0.1551279 ]
[ 0.57208931 0.54118473]
[-2.11278019 0.30186061]]
[[ 0.08119062 0.21449408]
[ 2.8621652 1.70966199]
[ 0.92515585 -0.1551279 ]
[ 1.11327404 0.54118473]
[-1.81091958 0.30186061]]
scatter(znew[:,0],znew[:,1])
grid()
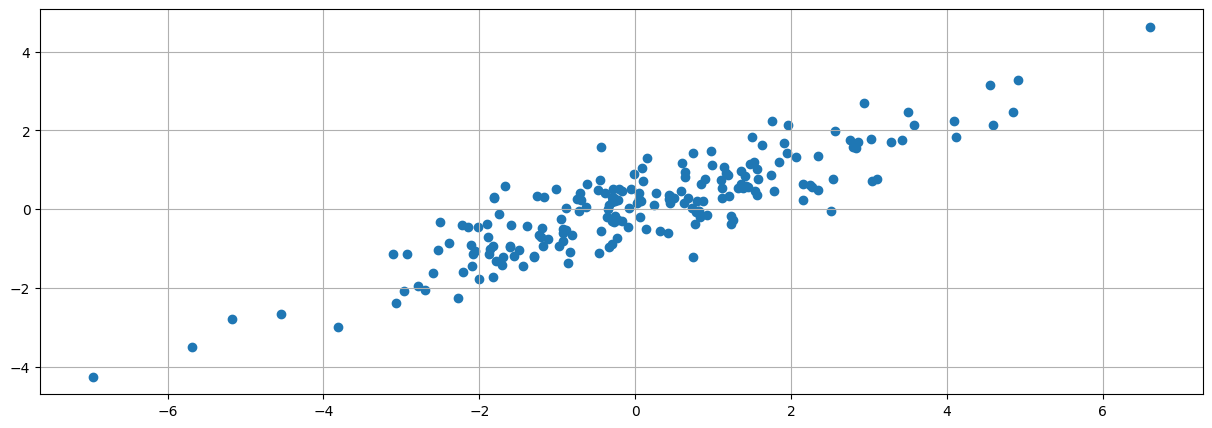
#Apply a linear transformation 2
A = array([[1,0],[1,-1]])
z = append(x,y).reshape((2,m)).T
znew = z.dot(A)
scatter(znew[:,0],znew[:,1])
grid()
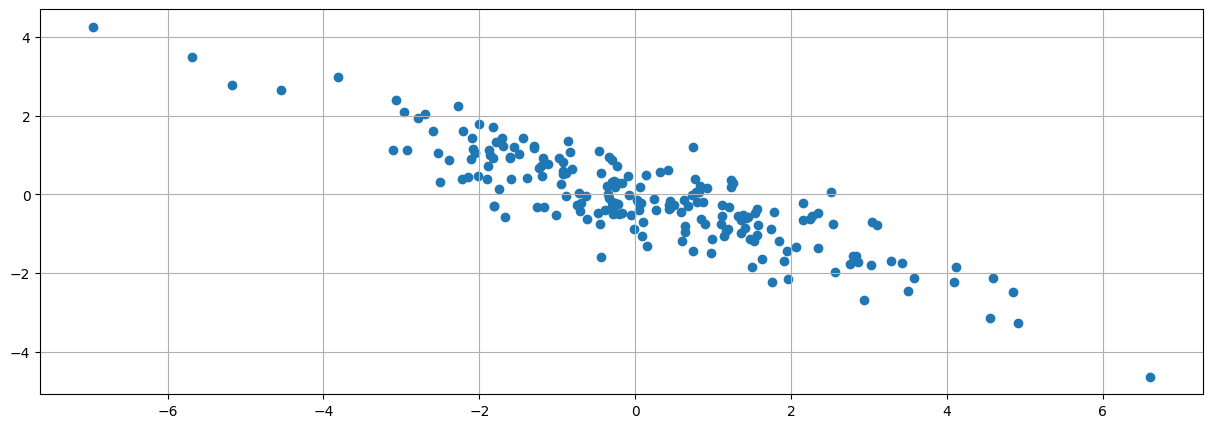
#Apply a rotation 90 degrees left
A = array([[0,1],[-1,0]])
z = append(x,y).reshape((2,m)).T
znew = z.dot(A)
scatter(znew[:,0],znew[:,1])
grid()
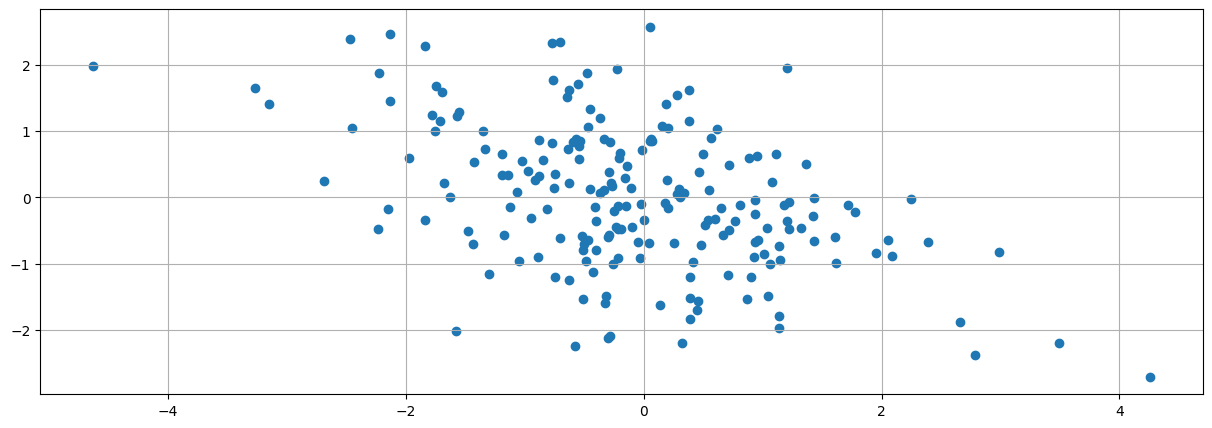
Multiplying the vectors in a cartesian space by a matrix gives the transformed points in a new vector space with a new basis
Linear transformation are matrix functions that take vectors as inputs and produce vectors as outputs
They give a new space in which grid lines remain parallel and evenly spaced.
How do you describe a linear transformation that is a rotation followed by a shear? This is called a composition.
Are compositions commutative and associative?
6.22. Determinants#
Linear transformations are done with a matrix (function). Some of these expand the space, others contract and distort it. (We also have rotations.) The determinant tells us by how much space is expanded or shrunk.
in 2-D, if you look at the change in area of the unit square from the transformation, it gives you an idea of how the area is compressed or expanded across the entire vector space.
The determinant of a matrix is a way of reducing it to a single number that gives a sense of its size or “volume.” The volume of a unit matrix will be 1.
This is the signed area of a parallelogram flanked by two vectors from the origin: \((a,b)\) and \((c,d)\). This shows up in the inverse also:
Because multiplication by the inverse gives an identity matrix, we see that the formula for the inverse contains the division by the determinant as a normalization factor!
