
48. Explaining a ML Model using Shapley Values#
In this notebook we explain ML models using the classic framework from game theory, known as Shapley values. This is based on the work from 1951 by game theorist Lloyd Shapley. The original paper is here: https://www.rand.org/content/dam/rand/pubs/research_memoranda/2008/RM670.pdf
See also the Wikipedia entry that is brief and easy to read: https://en.wikipedia.org/wiki/Shapley_value
More recently, the idea has been adopted in computer science to explain ML models, and the paper that launched this idea is the one by Scott Lundberg and Su-In Lee, see: https://arxiv.org/abs/1705.07874
This led to a widely-used open source repository called SHAP: slundberg/shap (this was Lundberg’s PhD thesis at UW)
It is part of a broader area on machine learning “interpretability”. For a very good exposition of ML explainability, see the wonderful little online book by Christoph Molnar: https://christophm.github.io/interpretable-ml-book/
%%time
# %%capture
!pip install --upgrade pip --quiet
!pip install --upgrade setuptools --quiet
# MXNet version of AutoGluon (deprecated)
# !pip install --upgrade "mxnet_cu110<2.0.0"
# !pip install autogluon==0.1.0
# CPU version of pytorch has smaller footprint - see installation instructions in
# pytorch documentation - https://pytorch.org/get-started/locally/
# !pip3 install torch==1.12.0+cu113 torchvision==0.13.0+cu113 torchtext==0.13.0 --extra-index-url https://download.pytorch.org/whl/cu113
# !pip3 install torch==1.12+cpu torchvision==0.13.0+cpu torchtext==0.13.0 -f https://download.pytorch.org/whl/cpu/torch_stable.html --quiet
!pip3 install autogluon --quiet
!pip install --upgrade shap --quiet
?25l ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/1.8 MB ? eta -:--:--
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸ 1.8/1.8 MB 102.3 MB/s eta 0:00:01
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.8/1.8 MB 30.8 MB/s eta 0:00:00
?25hERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
ipython 7.34.0 requires jedi>=0.16, which is not installed.
Installing build dependencies ... ?25l?25hdone
Getting requirements to build wheel ... ?25l?25hdone
Installing backend dependencies ... ?25l?25hdone
Preparing metadata (pyproject.toml) ... ?25l?25hdone
Installing build dependencies ... ?25l?25hdone
Getting requirements to build wheel ... ?25l?25hdone
Preparing metadata (pyproject.toml) ... ?25l?25hdone
Installing build dependencies ... ?25l?25hdone
Getting requirements to build wheel ... ?25l?25hdone
Preparing metadata (pyproject.toml) ... ?25l?25hdone
Building wheel for nvidia-ml-py3 (pyproject.toml) ... ?25l?25hdone
Building wheel for seqeval (pyproject.toml) ... ?25l?25hdone
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
torchaudio 2.9.0+cu126 requires torch==2.9.0, but you have torch 2.7.1 which is incompatible.
CPU times: user 9.47 s, sys: 1.29 s, total: 10.8 s
Wall time: 4min 58s
%pylab inline
import pandas as pd
from typing import Callable, Iterable
import numpy as np
import scipy.special
import itertools
from IPython.display import Image
Populating the interactive namespace from numpy and matplotlib
from google.colab import drive
drive.mount('/content/drive') # Add My Drive/<>
import os
os.chdir('drive/My Drive')
os.chdir('Books_Writings/NLPBook/')
Mounted at /content/drive
Image("NLP_images/xai.png", width=700)

48.1. Origins of Shapley value#
Shapley values quantify the contribution of each player to a game, and hence provide the means to distribute the total payoff generated by a game to its players based on their contributions.
Let’s take an example of \(M=3\) (players \(P_1, P_2, P_3\)) or students in a group project for which the total score achieved was 100. How do we allocate credit to each student?
We examine all possible groupings of the players, and in this case there are 8 such groupings: \(\emptyset\), \(\{P_1\}\), \(\{P_2\}\), \(\{P_3\}\), \(\{P_1, P_2\}\), \(\{P_1, P_3\}\), \(\{P_2, P_3\}\), \(\{P_1, P_2, P_3\}\).
We assume the outcomes are: \(5,10,15,12,45,55,65,100\).
Now we can compute the probability of a subset \(S\) that does not contain one of the players. The notation \(|S|\) stands for the size of the set \(S\).
This is also known as the kernel of the Shapley values.
from math import factorial
M = 3
# For P1, subsets are [null, P2, P3, {P2,P3}]
# Size |S| = 0,1,1,2
size_S = [0,1,1,2]
pr_S = [factorial(j)*factorial(M-j-1)/factorial(M) for j in size_S]
payoff = [5,30,43,35]
P1_payoff = sum([x*y for x,y in zip(pr_S,payoff)])
print(pr_S, payoff, P1_payoff)
[0.3333333333333333, 0.16666666666666666, 0.16666666666666666, 0.3333333333333333] [5, 30, 43, 35] 25.5
# For P2, subsets are null, P1, P3, {P1,P3}
# Size |S| = 1,1,1,2
size_S = [0,1,1,2]
pr_S = [factorial(j)*factorial(M-j-1)/factorial(M) for j in size_S]
payoff = [10,35,53,45]
P2_payoff = sum([x*y for x,y in zip(pr_S,payoff)])
print(pr_S, payoff, P2_payoff)
[0.3333333333333333, 0.16666666666666666, 0.16666666666666666, 0.3333333333333333] [10, 35, 53, 45] 33.0
# For P3, subsets are null, P1, P2, {P1,P2}
# Size |S| = 1,1,1,2
size_S = [0,1,1,2]
pr_S = [factorial(j)*factorial(M-j-1)/factorial(M) for j in size_S]
payoff = [7,45,50,55]
P3_payoff = sum([x*y for x,y in zip(pr_S,payoff)])
print(pr_S, payoff, P3_payoff)
print("Check additivity =",P1_payoff + P2_payoff + P3_payoff)
[0.3333333333333333, 0.16666666666666666, 0.16666666666666666, 0.3333333333333333] [7, 45, 50, 55] 36.5
Check additivity = 95.0
This shows the required number, i.e., productivity of all 3 players versus no players, 100-5 = 95.
48.2. Shapley value math (from the SHAP paper)#
Here we note some differences between the original paper by Shapley and the implementation in the recent SHAP paper.
Some notation:
Feature set: \(x = \{x_1,x_2,...,x_M\}\)
\(S\): subset of \(x\)
Power set of all feature subsets: \(P = \{\emptyset,\{x_1\},\{x_2\},...,x\}\)
\(|P| = 2^M\), so if \(M=4\), then \(|P|=16\).
\(f(S)\): predicted value from the fitted model function \(f\), using a subset \(S\) of the features
The Lunderberg and Lee (2017) paper (https://arxiv.org/pdf/1705.07874) adjusts the Shapley value for feature \(i\) (see Theorem 2 in the paper):
So, the SHAP kernel is the weighting function:
The original “classic” Shapley kernel we saw above is
Therefore,
Next see some code that implements these kernels as functions.
48.3. Transfer these ideas to ML models#
Let the features be players in the game and see how the various combinations of features change the predicted value from the model. If leaving out a feature does not change the prediction a lot, the Shapley value will be small and it is clear that the feature is not important.
Because the size of the powerset grows very fast, we can take samples of coalitions and work out the marginal contributions from the samples. To do this we need to specify the baseline and the number of samples.
# Helper functions
# See Theorem 2 in the original Shapley explanations paper: https://arxiv.org/pdf/1705.07874.pdf
def shapley_kernel(M: int, s: int) -> float:
if s == 0 or s == M:
return 10000 # Because the Shapley kernel is infinity for the null set or full set
return (M - 1) / (scipy.special.binom(M, s) * s * (M - s))
# Classic Shapley kernel, not the same as Lundberg's kernel above by a factor of (M-1)/s
def classic_kernel(M: int, s: int) -> float:
if s == 0 or s == M:
return 10000
return factorial(s)*factorial(M-s-1)/factorial(M)
def powerset(xs: Iterable) -> Iterable:
"""
:returns: iterable of subsets of xs
"""
s = list(xs)
return itertools.chain.from_iterable(itertools.combinations(s, r) for r in range(len(s) + 1))
48.4. Compare the weights between the Shapley and Classic kernels#
from math import factorial
xs = array([1,2,3,4])
P = enumerate(powerset(xs))
wts1 = []
wts2 = []
for i, s in P:
w1 = shapley_kernel(len(xs), len(s))
w2 = classic_kernel(len(xs), len(s))
wts1 = append(wts1, w1)
wts2 = append(wts2, w2)
print(i, s, round(w1,4), round(w2,4))
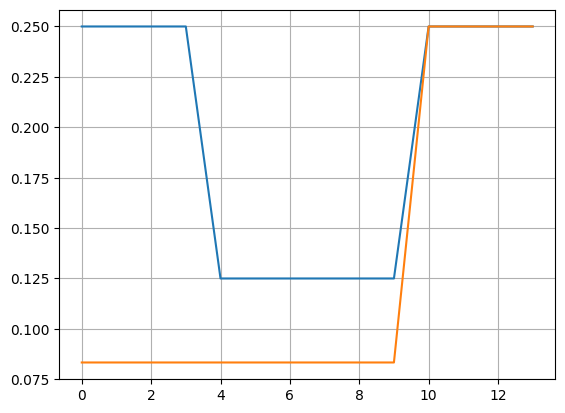
plot(wts1[1:-1], label="SHAP"); grid()
plot(wts2[1:-1], label="Classic")
0 () 10000 10000
1 (np.int64(1),) 0.25 0.0833
2 (np.int64(2),) 0.25 0.0833
3 (np.int64(3),) 0.25 0.0833
4 (np.int64(4),) 0.25 0.0833
5 (np.int64(1), np.int64(2)) 0.125 0.0833
6 (np.int64(1), np.int64(3)) 0.125 0.0833
7 (np.int64(1), np.int64(4)) 0.125 0.0833
8 (np.int64(2), np.int64(3)) 0.125 0.0833
9 (np.int64(2), np.int64(4)) 0.125 0.0833
10 (np.int64(3), np.int64(4)) 0.125 0.0833
11 (np.int64(1), np.int64(2), np.int64(3)) 0.25 0.25
12 (np.int64(1), np.int64(2), np.int64(4)) 0.25 0.25
13 (np.int64(1), np.int64(3), np.int64(4)) 0.25 0.25
14 (np.int64(2), np.int64(3), np.int64(4)) 0.25 0.25
15 (np.int64(1), np.int64(2), np.int64(3), np.int64(4)) 10000 10000
[<matplotlib.lines.Line2D at 0x7909f2cc80e0>]
48.5. Three Axioms#
Dummy feature: If a feature never adds any marginal explanation, its payoff is zero.
Substitutability: If two features always add the same marginal value to any subset to which they are added, their payoff should be the same
Additivity: The payoff of a feature in two subsets of features should be additive to the sum of the payoffs in the combined set.
Shapley value is the only attribution method that satisfies these axioms.
48.6. Surrogate and Locally Interpretable Models#
In the literature, beginning with the LIME model, see https://homes.cs.washington.edu/~marcotcr/blog/lime/, the concept of locally interpretable models was floated. The idea being that feature importance can be different in various neighborhoods of the feature space.
The model may be trustworthy locally even if not globally.
We want the explanations to be model agnostic. Therefore, we fit linear surrogates.
48.7. The Main SHAP function#
In which we implement the entire SHAP in just 20 lines.
We will return to this after we break down the algorithm into its components and understand each part of it.
# One function to rule it all
def model(x):
return np.dot(x, model_params) + bias
def kernel_shap(model: Callable[[np.ndarray], np.ndarray], instance: np.array, reference: np.array, M: int) -> np.array:
n_samples = 2 ** M
simplified_features = np.zeros((n_samples, M + 1))
simplified_features[:, -1] = 1 # last is all features set
kernel_weights = np.zeros(n_samples)
synthetic_dataset = np.zeros((n_samples, M))
for i in range(n_samples):
synthetic_dataset[i, :] = reference
for i, subset in enumerate(powerset(range(M))):
subset = list(subset)
simplified_features[i, subset] = 1
synthetic_dataset[i, subset] = instance[subset]
kernel_weights[i] = shapley_kernel(M, len(subset)) # you can also use the classic_kernel
# Solve:
y = model(synthetic_dataset)
W = np.diag(kernel_weights)
xtwxm1 = np.linalg.inv(np.dot(np.dot(simplified_features.T, W), simplified_features))
# tmp = np.dot(simplified_features.T, W) # This line is not needed
res = np.dot(xtwxm1, np.dot(np.dot(simplified_features.T, W), y))
return res
48.8. Read in the iris data set#
Let’s do the above in small pieces using the iris data set.
iris = pd.read_csv('NLP_data/iris_data.csv')
print(iris.shape)
M = iris.shape[1] - 1
iris.head()
(150, 5)
| sepal.length | sepal.width | petal.length | petal.width | variety | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Setosa |
iris.describe()
| sepal.length | sepal.width | petal.length | petal.width | |
|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 5.843333 | 3.057333 | 3.758000 | 1.199333 |
| std | 0.828066 | 0.435866 | 1.765298 | 0.762238 |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
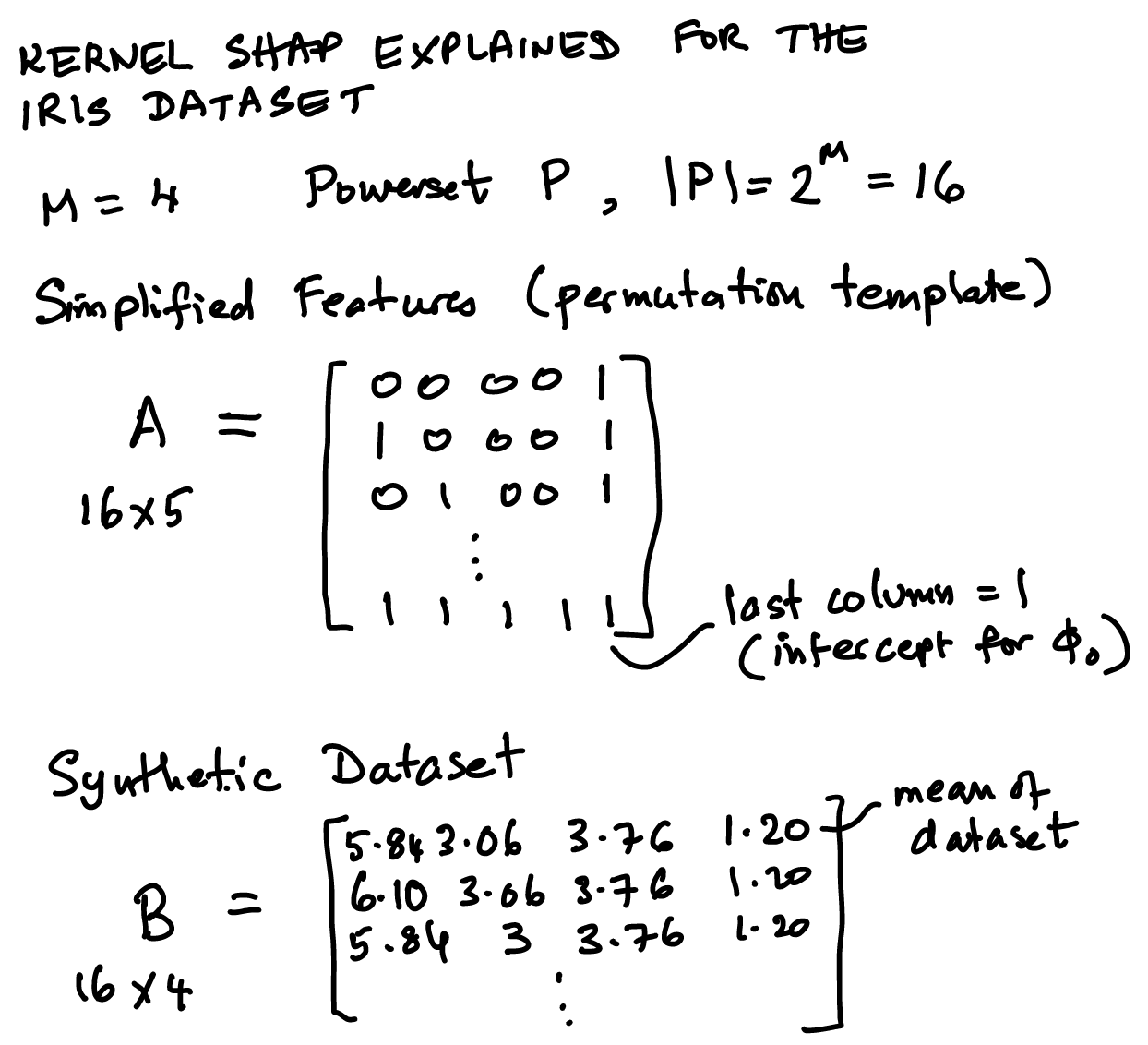
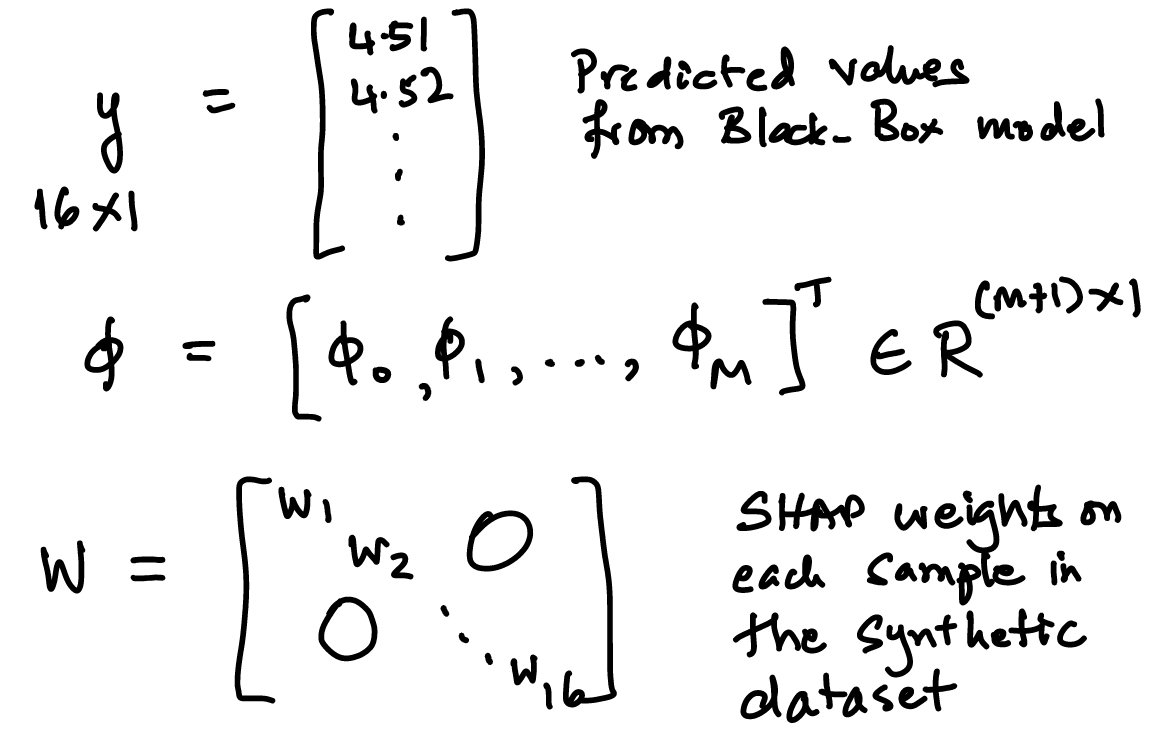
48.9. Diagrammatic Exposition of the Matrices and Vectors in SHAP#
Steps to understand the SHAP algorithm:
Assume we have a complex black-box model for which we want feature importances.