x = array([[1,0],[0,1]])
print('Determinant(x) =',det(x))
Determinant(x) = 1.0
x = array([[1,0,0],[0,1,0],[0,0,1]])
print('Determinant(x) =',det(x))
Determinant(x) = 1.0
#Switching two rows or columns changes sign
x = array([[1,0,0],[0,0,1],[0,1,0]])
print('Determinant(x) =',det(x))
Determinant(x) = -1.0
x = array([[1,0],[0,2]])
print('Determinant(x) =',det(x))
Determinant(x) = 2.0
x = array([[2,0],[0,2]])
print('Determinant(x) =',det(x))
Determinant(x) = 4.0
x = array([[1,0,0],[0,2,0],[0,0,3]])
print('Determinant(x) =',det(x))
Determinant(x) = 6.0
x = array([[1,4],[3,2]])
print(x)
print(det(x))
x = array([[3,2],[1,4]])
print(x)
det(x)
[[1 4]
[3 2]]
-10.000000000000002
[[3 2]
[1 4]]
np.float64(10.000000000000002)
#Volume of a parallelepiped
x = array([[1,1,1],[1,2,1],[1,1,3]])
print('Determinant(x) =',det(x))
x = x - 0.5; print(x)
print('Determinant(x) =',det(x))
Determinant(x) = 2.0
[[0.5 0.5 0.5]
[0.5 1.5 0.5]
[0.5 0.5 2.5]]
Determinant(x) = 1.0
#Rotation
x = array([[0,-1],[1,0]])
print(x)
print(det(x))
[[ 0 -1]
[ 1 0]]
1.0
#Shear 1
x = array([[1,1],[0,1]])
print(x)
print(det(x))
#Shear 2
x = array([[1,0.5],[0,0.5]])
print(x)
print(det(x))
[[1 1]
[0 1]]
1.0
[[1. 0.5]
[0. 0.5]]
0.5
6.23. Singular Matrix#
A matrix is singular if its determinant is zero.
It follows that a singular matrix does not have an inverse.
x = array([[1,2],[2,4]])
print(det(x))
try:
inv(x)
except:
print('singular matrix')
0.0
singular matrix
6.24. Determinants in Probability Functions#
The determinant appears in probability functions like the multivariate normal distribution. The univariate normal probability density function (pdf) is
The probability density function for a vector of random variables \(x=[x_1,x_2,...,x_n]^\top\) is:
Note how the determinant of the covariance matrix is needed for the multivariate model in place of the variance from the univariate model.
The bivariate normal pdf is
Note also that the term \(\sqrt{(x-\mu)^\top \Sigma^{-1} (x-\mu)}\) is known as the Mahalonobis Distance.
6.25. Portfolio Calculations using Vectors and Matrices#
It is useful to examine the power of using vector algebra with an application.
In order to compute the mean and variance of the portfolio return, we need to use the portfolio weights \({\bf w}\) and the covariance matrix of stock returns \({\bf R}\), denoted \({\bf \Sigma}\). The mean return of each stock in the portfolio is carried in a vector \({\bf \mu}\).
What is covariance and correlation?
6.26. Mean Return#
The weighted return is a vector computed as follows:
This is a random vector.
Each element of \({\bf R}\) comes from its own distribution.
They are coupled into a joint distribution using mean returns \({\bf \mu}\), to get a mean portfolio return of
6.27. Covariance and Correlation#
The covariance is the difference of two dot products for two vectors \(x,y\):
Variance is
Correlation is
x = randn(10000)
y = x + rand(10000)
print(cov(x,y))
print(corrcoef(x,y))
[[1.00473337 1.00057224]
[1.00057224 1.07999454]]
[[1. 0.96053293]
[0.96053293 1. ]]
x = randn(10000)
x = x.reshape(5,2000)
cov(x)
cov(x).shape
(5, 5)
6.28. Covariance of stock returns#
We note that the elements of the covariance matrix are \(\Sigma_{ij}\). Note that \(\sigma_{i}^2 = \Sigma_{ii}\).
We first write down the formula for a portfolio’s return variance:
You are strongly encouraged to implement this by hand for \(n=2\) to convince yourself that the vector form of the expression for variance \(\boldsymbol{w'\Sigma w}\) is the same thing as the long form on the right-hand side of the equation above.
6.28.1. Independent Returns#
If returns are independent, then the formula collapses to:
6.28.2. Dependent Returns#
If returns are dependent, and equal amounts are invested in each asset (\(w_i=1/n,\;\;\forall i\)):
6.29. Diversification in a stock portfolio#
Here we use vector and summation math to understand how diversification in stock portfolios works. Diversification occurs when we increase the number of non-perfectly correlated stocks in a portfolio, thereby reducing portfolio variance.