The idea is to find a linear model to approximate the black-box model.
First, fit the linear model to generated values from the black-box model for all permutations of the feature set (which we call the synthetic dataset).
We call the black-box model \(2^{|M|}\) times – this can be onerous because the number of permutations can grow as \(M\) gets large so a sampling approach is applied.
The weighted regression is fitted to get the Shapley values. Weights are the kernel weights.
We see the sketch first below and then the code to fit it.
Image("NLP_images/pshap1.png",width=500)
Image("NLP_images/pshap2.png",width=500)
Image("NLP_images/pshap3.png",width=500)
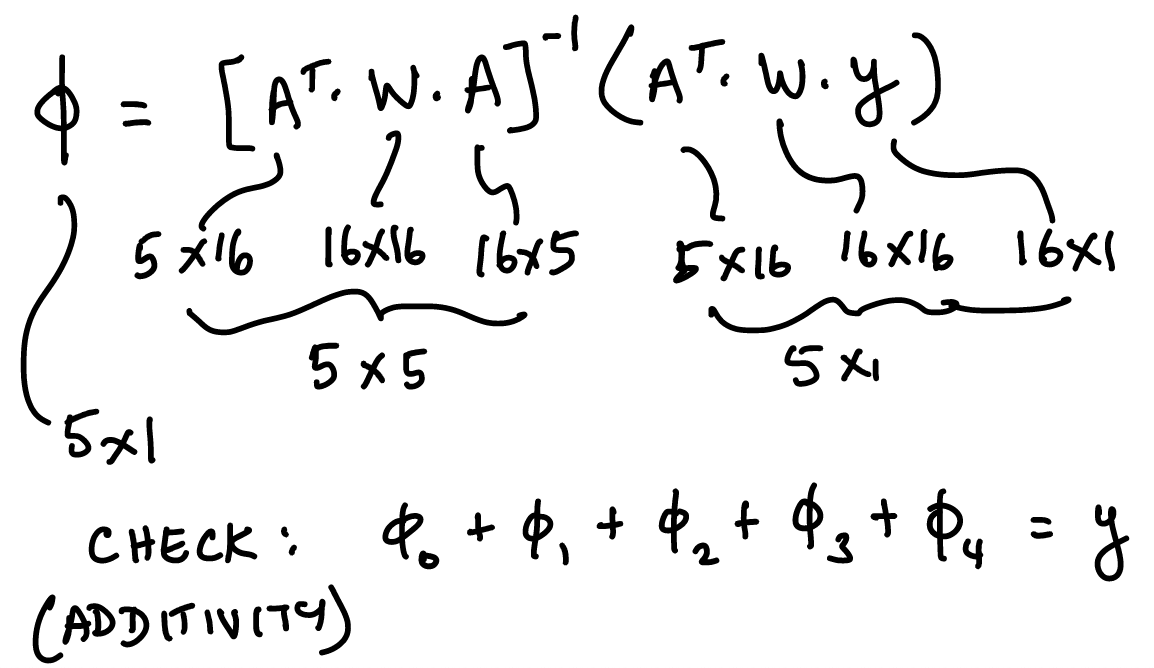
48.10. Powerset and samples#
Number of sample is \(n\), and the size of the powerset is also \(n\) if we enumerate all subsets. However, in practice we may choose a smaller sample size than \(n\).
# Get the size of the powerset
n_samples = 2**M
print(n_samples)
16
48.11. Simplified features#
We call this matrix \(A\) and each column is for the different SHAP values \(\phi_i, i=1..M\) and also one for the constant, \(\phi_0\).
# Simplified features
simplified_features = np.zeros((n_samples, M + 1))
simplified_features[:, -1] = 1 # intercept
print(simplified_features.shape)
simplified_features
(16, 5)
array([[0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1.]])
48.12. Kernel weights and Synthetic dataset#
The SHAP kernel was shown above and is of dimension \(n\) also, but later we will store the values of the kernel weights in a \(n \times n\) matrix, denoted \(W\).
The synthetic dataset is denoted \(B\), for “background” dataset.
# Set up kernel weights and the synthetic dataset
kernel_weights = np.zeros(n_samples)
synthetic_dataset = np.zeros((n_samples, M))
print(synthetic_dataset.shape)
synthetic_dataset
(16, 4)
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
48.13. Reference observation or baseline instance#
This is the benchmark from which we want to explain the deviation of the instance we are trying to explain. Here we set the reference to the mean of the dataset.
iris.head()
| sepal.length | sepal.width | petal.length | petal.width | variety | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Setosa |
reference = iris.iloc[:,:4].mean()
for i in range(n_samples):
synthetic_dataset[i, :] = reference
print(reference)
sepal.length 5.843333
sepal.width 3.057333
petal.length 3.758000
petal.width 1.199333
dtype: float64
48.14. Instance#
The observation in the data that we are trying to explain. We pick this randomly here.
The instance is \(x\) of dimension \(4 \times 1\).
instance = iris.loc[randint(iris.shape[0])][:4]
print(instance)
for i, subset in enumerate(powerset(range(M))):
subset = list(subset)
simplified_features[i, subset] = 1
synthetic_dataset[i, subset] = instance[subset]
kernel_weights[i] = shapley_kernel(M, len(subset))
sepal.length 4.6
sepal.width 3.1
petal.length 1.5
petal.width 0.2
Name: 3, dtype: object
/tmp/ipython-input-1658017414.py:6: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
synthetic_dataset[i, subset] = instance[subset]
48.15. Simplified features or the permutated dataset#
Here we create a template for inclusion/exclusion of features that contain some of the original values of the instance and some from the reference. These are combined into the synthetic dataset. The simplified feature set is \(A\).
simplified_features
array([[0., 0., 0., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 0., 1., 1.],
[1., 1., 0., 0., 1.],
[1., 0., 1., 0., 1.],
[1., 0., 0., 1., 1.],
[0., 1., 1., 0., 1.],
[0., 1., 0., 1., 1.],
[0., 0., 1., 1., 1.],
[1., 1., 1., 0., 1.],
[1., 1., 0., 1., 1.],
[1., 0., 1., 1., 1.],
[0., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
48.16. Synthetic Dataset#
The way this is created (see the code way above) is to make every observation the same as the reference instance and then overwrite it using the template of simplified features. The synthetic dataset = \(B\).
synthetic_dataset
array([[5.84333333, 3.05733333, 3.758 , 1.19933333],
[4.6 , 3.05733333, 3.758 , 1.19933333],
[5.84333333, 3.1 , 3.758 , 1.19933333],
[5.84333333, 3.05733333, 1.5 , 1.19933333],
[5.84333333, 3.05733333, 3.758 , 0.2 ],
[4.6 , 3.1 , 3.758 , 1.19933333],
[4.6 , 3.05733333, 1.5 , 1.19933333],
[4.6 , 3.05733333, 3.758 , 0.2 ],
[5.84333333, 3.1 , 1.5 , 1.19933333],
[5.84333333, 3.1 , 3.758 , 0.2 ],
[5.84333333, 3.05733333, 1.5 , 0.2 ],
[4.6 , 3.1 , 1.5 , 1.19933333],
[4.6 , 3.1 , 3.758 , 0.2 ],
[4.6 , 3.05733333, 1.5 , 0.2 ],
[5.84333333, 3.1 , 1.5 , 0.2 ],
[4.6 , 3.1 , 1.5 , 0.2 ]])
48.17. Kernel weights#
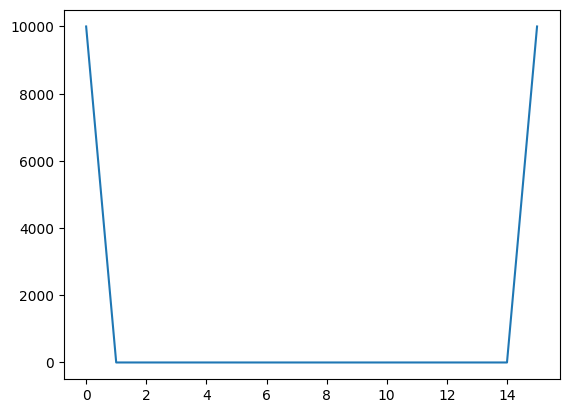
We see that the subsets at the edge carry more weight. The matrix \(W\) used later will be a diagonal matrix with kernel weights.
print(len(kernel_weights))
print(kernel_weights)
plot(kernel_weights)
16
[1.00e+04 2.50e-01 2.50e-01 2.50e-01 2.50e-01 1.25e-01 1.25e-01 1.25e-01
1.25e-01 1.25e-01 1.25e-01 2.50e-01 2.50e-01 2.50e-01 2.50e-01 1.00e+04]
[<matplotlib.lines.Line2D at 0x790b4077bbc0>]
48.18. The black-box model#
In this case it is a simple linear model and the model parameters are just randomly generated as an example. We take the synthetic dataset and use the model to get the predicted \(y\) values. \(y\) is of dimension \(16 \times 1\). The model parameters are \(\beta = \{\beta_1, \beta_2, \beta_3, \beta_4, \beta_0\}\).
model_params = np.random.rand(M) # random here, but should be the actual parameters of the bb model
bias = np.random.rand(1).item()
y = model(synthetic_dataset) # Calling the black-box model
y
array([6.81048725, 6.44113597, 6.82007612, 4.79566201, 6.23653829,
6.45072484, 4.42631073, 5.867187 , 4.80525089, 6.24612716,
4.22171305, 4.4358996 , 5.87677587, 3.85236177, 4.23130192,
3.86195064])
48.19. Solve for the coefficients of the minimized kernel-weighted loss function, using weighted least squares regression#
https://en.wikipedia.org/wiki/Weighted_least_squares
\(A\) is of dimension \(16 \times 5\)
\(B\) is of dimension \(16 \times 4\)
\(W\) is of dimension \(16 \times 16\)
\(x\) is of dimension \(4 \times 1\)
\(y\) is of dimension \(16 \times 1\)
So, \(\phi\) in this case will be of dimension \(5 \times 1\).
W = np.diag(kernel_weights) # create a diagonal matrix W of the shapley_kernel weights
print(W.shape) # This is a square matrix
(16, 16)
xtwxm1 = np.linalg.inv(np.dot(np.dot(simplified_features.T, W), simplified_features))
print(xtwxm1.shape)
xtwxm1
(5, 5)
array([[ 1.00001250e+00, -3.33320834e-01, -3.33320834e-01,
-3.33320834e-01, -2.49993750e-05],
[-3.33320834e-01, 1.00001250e+00, -3.33320834e-01,
-3.33320834e-01, -2.49993750e-05],
[-3.33320834e-01, -3.33320834e-01, 1.00001250e+00,
-3.33320834e-01, -2.49993750e-05],
[-3.33320834e-01, -3.33320834e-01, -3.33320834e-01,
1.00001250e+00, -2.49993750e-05],
[-2.49993750e-05, -2.49993750e-05, -2.49993750e-05,
-2.49993750e-05, 9.99918760e-05]])
res = np.dot(xtwxm1, np.dot(np.dot(simplified_features.T, W), y))
print(res.shape)
res
(5,)
array([-0.36935128, 0.00958887, -2.01482524, -0.57394896, 6.81048725])
48.20. Test full function for SHAP values#
Here we check that the original model we coded at the top of the notebook is indeed giving the same results as the separate pieces we looked at step by step.
sol = kernel_shap(model, instance, reference, M)
sol
/tmp/ipython-input-2102829098.py:17: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
synthetic_dataset[i, subset] = instance[subset]
array([-0.36935128, 0.00958887, -2.01482524, -0.57394896, 6.81048725])
48.21. Additivity of SHAP values#
where \(x\) is the row of synthetic dataset \(B\) with a 1 appended to it. And recall that \(\beta\) is the black-box model parameter vector.
# Compute the model value (y) of the instance
print('Instance')
x = append(list(instance),1.0)
print(instance)
print(model(instance))
Instance
sepal.length 4.6
sepal.width 3.1
petal.length 1.5
petal.width 0.2
Name: 3, dtype: object
3.8619506364657146
#Cross check that this equals the sum of the SHAP values
sum(sol)
np.float64(3.8619506364651484)
The absolute sign of the \(\phi\) values tells us which feature is the most relevant in determining the model’s predicted value.
# Most important feature (ignore the intercept of course)
print("Most important feature (starting index 0): ", argmax(abs(sol[:M])))
Most important feature (starting index 0): 2
48.22. Using AutoGluon with the SHAP package#
Now we will use the iris dataset for ML with AutoGluon and see how to pass the results to SHAP.
from autogluon.tabular import TabularPredictor
from sklearn.model_selection import train_test_split
iris.head()
| sepal.length | sepal.width | petal.length | petal.width | variety | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Setosa |
#TRAIN THE MODEL (DATA)
print(iris.columns)
train_data, test_data = train_test_split(iris, test_size=0.3, random_state=42)
print("Train size =",train_data.shape," | Test size =",test_data.shape)
Index(['sepal.length', 'sepal.width', 'petal.length', 'petal.width',
'variety'],
dtype='object')
Train size = (105, 5) | Test size = (45, 5)
#TRAIN THE MODEL (FIT)
predictor = TabularPredictor(label='variety').fit(train_data=train_data)#, hyperparameters='multimodal')
performance = predictor.evaluate(test_data)
No path specified. Models will be saved in: "AutogluonModels/ag-20251129_203535"
Verbosity: 2 (Standard Logging)
=================== System Info ===================
AutoGluon Version: 1.4.0
Python Version: 3.12.12
Operating System: Linux
Platform Machine: x86_64
Platform Version: #1 SMP Thu Oct 2 10:42:05 UTC 2025
CPU Count: 2
Memory Avail: 11.16 GB / 12.67 GB (88.1%)
Disk Space Avail: 172.18 GB / 225.83 GB (76.2%)
===================================================
No presets specified! To achieve strong results with AutoGluon, it is recommended to use the available presets. Defaulting to `'medium'`...
Recommended Presets (For more details refer to https://auto.gluon.ai/stable/tutorials/tabular/tabular-essentials.html#presets):
presets='extreme' : New in v1.4: Massively better than 'best' on datasets <30000 samples by using new models meta-learned on https://tabarena.ai: TabPFNv2, TabICL, Mitra, and TabM. Absolute best accuracy. Requires a GPU. Recommended 64 GB CPU memory and 32+ GB GPU memory.
presets='best' : Maximize accuracy. Recommended for most users. Use in competitions and benchmarks.
presets='high' : Strong accuracy with fast inference speed.
presets='good' : Good accuracy with very fast inference speed.
presets='medium' : Fast training time, ideal for initial prototyping.
Using hyperparameters preset: hyperparameters='default'
Beginning AutoGluon training ...
AutoGluon will save models to "/content/drive/My Drive/Books_Writings/NLPBook/AutogluonModels/ag-20251129_203535"
Train Data Rows: 105
Train Data Columns: 4
Label Column: variety
AutoGluon infers your prediction problem is: 'multiclass' (because dtype of label-column == object).
3 unique label values: ['Versicolor', 'Virginica', 'Setosa']
If 'multiclass' is not the correct problem_type, please manually specify the problem_type parameter during Predictor init (You may specify problem_type as one of: ['binary', 'multiclass', 'regression', 'quantile'])
Problem Type: multiclass
Preprocessing data ...
Train Data Class Count: 3
Using Feature Generators to preprocess the data ...
Fitting AutoMLPipelineFeatureGenerator...
Available Memory: 11425.54 MB
Train Data (Original) Memory Usage: 0.00 MB (0.0% of available memory)
Inferring data type of each feature based on column values. Set feature_metadata_in to manually specify special dtypes of the features.
Stage 1 Generators:
Fitting AsTypeFeatureGenerator...
Stage 2 Generators:
Fitting FillNaFeatureGenerator...
Stage 3 Generators:
Fitting IdentityFeatureGenerator...
Stage 4 Generators:
Fitting DropUniqueFeatureGenerator...
Stage 5 Generators:
Fitting DropDuplicatesFeatureGenerator...
Types of features in original data (raw dtype, special dtypes):
('float', []) : 4 | ['sepal.length', 'sepal.width', 'petal.length', 'petal.width']
Types of features in processed data (raw dtype, special dtypes):
('float', []) : 4 | ['sepal.length', 'sepal.width', 'petal.length', 'petal.width']
0.0s = Fit runtime
4 features in original data used to generate 4 features in processed data.
Train Data (Processed) Memory Usage: 0.00 MB (0.0% of available memory)
Data preprocessing and feature engineering runtime = 0.09s ...
AutoGluon will gauge predictive performance using evaluation metric: 'accuracy'
To change this, specify the eval_metric parameter of Predictor()
Automatically generating train/validation split with holdout_frac=0.2, Train Rows: 84, Val Rows: 21
User-specified model hyperparameters to be fit:
{
'NN_TORCH': [{}],
'GBM': [{'extra_trees': True, 'ag_args': {'name_suffix': 'XT'}}, {}, {'learning_rate': 0.03, 'num_leaves': 128, 'feature_fraction': 0.9, 'min_data_in_leaf': 3, 'ag_args': {'name_suffix': 'Large', 'priority': 0, 'hyperparameter_tune_kwargs': None}}],
'CAT': [{}],
'XGB': [{}],
'FASTAI': [{}],
'RF': [{'criterion': 'gini', 'ag_args': {'name_suffix': 'Gini', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'entropy', 'ag_args': {'name_suffix': 'Entr', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'squared_error', 'ag_args': {'name_suffix': 'MSE', 'problem_types': ['regression', 'quantile']}}],
'XT': [{'criterion': 'gini', 'ag_args': {'name_suffix': 'Gini', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'entropy', 'ag_args': {'name_suffix': 'Entr', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'squared_error', 'ag_args': {'name_suffix': 'MSE', 'problem_types': ['regression', 'quantile']}}],
}
Fitting 11 L1 models, fit_strategy="sequential" ...
Fitting model: NeuralNetFastAI ...
Fitting with cpus=1, gpus=0, mem=0.0/11.0 GB
No improvement since epoch 4: early stopping
0.9048 = Validation score (accuracy)
5.87s = Training runtime
0.01s = Validation runtime
Fitting model: LightGBMXT ...
Fitting with cpus=1, gpus=0, mem=0.0/10.9 GB
0.9524 = Validation score (accuracy)
6.69s = Training runtime
0.0s = Validation runtime
Fitting model: LightGBM ...