An Essential Insight
The first term is the average variance, denoted \(\bar{\sigma_1}^2\) divided by \(n\), and the second is the average covariance, denoted \(\bar{\sigma_{ij}}\) multiplied by factor \((n-1)/n\). As \(n \rightarrow \infty\),
This produces the remarkable result that in a well diversified portfolio, the variances of each stock’s return does not matter at all for portfolio risk! Further the risk of the portfolio, i.e., its variance, is nothing but the average of off-diagonal terms in the covariance matrix.
### Computing the portfolio standard deviation
### as n increases®
sd=0.20; cv=0.01; m=100
n = range(1,m+1)
sd_p = zeros(m)
for j in n:
cv_mat = matrix(ones((j,j))*cv)
fill_diagonal(cv_mat,sd**2)
w = matrix(ones(j)*(1.0/j)).T
sd_p[j-1] = sqrt((w.T).dot(cv_mat).dot(w))
/tmp/ipython-input-1800866969.py:11: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
sd_p[j-1] = sqrt((w.T).dot(cv_mat).dot(w))
### Plot risk as n increases
rcParams['figure.figsize'] = 15,5
plot(n,sd_p)
xlabel('#stocks')
ylabel('stddev of portfolio')
grid()
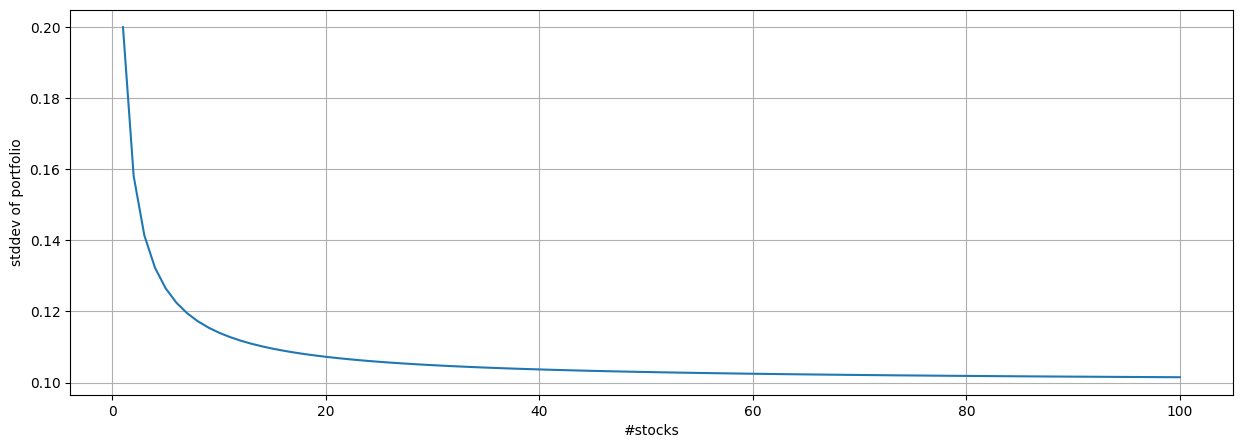
The asymptote is the level of systematic risk, after all security-specific (idiosyncractic) risk has been diversified away.
6.30. Do we still get diversification if the weights are not 1/n?#
Assume 100 stocks, indexed by \(k\).
Invest in all the stocks in proportion to the index \(k\), i.e., invest 1 in the first, 2 in the second, …, and 100 in the last stock.
The total invested would be \(\sum_{k=1}^{100} k = 5050\) so that the stock with the largest proportion would be the last one, with a share of \(100/5050 = 0.0198\). So there is hardly much invested in any one stock, as we can see.
Thus, once \(k\) is large, we do get sufficient diversification.
print(100/sum(range(1,101)))
0.019801980198019802
6.31. Multivariate Linear Functions#
The simplest linear functions are dot products.
The function \(f = 3 x_1 + 2 x_2 + 7 x_3\) may be written as \(f = a^\top · x\) where \(a=[3,2,7]\) and \(x=[x_1,x_2,x_3]\).
The gradient of \(f\) with respect to \(x\) is \(a\). It comprises 3 components:
6.32. Quadratic Functions#
What sort of function is
Is it a scalar function or a vector?