Fitting with cpus=1, gpus=0, mem=0.0/10.9 GB
0.8571 = Validation score (accuracy)
0.3s = Training runtime
0.0s = Validation runtime
Fitting model: RandomForestGini ...
Fitting with cpus=2, gpus=0
0.8571 = Validation score (accuracy)
0.98s = Training runtime
0.09s = Validation runtime
Fitting model: RandomForestEntr ...
Fitting with cpus=2, gpus=0
0.8571 = Validation score (accuracy)
0.81s = Training runtime
0.08s = Validation runtime
Fitting model: CatBoost ...
Fitting with cpus=1, gpus=0
0.9524 = Validation score (accuracy)
0.66s = Training runtime
0.0s = Validation runtime
Fitting model: ExtraTreesGini ...
Fitting with cpus=2, gpus=0
0.9048 = Validation score (accuracy)
0.86s = Training runtime
0.09s = Validation runtime
Fitting model: ExtraTreesEntr ...
Fitting with cpus=2, gpus=0
0.9048 = Validation score (accuracy)
0.84s = Training runtime
0.09s = Validation runtime
Fitting model: XGBoost ...
Fitting with cpus=1, gpus=0
0.9524 = Validation score (accuracy)
0.18s = Training runtime
0.0s = Validation runtime
Fitting model: NeuralNetTorch ...
Fitting with cpus=1, gpus=0, mem=0.0/10.8 GB
0.9524 = Validation score (accuracy)
6.23s = Training runtime
0.01s = Validation runtime
Fitting model: LightGBMLarge ...
Fitting with cpus=1, gpus=0, mem=0.0/10.8 GB
0.8571 = Validation score (accuracy)
0.64s = Training runtime
0.0s = Validation runtime
Fitting model: WeightedEnsemble_L2 ...
Ensemble Weights: {'LightGBMXT': 1.0}
0.9524 = Validation score (accuracy)
0.17s = Training runtime
0.0s = Validation runtime
AutoGluon training complete, total runtime = 25.72s ... Best model: WeightedEnsemble_L2 | Estimated inference throughput: 8976.8 rows/s (21 batch size)
TabularPredictor saved. To load, use: predictor = TabularPredictor.load("/content/drive/My Drive/Books_Writings/NLPBook/AutogluonModels/ag-20251129_203535")
import shap
train_data_wo_label = train_data.drop(['variety'], axis=1)
test_data_wo_label = test_data.drop(['variety'], axis=1)
labels = [name for name in test_data_wo_label]
# We have to create a data frame everytime we want the data
predict_proba = lambda data : predictor.predict_proba(pd.DataFrame(data, columns=labels)) # a lambda function
explainer = shap.KernelExplainer(model=predict_proba, data=train_data_wo_label, link='logit') # kernel shap function
shap_values = explainer.shap_values(test_data_wo_label, nsamples=50, l1_reg='num_features(10)')
WARNING:shap:Using 105 background data samples could cause slower run times. Consider using shap.sample(data, K) or shap.kmeans(data, K) to summarize the background as K samples.
print(predict_proba)
print(explainer)
print(array(shap_values).shape) # test rows x features x classes
<function <lambda> at 0x7909fc4fea20>
<shap.explainers._kernel.KernelExplainer object at 0x790a487a38c0>
(45, 4, 3)
import shap
from numpy import array
from random import randint
# Assuming 'iris', 'explainer', 'shap_values', and 'test_data_wo_label' are already defined
shap.initjs()
j = randint(0, len(test_data_wo_label))
print("Instance# :", j, " | Type =", iris.variety[j])
# Select SHAP values for the first class (class_index = 0)
# You can change this to the desired class index if needed
class_index = 0
shap.force_plot(explainer.expected_value[class_index], shap_values[j, :, class_index], test_data_wo_label.iloc[j,:])

Instance# : 24 | Type = Setosa
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
# plot the SHAP values for the Setosa output of all instances
shap.initjs()
shap.force_plot(explainer.expected_value[0], shap_values[:,:,0], test_data_wo_label, link="logit")
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
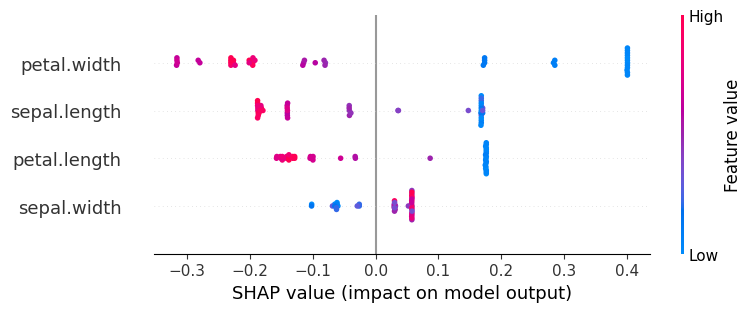
48.23. Global Explanation#
# Classes: ['Versicolor', 'Virginica', 'Setosa']
explanation = shap.Explanation(values=shap_values[:,:,class_index],
data=test_data_wo_label.values,
feature_names=test_data_wo_label.columns,
base_values=explainer.expected_value)
shap.initjs()
# Now use the explanation object for the beeswarm plot
shap.plots.beeswarm(explanation)
48.24. Handling NLP Explainability#
We use the Disaster Tweets Dataset (2020): https://www.kaggle.com/vstepanenko/disaster-tweets (open source dataset)
# Read data
df_orig = pd.read_csv('NLP_data/disaster_tweets.csv')
df_orig = df_orig[['target','text']]
df_orig.columns = ["Label","Text"]
print(df_orig.shape)
df_orig.head()
(11370, 2)
| Label | Text | |
|---|---|---|
| 0 | 1 | Communal violence in Bhainsa, Telangana. "Stones were pelted on Muslims' houses and some houses and vehicles were set ablaze… |
| 1 | 1 | Telangana: Section 144 has been imposed in Bhainsa from January 13 to 15, after clash erupted between two groups on January 12. Po… |
| 2 | 1 | Arsonist sets cars ablaze at dealership https://t.co/gOQvyJbpVI |
| 3 | 1 | Arsonist sets cars ablaze at dealership https://t.co/0gL7NUCPlb https://t.co/u1CcBhOWh9 |
| 4 | 0 | "Lord Jesus, your love brings freedom and pardon. Fill me with your Holy Spirit and set my heart ablaze with your l… https://t.co/VlTznnPNi8 |
import seaborn as sns
df = df_orig.copy()
sns.countplot(x='Label', data=df)
show()
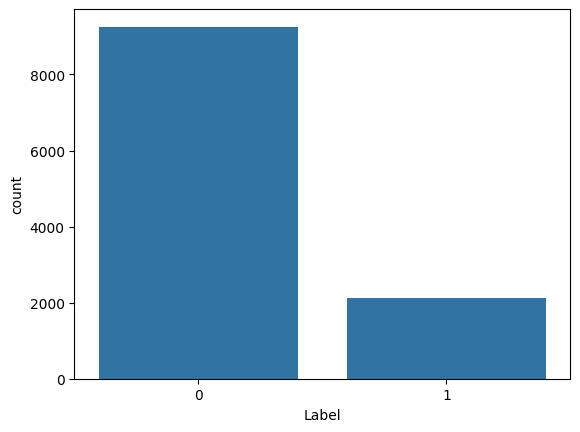
res = df.groupby('Label').count()
print(res)
print(res/sum(res))
Text
Label
0 9256
1 2114
Text
Label
0 0.814072
1 0.185928
/usr/local/lib/python3.12/dist-packages/numpy/_core/fromnumeric.py:84: FutureWarning: The behavior of DataFrame.sum with axis=None is deprecated, in a future version this will reduce over both axes and return a scalar. To retain the old behavior, pass axis=0 (or do not pass axis)
return reduction(axis=axis, out=out, **passkwargs)
# !pip install unidecode --quiet
# !pip install gensim==3.6.0 --quiet
# !pip install texthero --no-dependencies
# !pip install --upgrade spacy --quiet
# Use texthero as an alternative text cleaner, instead of the code below
import nltk
nltk.download("stopwords")
nltk.download("wordnet")
nltk.download('omw-1.4')
stopwords = nltk.corpus.stopwords.words("english")
def removeNumbersStr(s):
for c in range(10):
n = str(c)
s = s.replace(n," ")
return s
def cleanText(text, stem=False, lemm=True, stop=True):
text = re.sub(r'[^\w\s]', '', str(text).lower().strip()) # remove stuff
text = removeNumbersStr(text)
text = text.split() # tokenize
if stop is not None: # remove stopwords
text = [word for word in text if word not in stopwords]
if stem == True: # stemming
ps = nltk.stem.porter.PorterStemmer()
text = [ps.stem(word) for word in text]
if lemm == True:
lem = nltk.stem.wordnet.WordNetLemmatizer()
text = [lem.lemmatize(word) for word in text]
text = " ".join(text)
return text
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
[nltk_data] Downloading package wordnet to /root/nltk_data...
[nltk_data] Downloading package omw-1.4 to /root/nltk_data...
# import texthero as hero
# df['cleanText'] = hero.clean(df['Text'])
import re
df["cleanText"] = [cleanText(df.Text[j]) for j in range(len(df.Text))]
print(df.shape)
df.head()
(11370, 3)
| Label | Text | cleanText | |
|---|---|---|---|
| 0 | 1 | Communal violence in Bhainsa, Telangana. "Stones were pelted on Muslims' houses and some houses and vehicles were set ablaze… | communal violence bhainsa telangana stone pelted muslim house house vehicle set ablaze |
| 1 | 1 | Telangana: Section 144 has been imposed in Bhainsa from January 13 to 15, after clash erupted between two groups on January 12. Po… | telangana section imposed bhainsa january clash erupted two group january po |
| 2 | 1 | Arsonist sets cars ablaze at dealership https://t.co/gOQvyJbpVI | arsonist set car ablaze dealership httpstcogoqvyjbpvi |
| 3 | 1 | Arsonist sets cars ablaze at dealership https://t.co/0gL7NUCPlb https://t.co/u1CcBhOWh9 | arsonist set car ablaze dealership httpstco gl nucplb httpstcou ccbhowh |
| 4 | 0 | "Lord Jesus, your love brings freedom and pardon. Fill me with your Holy Spirit and set my heart ablaze with your l… https://t.co/VlTznnPNi8 | lord jesus love brings freedom pardon fill holy spirit set heart ablaze l httpstcovltznnpni |
#TRAIN-TEST DATA
from sklearn.model_selection import train_test_split
df = df.drop(['Text'], axis=1)
train_data, test_data = train_test_split(df, test_size=0.2, random_state=123)
print("Train size =",train_data.shape," | Test size =",test_data.shape)
###
# Adding count vectorizer to make this process a bit easier
###
from sklearn.feature_extraction.text import CountVectorizer
# Set vocab size
vectorizer = CountVectorizer(max_features=500).fit(train_data['cleanText'])
vocab = vectorizer.get_feature_names_out()
train_countvec_text = pd.DataFrame(vectorizer.transform(train_data['cleanText']).toarray(), columns=vocab, index=train_data.index)
test_countvec_text = pd.DataFrame(vectorizer.transform(test_data['cleanText']).toarray(), columns=vocab, index=test_data.index)
train_data = pd.concat([train_data.drop(['cleanText'], axis=1), train_countvec_text], axis=1)
test_data = pd.concat([test_data.drop(['cleanText'], axis=1), test_countvec_text], axis=1)
Train size = (9096, 2) | Test size = (2274, 2)
%%time
# TRAIN THE MODEL
predictor = TabularPredictor(label='Label').fit(train_data=train_data)
performance = predictor.evaluate(test_data)
No path specified. Models will be saved in: "AutogluonModels/ag-20251129_203619"
Verbosity: 2 (Standard Logging)
=================== System Info ===================
AutoGluon Version: 1.4.0
Python Version: 3.12.12
Operating System: Linux
Platform Machine: x86_64
Platform Version: #1 SMP Thu Oct 2 10:42:05 UTC 2025
CPU Count: 2
Memory Avail: 10.53 GB / 12.67 GB (83.1%)
Disk Space Avail: 172.09 GB / 225.83 GB (76.2%)
===================================================
No presets specified! To achieve strong results with AutoGluon, it is recommended to use the available presets. Defaulting to `'medium'`...
Recommended Presets (For more details refer to https://auto.gluon.ai/stable/tutorials/tabular/tabular-essentials.html#presets):
presets='extreme' : New in v1.4: Massively better than 'best' on datasets <30000 samples by using new models meta-learned on https://tabarena.ai: TabPFNv2, TabICL, Mitra, and TabM. Absolute best accuracy. Requires a GPU. Recommended 64 GB CPU memory and 32+ GB GPU memory.
presets='best' : Maximize accuracy. Recommended for most users. Use in competitions and benchmarks.
presets='high' : Strong accuracy with fast inference speed.
presets='good' : Good accuracy with very fast inference speed.
presets='medium' : Fast training time, ideal for initial prototyping.
Using hyperparameters preset: hyperparameters='default'
Beginning AutoGluon training ...
AutoGluon will save models to "/content/drive/MyDrive/Books_Writings/NLPBook/AutogluonModels/ag-20251129_203619"
Train Data Rows: 9096
Train Data Columns: 500
Label Column: Label
AutoGluon infers your prediction problem is: 'binary' (because only two unique label-values observed).
2 unique label values: [np.int64(0), np.int64(1)]
If 'binary' is not the correct problem_type, please manually specify the problem_type parameter during Predictor init (You may specify problem_type as one of: ['binary', 'multiclass', 'regression', 'quantile'])
Problem Type: binary
Preprocessing data ...
Selected class <--> label mapping: class 1 = 1, class 0 = 0
Using Feature Generators to preprocess the data ...
Fitting AutoMLPipelineFeatureGenerator...
Available Memory: 10746.53 MB
Train Data (Original) Memory Usage: 34.70 MB (0.3% of available memory)
Inferring data type of each feature based on column values. Set feature_metadata_in to manually specify special dtypes of the features.
Stage 1 Generators:
Fitting AsTypeFeatureGenerator...
Note: Converting 158 features to boolean dtype as they only contain 2 unique values.
Stage 2 Generators:
Fitting FillNaFeatureGenerator...
Stage 3 Generators:
Fitting IdentityFeatureGenerator...
Stage 4 Generators:
Fitting DropUniqueFeatureGenerator...
Stage 5 Generators:
Fitting DropDuplicatesFeatureGenerator...
Types of features in original data (raw dtype, special dtypes):
('int', []) : 500 | ['absolutely', 'accident', 'account', 'across', 'actually', ...]
Types of features in processed data (raw dtype, special dtypes):
('int', []) : 342 | ['accident', 'air', 'almost', 'along', 'also', ...]
('int', ['bool']) : 158 | ['absolutely', 'account', 'across', 'actually', 'affected', ...]
5.0s = Fit runtime
500 features in original data used to generate 500 features in processed data.
Train Data (Processed) Memory Usage: 25.10 MB (0.2% of available memory)
Data preprocessing and feature engineering runtime = 5.22s ...
AutoGluon will gauge predictive performance using evaluation metric: 'accuracy'
To change this, specify the eval_metric parameter of Predictor()
Automatically generating train/validation split with holdout_frac=0.1, Train Rows: 8186, Val Rows: 910
User-specified model hyperparameters to be fit:
{
'NN_TORCH': [{}],
'GBM': [{'extra_trees': True, 'ag_args': {'name_suffix': 'XT'}}, {}, {'learning_rate': 0.03, 'num_leaves': 128, 'feature_fraction': 0.9, 'min_data_in_leaf': 3, 'ag_args': {'name_suffix': 'Large', 'priority': 0, 'hyperparameter_tune_kwargs': None}}],
'CAT': [{}],
'XGB': [{}],
'FASTAI': [{}],
'RF': [{'criterion': 'gini', 'ag_args': {'name_suffix': 'Gini', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'entropy', 'ag_args': {'name_suffix': 'Entr', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'squared_error', 'ag_args': {'name_suffix': 'MSE', 'problem_types': ['regression', 'quantile']}}],
'XT': [{'criterion': 'gini', 'ag_args': {'name_suffix': 'Gini', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'entropy', 'ag_args': {'name_suffix': 'Entr', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'squared_error', 'ag_args': {'name_suffix': 'MSE', 'problem_types': ['regression', 'quantile']}}],
}
Fitting 11 L1 models, fit_strategy="sequential" ...
Fitting model: LightGBMXT ...
Fitting with cpus=1, gpus=0, mem=0.2/10.4 GB
0.8923 = Validation score (accuracy)
4.66s = Training runtime
0.06s = Validation runtime
Fitting model: LightGBM ...
Fitting with cpus=1, gpus=0, mem=0.2/10.4 GB
0.8934 = Validation score (accuracy)
3.46s = Training runtime
0.07s = Validation runtime
Fitting model: RandomForestGini ...
Fitting with cpus=2, gpus=0
0.8692 = Validation score (accuracy)
28.49s = Training runtime
0.27s = Validation runtime
Fitting model: RandomForestEntr ...
Fitting with cpus=2, gpus=0
0.8725 = Validation score (accuracy)
27.6s = Training runtime
0.26s = Validation runtime
Fitting model: CatBoost ...
Fitting with cpus=1, gpus=0
0.8934 = Validation score (accuracy)
29.3s = Training runtime
0.01s = Validation runtime
Fitting model: ExtraTreesGini ...
Fitting with cpus=2, gpus=0
0.8747 = Validation score (accuracy)
28.45s = Training runtime
0.27s = Validation runtime
Fitting model: ExtraTreesEntr ...
Fitting with cpus=2, gpus=0
0.8681 = Validation score (accuracy)
35.84s = Training runtime
0.26s = Validation runtime
Fitting model: NeuralNetFastAI ...
Fitting with cpus=1, gpus=0, mem=0.2/10.2 GB
No improvement since epoch 7: early stopping
0.8945 = Validation score (accuracy)
19.07s = Training runtime
0.03s = Validation runtime
Fitting model: XGBoost ...
Fitting with cpus=1, gpus=0
0.8736 = Validation score (accuracy)
11.33s = Training runtime
0.06s = Validation runtime
Fitting model: NeuralNetTorch ...
Fitting with cpus=1, gpus=0, mem=0.1/10.1 GB
0.8802 = Validation score (accuracy)
144.68s = Training runtime
0.22s = Validation runtime
Fitting model: LightGBMLarge ...
Fitting with cpus=1, gpus=0, mem=0.5/9.8 GB
0.8989 = Validation score (accuracy)
10.67s = Training runtime
0.36s = Validation runtime
Fitting model: WeightedEnsemble_L2 ...
Ensemble Weights: {'LightGBMLarge': 0.455, 'NeuralNetFastAI': 0.364, 'RandomForestEntr': 0.182}
0.9099 = Validation score (accuracy)
0.27s = Training runtime
0.0s = Validation runtime
AutoGluon training complete, total runtime = 355.44s ... Best model: WeightedEnsemble_L2 | Estimated inference throughput: 1386.0 rows/s (910 batch size)
Disabling decision threshold calibration for metric `accuracy` due to having fewer than 10000 rows of validation data for calibration, to avoid overfitting (910 rows).