Suppose \(x = [x_1,x_2]^\top\) and \(A = \left[\begin{array}{cc} 2 & 3 \\ 1 & 8 \end{array} \right]\).
Write out \(f\) completely.
Gradient is
6.33. Vector Calculus#
Almost always, you can treat the matrices and vectors as scalars to differentiate these functions. But you have to be careful. When we had the function \(f = a · x\), the derivative was \(\frac{\partial f}{∂ x} = a\).
But when we had \(f = x^⊤ · A · x\) the derivative is actually the following:
Check this by hand!
6.34. Minimize the function above#
Use first-order conditions equal to zero.
a = array([[4,4],[4,16]])
print(a)
b = array([0,0])
linalg.solve(a,b)
[[ 4 4]
[ 4 16]]
array([0., 0.])
from scipy.optimize import minimize
def f(x,A):
return x.dot(A).dot(x)
x = array([1,1])
A = array([[2,3],[1,8]])
print(f(x,A))
sol = minimize(f,[1.0,1.0],A)
sol
14
message: Optimization terminated successfully.
success: True
status: 0
fun: 4.413984996660949e-16
x: [-1.210e-11 -7.425e-09]
nit: 4
jac: [ 5.412e-11 3.617e-10]
hess_inv: [[ 3.333e-01 -8.333e-02]
[-8.333e-02 8.333e-02]]
nfev: 18
njev: 6
6.35. Gradient Descent#
x1 = linspace(-3,3,101)
x2 = linspace(-3,3,101)
fn = zeros((101,101))
for i in range(101):
for j in range(101):
x = array([x1[i],x2[j]])
fn[i,j] = f(x,A)
from mpl_toolkits.mplot3d import Axes3D
fig = figure()
ax = fig.add_subplot(projection='3d')
# Plot the surface.
surf = ax.plot_surface(x1, x2, fn, cmap=cm.coolwarm, linewidth=0, antialiased=False)
The gradient descent update is
eta = 0.1 #learning rate
x1 = 2; x2 = 2 #initial values
for t in range(30):
g1 = 4*x1 + 4*x2
g2 = 4*x1 + 16*x2
x1 = x1 - eta*g1
x2 = x2 - eta*g2
x = array([x1,x2])
print('t =',t,'x1 =',x1,'x2 =',x2,'fn =',f(x,A))
t = 0 x1 = 0.3999999999999999 x2 = -2.0 fn = 29.12
t = 1 x1 = 1.04 x2 = 1.04 fn = 15.142400000000002
t = 2 x1 = 0.20799999999999996 x2 = -1.04 fn = 7.874048
t = 3 x1 = 0.5408 x2 = 0.5408 fn = 4.094504959999999
t = 4 x1 = 0.10815999999999998 x2 = -0.5408 fn = 2.1291425791999994
t = 5 x1 = 0.28121599999999997 x2 = 0.28121600000000013 fn = 1.1071541411840007
t = 6 x1 = 0.05624319999999994 x2 = -0.281216 fn = 0.5757201534156802
t = 7 x1 = 0.14623231999999997 x2 = 0.14623232000000008 fn = 0.2993744797761538
t = 8 x1 = 0.029246463999999944 x2 = -0.14623232000000003 fn = 0.15567472948359995
t = 9 x1 = 0.07604080639999998 x2 = 0.07604080640000005 fn = 0.080950859331472
t = 10 x1 = 0.015208161279999959 x2 = -0.07604080640000005 fn = 0.04209444685236548
t = 11 x1 = 0.039541219328 x2 = 0.039541219328000046 fn = 0.021889112363230045
t = 12 x1 = 0.007908243865599983 x2 = -0.03954121932800003 fn = 0.011382338428879627
t = 13 x1 = 0.020561434050560004 x2 = 0.020561434050560025 fn = 0.005918815983017406
t = 14 x1 = 0.004112286810111991 x2 = -0.020561434050560018 fn = 0.0030777843111690515
t = 15 x1 = 0.010691945706291202 x2 = 0.010691945706291214 fn = 0.0016004478418079069
t = 16 x1 = 0.0021383891412582352 x2 = -0.01069194570629121 fn = 0.0008322328777401117
t = 17 x1 = 0.005559811767271426 x2 = 0.005559811767271435 fn = 0.0004327610964248584
t = 18 x1 = 0.0011119623534542817 x2 = -0.005559811767271432 fn = 0.00022503577014092643
t = 19 x1 = 0.0028911021189811418 x2 = 0.0028911021189811474 fn = 0.0001170186004732818