`accuracy` is generally not improved through threshold calibration. Force calibration via specifying `calibrate_decision_threshold=True`.
TabularPredictor saved. To load, use: predictor = TabularPredictor.load("/content/drive/MyDrive/Books_Writings/NLPBook/AutogluonModels/ag-20251129_203619")
CPU times: user 6min 30s, sys: 2.87 s, total: 6min 33s
Wall time: 6min
y_test = test_data['Label']
test_data_nolabel = test_data.drop(labels=['Label'],axis=1)
y_pred = predictor.predict(test_data_nolabel)
perf = predictor.evaluate_predictions(y_true=y_test, y_pred=y_pred, auxiliary_metrics=True)
print(perf)
{'accuracy': 0.8883025505716798, 'balanced_accuracy': np.float64(0.7570827489481067), 'mcc': np.float64(0.5896585148730508), 'f1': 0.6422535211267606, 'precision': 0.7702702702702703, 'recall': 0.5507246376811594}
%%time
## SHAP
train_data_wo_label = train_data.drop(['Label'], axis=1)
# Example case with 100 instances
test_data_wo_label = test_data.drop(['Label'], axis=1)[:100]
labels = [name for name in test_data_wo_label]
predict_proba = lambda data : predictor.predict_proba(pd.DataFrame(data, columns=labels))
sampled_background_data = shap.sample(train_data_wo_label, 100)
explainer = shap.KernelExplainer(model=predict_proba, data=shap.kmeans(sampled_background_data,10), link='logit')
shap_values = explainer.shap_values(test_data_wo_label[:100], nsamples=50, l1_reg='num_features(10)')
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 1 iterations, i.e. alpha=3.909e-02, with an active set of 1 regressors, and the smallest cholesky pivot element being 2.220e-16. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 3 iterations, i.e. alpha=3.223e-02, with an active set of 3 regressors, and the smallest cholesky pivot element being 6.664e-08. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 7 iterations, i.e. alpha=1.959e-02, with an active set of 6 regressors, and the smallest cholesky pivot element being 5.162e-08. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 9 iterations, i.e. alpha=3.846e-02, with an active set of 9 regressors, and the smallest cholesky pivot element being 5.960e-08. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 4 iterations, i.e. alpha=2.470e-02, with an active set of 4 regressors, and the smallest cholesky pivot element being 4.215e-08. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 8 iterations, i.e. alpha=8.749e-03, with an active set of 8 regressors, and the smallest cholesky pivot element being 4.215e-08. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 6 iterations, i.e. alpha=6.129e-03, with an active set of 6 regressors, and the smallest cholesky pivot element being 4.215e-08. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 1 iterations, i.e. alpha=2.677e-02, with an active set of 1 regressors, and the smallest cholesky pivot element being 5.162e-08. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 7 iterations, i.e. alpha=8.609e-03, with an active set of 6 regressors, and the smallest cholesky pivot element being 2.220e-16. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 6 iterations, i.e. alpha=1.445e-02, with an active set of 6 regressors, and the smallest cholesky pivot element being 8.429e-08. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 3 iterations, i.e. alpha=3.811e-03, with an active set of 3 regressors, and the smallest cholesky pivot element being 4.215e-08. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 8 iterations, i.e. alpha=2.588e-03, with an active set of 8 regressors, and the smallest cholesky pivot element being 5.162e-08. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 7 iterations, i.e. alpha=6.785e-02, with an active set of 7 regressors, and the smallest cholesky pivot element being 5.960e-08. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 5 iterations, i.e. alpha=2.971e-02, with an active set of 5 regressors, and the smallest cholesky pivot element being 2.220e-16. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 7 iterations, i.e. alpha=3.748e-02, with an active set of 7 regressors, and the smallest cholesky pivot element being 2.220e-16. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 8 iterations, i.e. alpha=2.462e-02, with an active set of 8 regressors, and the smallest cholesky pivot element being 5.960e-08. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 5 iterations, i.e. alpha=2.055e-03, with an active set of 5 regressors, and the smallest cholesky pivot element being 5.162e-08. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 8 iterations, i.e. alpha=1.176e-03, with an active set of 8 regressors, and the smallest cholesky pivot element being 5.162e-08. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 9 iterations, i.e. alpha=1.972e-02, with an active set of 9 regressors, and the smallest cholesky pivot element being 5.960e-08. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 2 iterations, i.e. alpha=2.073e-01, with an active set of 2 regressors, and the smallest cholesky pivot element being 7.300e-08. Reduce max_iter or increase eps parameters.
warnings.warn(
/usr/local/lib/python3.12/dist-packages/sklearn/linear_model/_least_angle.py:723: ConvergenceWarning: Regressors in active set degenerate. Dropping a regressor, after 5 iterations, i.e. alpha=1.036e-01, with an active set of 5 regressors, and the smallest cholesky pivot element being 2.980e-08. Reduce max_iter or increase eps parameters.
warnings.warn(
CPU times: user 1min 30s, sys: 32.8 s, total: 2min 3s
Wall time: 2min 27s
test_data
| Label | absolutely | accident | account | across | actually | affected | ago | air | airplane | ... | wreck | wrong | yall | yeah | year | yes | yesterday | yet | young | youre | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 253 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2032 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9574 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7390 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9283 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 8985 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4675 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5885 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 10257 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3762 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
2274 rows × 501 columns
shap.initjs()
j = randint(0,len(test_data_wo_label))
print("Instance# :",j)
class_index = 0
shap.force_plot(explainer.expected_value[class_index], shap_values[j, :, class_index], test_data_wo_label.iloc[j,:])
Instance# : 16
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
shap.initjs()
class_index = 1
shap.force_plot(explainer.expected_value[class_index], shap_values[j, :, class_index], test_data_wo_label.iloc[j,:])
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
explainer.expected_value.shape
(2,)
len(shap_values[0][j][:50])
2
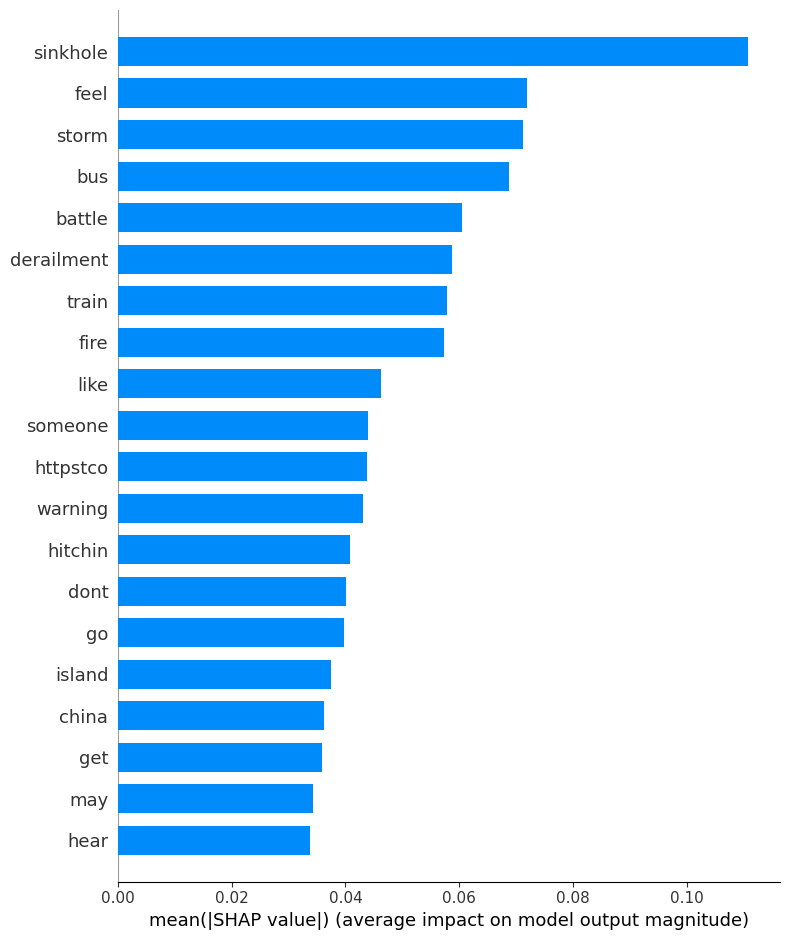
print ("Summary plot")
class_index = 0
shap.summary_plot(shap_values[:,:,class_index], test_data_wo_label, plot_type="bar")
explanation = shap.Explanation(values=shap_values[:,:,class_index],
data=test_data_wo_label.values,
feature_names=test_data_wo_label.columns,
base_values=explainer.expected_value)
shap.initjs()
# Now use the explanation object for the beeswarm plot
shap.plots.beeswarm(explanation)
Summary plot
/tmp/ipython-input-3610792517.py:3: FutureWarning: The NumPy global RNG was seeded by calling `np.random.seed`. In a future version this function will no longer use the global RNG. Pass `rng` explicitly to opt-in to the new behaviour and silence this warning.
shap.summary_plot(shap_values[:,:,class_index], test_data_wo_label, plot_type="bar")
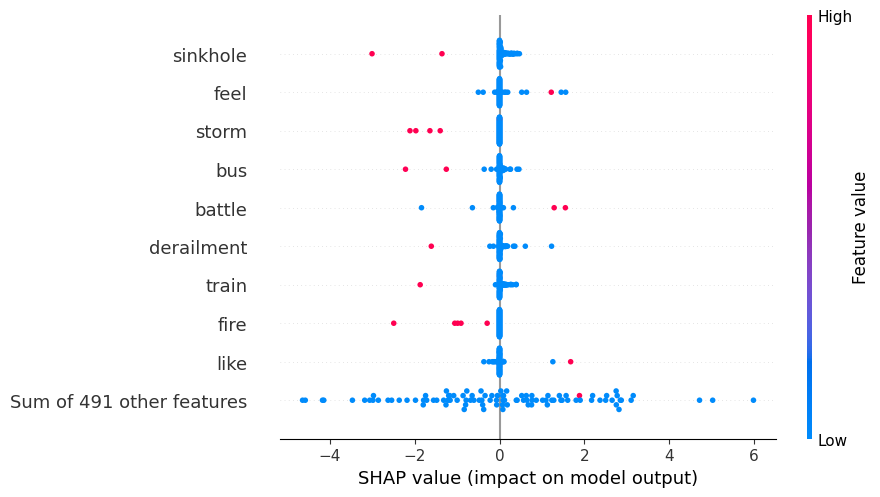
48.25. AutoGluon XAI using Column Permutations#
https://auto.gluon.ai/dev/api/autogluon.tabular.TabularPredictor.feature_importance.html
%%time
feat_imp = predictor.feature_importance(data=test_data, model=None, features=None,
feature_stage='original', subsample_size=1000,
time_limit=500, # number of seconds
num_shuffle_sets=None,
include_confidence_band=True,
confidence_level=0.99, silent=False)
print(feat_imp)
Computing feature importance via permutation shuffling for 500 features using 1000 rows with 10 shuffle sets... Time limit: 500s...
4511.73s = Expected runtime (451.17s per shuffle set)
455.24s = Actual runtime (Completed 2 of 10 shuffle sets) (Early stopping due to lack of time...)
importance stddev p_value n p99_high p99_low
warning 0.0080 0.000000 0.500000 2 0.008000 0.008000
thunderstorm 0.0070 0.000000 0.500000 2 0.007000 0.007000
police 0.0050 0.000000 0.500000 2 0.005000 0.005000
fire 0.0040 0.002828 0.147584 2 0.131313 -0.123313
sinkhole 0.0035 0.000707 0.045167 2 0.035328 -0.028328
... ... ... ... .. ... ...
jan -0.0010 0.000000 0.500000 2 -0.001000 -0.001000
natural -0.0015 0.000707 0.897584 2 0.030328 -0.033328
caused -0.0015 0.000707 0.897584 2 0.030328 -0.033328
update -0.0020 0.001414 0.852416 2 0.061657 -0.065657
today -0.0020 0.001414 0.852416 2 0.061657 -0.065657
[500 rows x 6 columns]
CPU times: user 10min 2s, sys: 20.7 s, total: 10min 23s
Wall time: 7min 35s
feat_imp[:10]
| importance | stddev | p_value | n | p99_high | p99_low | |
|---|---|---|---|---|---|---|
| warning | 0.0080 | 0.000000 | 0.500000 | 2 | 0.008000 | 0.008000 |
| thunderstorm | 0.0070 | 0.000000 | 0.500000 | 2 | 0.007000 | 0.007000 |
| police | 0.0050 | 0.000000 | 0.500000 | 2 | 0.005000 | 0.005000 |
| fire | 0.0040 | 0.002828 | 0.147584 | 2 | 0.131313 | -0.123313 |
| sinkhole | 0.0035 | 0.000707 | 0.045167 | 2 | 0.035328 | -0.028328 |
| man | 0.0035 | 0.002121 | 0.128881 | 2 | 0.098985 | -0.091985 |
| collision | 0.0035 | 0.002121 | 0.128881 | 2 | 0.098985 | -0.091985 |
| earthquake | 0.0030 | 0.001414 | 0.102416 | 2 | 0.066657 | -0.060657 |
| crash | 0.0030 | 0.000000 | 0.500000 | 2 | 0.003000 | 0.003000 |
| year | 0.0025 | 0.000707 | 0.062833 | 2 | 0.034328 | -0.029328 |
48.26. Using Captum from Facebook#
Facebook has done an incredible job of offering explainability on tabular, image and text models. Please do try and use Captum as much as possible. For NLP, see this example:
https://captum.ai/tutorials/IMDB_TorchText_Interpret
Image("NLP_images/XAI_CheatSheet.png",width=800)
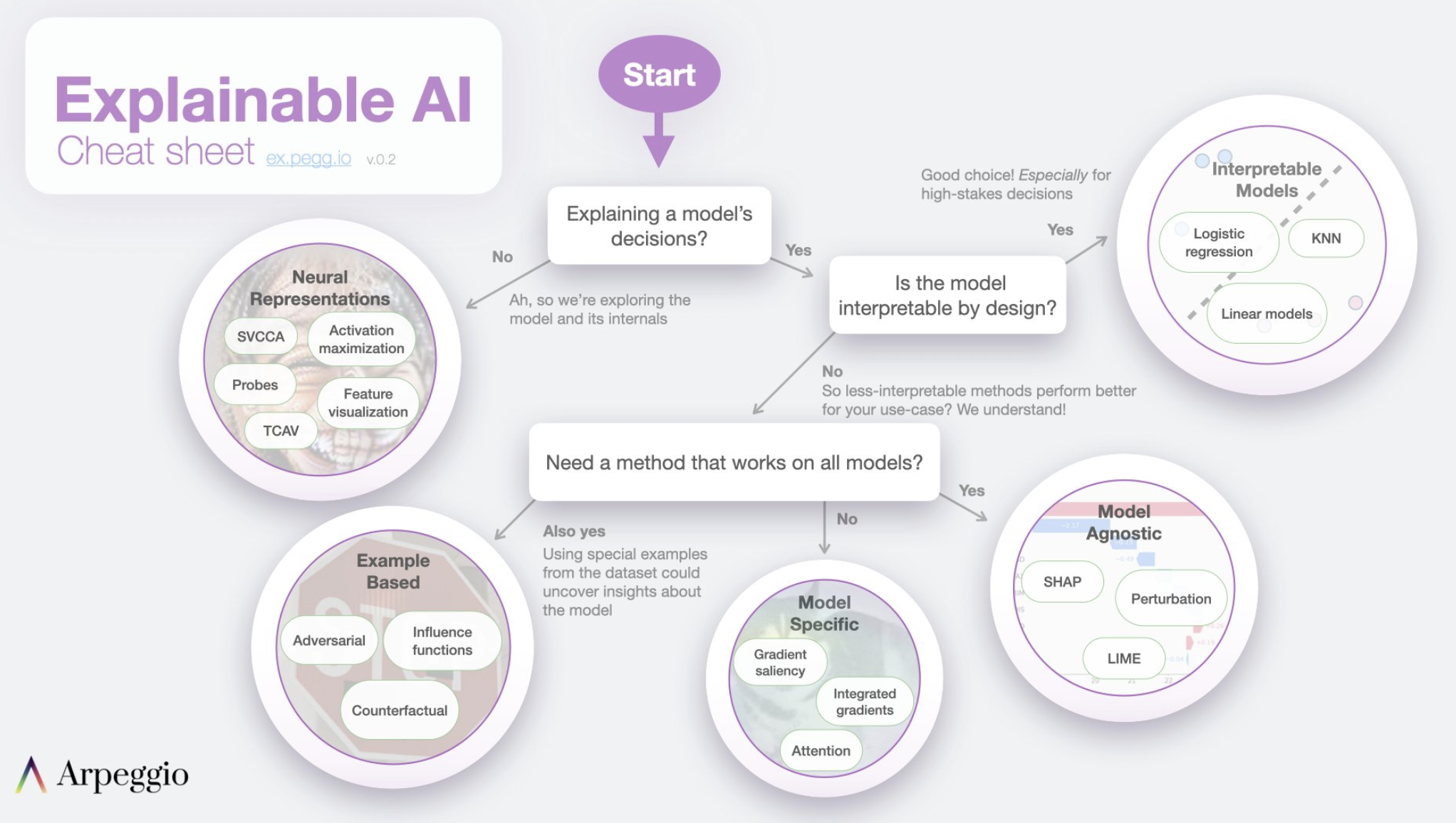
48.27. LLM XAI#
4 Measurement Categories for Evaluating LLMs: https://drive.google.com/file/d/16e70L2Y2otBn9VCqjY_LfixAex5ZGL6h/view?usp=sharing (Sebastian Raschka)
LLMs are explainable: https://timkellogg.me/blog/2023/10/01/interpretability
Review SHAP Github: shap/shap
Review SHAP docs: https://shap.readthedocs.io/en/latest/
48.28. Mechanistic Interpretability#
Read: https://seantrott.substack.com/p/mechanistic-interpretability-for
Detailed resource page: https://www.neelnanda.io/mechanistic-interpretability/getting-started
LLMs are often treated as “black boxes” - we can see inputs and outputs, but lack understanding of the internal mechanisms. This is a potential concern as LLMs become more widely deployed, so there is a need to better understand and control their behavior.
Mechanistic interpretability (MI) is the field of study that aims to reverse-engineer neural networks by understanding their internal computations and representations in human-understandable terms. The goal is to go beyond just knowing that a model works, to understanding how it works under the hood.
MI is operationalized in three ways:
Classifier probes: Training classifiers on representations from different LLM layers to identify which ones encode particular information.
Activation patching: Selectively replacing activations to understand which components are most responsible for predictions.
Sparse auto-encoders: Learning a compressed, sparse representation of the LLM’s internal workings to make them more interpretable.
There are debates about whether fully mechanistic explanations of LLMs are possible, given their complexity. Even if feasible, some question whether mechanistic interpretability will actually be the most useful approach for predicting and controlling LLM behavior compared to other methods.
Review papers: https://arxiv.org/abs/2404.14082; https://arxiv.org/abs/2407.02646
See this amazing visualization of LLM interpretability by looking at the internals of the model: https://pair.withgoogle.com/explorables/patchscopes/
Code for MI: TransformerLensOrg/TransformerLens