t = 20 x1 = 0.0005782204237962259 x2 = -0.0028911021189811457 fn = 6.0849672246106566e-05
t = 21 x1 = 0.0015033731018701938 x2 = 0.0015033731018701969 fn = 3.164182956797541e-05
t = 22 x1 = 0.0003006746203740374 x2 = -0.0015033731018701956 fn = 1.645375137534721e-05
t = 23 x1 = 0.0007817540129725006 x2 = 0.0007817540129725024 fn = 8.555950715180548e-06
t = 24 x1 = 0.0001563508025944994 x2 = -0.0007817540129725017 fn = 4.449094371893886e-06
t = 25 x1 = 0.00040651208674570034 x2 = 0.00040651208674570127 fn = 2.3135290733848205e-06
t = 26 x1 = 8.130241734913968e-05 x2 = -0.00040651208674570094 fn = 1.203035118160107e-06
t = 27 x1 = 0.00021138628510776418 x2 = 0.0002113862851077647 fn = 6.255782614432556e-07
t = 28 x1 = 4.227725702155263e-05 x2 = -0.00021138628510776453 fn = 3.2530069595049306e-07
t = 29 x1 = 0.0001099208682560374 x2 = 0.00010992086825603766 fn = 1.691563618942564e-07
6.36. Euler’s Homogenous Function Theorem#
If a function is linear homogeneous, then
We say that the function is homogeneous of degree 1. If the function was homogeneous of degree 2, then
Is the function above \(f(x,A)\) above homogeneous of degree 1 or 2?
Euler’s formula says that if the function is linear homogeneous then, it may be written equivalently as follows:
6.37. Markowitz’s Nobel Prize#
We are interested in portfolios of \(n\) assets, which have a mean return which we denote as \(E(r_p)\), and a variance, denoted \(Var(r_p)\).
Let \(\underline{w} \in R^n\) be the portfolio weights. What this means is that we allocate each $1 into various assets, such that the total of the weights sums up to 1. Note that we do not preclude short-selling, so that it is possible for weights to be negative as well.
The optimization problem is defined as follows. We wish to find the portfolio that delivers the minimum variance (risk) while achieving a pre-specified level of expected (mean) return.
subject to
Note that we have a \(\frac{1}{2}\) in front of the variance term above, which is for mathematical neatness as will become clear shortly. The minimized solution is not affected by scaling the objective function by a constant.
The first constraint forces the expected return of the portfolio to a specified mean return, denoted \(E(r_p)\), and the second constraint requires that the portfolio weights add up to 1, also known as the “fully invested” constraint. It is convenient that the constraints are equality constraints.
6.37.1. Solution#
This is a Lagrangian problem, and requires that we embed the constraints into the objective function using Lagrangian multipliers \(\{\lambda_1, \lambda_2\}\). This results in the following minimization problem:
To minimize this function, we take derivatives with respect to \(\underline{w}\), \(\lambda_1\), and \(\lambda_2\), to arrive at the first order conditions:
The first equation above, is a system of \(n\) equations, because the derivative is taken with respect to every element of the vector \(\underline{w}\). Hence, we have a total of \((n+2)\) first-order conditions. From (1)
Premultiply (2) by \(\underline{\mu}'\):
Also premultiply (2) by \(\underline{1}'\):
Solve for \(\lambda_1, \lambda_2\)
Note 1: Since \(\underline{\Sigma}\) is positive definite, \(\underline{\Sigma}^{-1}\) is also positive definite: \(B>0, C>0\).
Note 2: Given solutions for \(\lambda_1, \lambda_2\), we solve for \(\underline{w}\).
This is the expression for the optimal portfolio weights that minimize the variance for given expected return \(E(r_p)\). We see that the vectors \(\underline{g}\), \(\underline{h}\) are fixed once we are given the inputs to the problem, i.e., \(\underline{\mu}\) and \(\underline{\Sigma}\).
Note 3: We can vary \(E(r_p)\) to get a set of frontier (efficient or optimal) portfolios \underline{w}.
If \(\quad E(r_p)= 0,\; \underline{w} = \underline{g}\)
If \(\quad E(r_p)= 1,\; \underline{w} = \underline{g}+\underline{h}\)
Note that
Hence these 2 portfolios \(\underline{g}, \underline{g} + \underline{h}\) “generate” the entire frontier.
def markowitz(mu,cv,Er):
n = len(mu)
wuns = ones(n)
cvinv = linalg.inv(cv)
A = wuns.T.dot(cvinv).dot(mu)
B = mu.T.dot(cvinv).dot(mu)
C = wuns.T.dot(cvinv).dot(wuns)
D = B*C - A*A
lam = (C*Er-A)/D
gam = (B-A*Er)/D
wts = lam*(cvinv.dot(mu)) + gam*(cvinv.dot(wuns))
return wts
#PARAMETERS
mu = array([0.02,0.10,0.20])
n = len(mu)
cv = array([0.0001,0,0,0,0.04,0.02,0,0.02,0.16])
cv = cv.reshape(n,n)
print(cv.round(4))
[[1.0e-04 0.0e+00 0.0e+00]
[0.0e+00 4.0e-02 2.0e-02]
[0.0e+00 2.0e-02 1.6e-01]]
Er = 0.18
#SOLVE PORTFOLIO PROBLEM
wts = markowitz(mu,cv,Er)
wts
array([-0.35759312, 0.84366762, 0.5139255 ])
print("Weights = ",wts)
print("Sum of weights = ",sum(wts))
print("Expected return = ",wts.T.dot(mu))
print("Std Dev of return = ",sqrt(wts.T.dot(cv).dot(wts)))
Weights = [-0.35759312 0.84366762 0.5139255 ]
Sum of weights = 1.0000000000000087
Expected return = 0.1799999999999997
Std Dev of return = 0.29679317564888064
#NUMERICAL OPTIMIZATION
from scipy.optimize import minimize
def port_var(w,cv,mu,Er):
return w.T.dot(cv).dot(w)
w0 = array([0.3,0.3,0.4])
cons = ({'type': 'eq', 'fun': lambda x: sum(x)-1.0}, {'type': 'eq', 'fun': lambda x: x.T.dot(mu)-Er})
sol = minimize(port_var,w0,args=(cv,mu,Er),method="SLSQP",constraints=cons)
print(sol.x)
sol
[-0.35759314 0.84366765 0.51392549]
message: Optimization terminated successfully
success: True
status: 0
fun: 0.0880861894164788
x: [-3.576e-01 8.437e-01 5.139e-01]
nit: 5
jac: [-7.152e-05 8.805e-02 1.982e-01]
nfev: 20
njev: 5
multipliers: [-2.210e-02 1.102e+00]
#NUMERICAL OPTIMIZATION WITH NO SHORT SELLING
w0 = array([0.3,0.3,0.4])
cons = ({'type': 'eq', 'fun': lambda x: sum(x)-1}, {'type': 'eq', 'fun': lambda x: x.T.dot(mu)-Er},
{'type': 'ineq', 'fun': lambda x: min(x)-0})
sol = minimize(port_var,w0,args=(cv,mu,Er),method="SLSQP",constraints=cons)
sol
message: Optimization terminated successfully
success: True
status: 0
fun: 0.11040000003958343
x: [-2.082e-17 2.000e-01 8.000e-01]
nit: 3
jac: [ 0.000e+00 4.800e-02 2.640e-01]
nfev: 12
njev: 3
multipliers: [-1.680e-01 2.160e+00 1.248e-01]