
45. Reinforcement Learning#
A brief introduction to dynamic programming, reinforcement learning, and Q-functions.
This offers an idea of the concepts needed to understand Deep-Q learning.
General class notes on RL: https://srdas.github.io/RLBook2/
My co-author, Harshad Khadilkar ran a Deep RL workshop in 2024: https://www.cse.iitb.ac.in/~harshadk/
import matplotlib.pyplot as plt
import os
import pandas as pd
import numpy as np
%pylab inline
Populating the interactive namespace from numpy and matplotlib
45.1. Introduction#
Reinforcement Learning (RL) has become popular in the pantheon of deep learning with video games, checkers, and chess playing algorithms. DeepMind trained an RL algorithm to play Atari, Mnih et al (2013). More recently, just two years ago, DeepMind’s Go playing system used RL to beat the world’s leading player, Lee Sedol, and Silver at al (2016) provides a good overview of their approach. There are many good books one may refer to for RL. See for example, Sutton and Barto (1998); Sutton and Barto (2015); Sugiyama (2015).
In the area of finance, there has been intermittent progress over the years, as dynamic programming has been scaled up using RL, as evidenced by many papers: Moody and Saffell (2001); Dempster and Leemans (2006); Corazza and Bertoluzzo (2016); Duarte (2017); and Jiang, Xu, Liang (2017).
RL is the deep learning application of the broader arena of dynamic programming. It is an algorithm that attempts to maximize the long-term value of a strategy by optimal action at every point in time, where the action taken depends on the state of the observed system. All these constructs are determined by functions of the state \(S\) of the system. The value of the long-term strategy is called the “value” function \(V(S)\),and the optimal action at any time is known as the decision or “policy” function \(P(S)\). Note that the state may also include the time \(t\) at which the system is observed.
45.2. Dynamic Programming#
Dynamic programming (DP) was formalized by Richard Bellman in his pioneering book, see Bellman (1957). See also Howard (1966). We initiate our discussion here with an example of dynamic programming.
45.3. Card Game#
Take a standard deck of 52 playing cards, and shuffle it. Given a randomly shuffled set of cards, you are allowed to pick one at a time, replace and reshuffle the deck, and draw again, up to a maximum of 10 cards. You may stop at any time, and collect money as follows. If you have an ace, you get \(\$14\). Likewise, a king, queen, and jack return you \(\$13, \$12, \$11\), respectively. The remaining cards give you their numeric value. Every time you draw a card, you can decide if you want to terminate the game and cash in the value you hold, or discard the card and try again.
The problem you are faced with is to know when to stop and cash in, which depends on the number of remaining draws \(n\), and the current card value \(x\) that you hold. Therefore, the state of the system at draw \(t\) is defined by the current card value \(x_t\) and the number of remaining draws, \(10-t\), i.e., \(S = (x_t,10-t)\). The policy function is binary as follows:
The value function is likewise a function of the state, i.e., \(V(x_t,10-t)\).
These problems are solved using backward recursion, also known as dynamic programming. To begin we assume we are at the last draw (\(\#10\)), having decided to reject all preceding 9 values. The expected value of the draw will be the average of the value of all 13 cards ranging from 2 to 14, i.e., \((2+3+...+13+14)/13 = 8\). The expected value of the strategy is
Now, roll back to \(t=9\), and work out the optimal policy function. We already know that if we hold on till \(t=10\), our expected value is 8. So if \(x_9 < 8\), we hold on, else we terminate the strategy if \(x_9 \geq 8\). (Note that if we are risk averse, we prefer 8 now than the expected value of 8 in the next draw.) The expected value of the strategy is:
Now, roll back to \(t=8\). We have worked out that if we hold on till \(t=9\), our expected value is 9.62. So if \(x_8 \leq 9\), we “Continue”, else we “Halt” the strategy if \(x_8 \geq 10\). The expected value of the strategy is:
And so on …
We can write a small program to solve the entire problem with the policy cutoffs at each \(t\).
import numpy as np
# Dynamic Program to solve the cards problem
T = 10
cards = np.arange(2, 15) # Equivalent to 2:14 in R
n = len(cards)
V = np.zeros(10) # Value of optimal policy at each t
P = np.zeros((13, 10)) # Policy {0,1} for all possible cards x at all t
t = 9 # Python uses 0-based indexing, so adjust t accordingly
V[t] = np.mean(cards)
print(t + 1, V[t]) # Adjust t for printing to match R output
for t in range(8, -1, -1): # Iterate in reverse from 8 to 0
idx = np.where(cards >= V[t + 1])
V[t] = np.sum(cards[idx]) / n + V[t + 1] * (n - len(cards[idx])) / n
P[idx, t] = 1
print(t + 1, V[t]) # Adjust t for printing to match R output
10 8.0
9 9.615384615384617
8 10.532544378698226
7 11.137915339098772
6 11.56762718392213
5 11.898174756863177
4 12.152442120663983
3 12.359758717484908
2 12.53518045325646
1 12.683614229678543
As we can see from the first set of values, \(V_t\), the expected value of the strategy is the highest with a large number of remaining draws. And then declines as we get closer to the end. The table of the policy function \(P_t\) shown next, has the card values on the rows and the draw number on the columns.
P = np.c_[np.arange(2, 15), P]
P[:, T] = 1
print(P)
[[ 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[ 3. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[ 4. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[ 5. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[ 6. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[ 7. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[ 8. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1.]
[ 9. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1.]
[10. 0. 0. 0. 0. 0. 0. 0. 1. 1. 1.]
[11. 0. 0. 0. 0. 0. 0. 1. 1. 1. 1.]
[12. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1.]
[13. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[14. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]]
The first column above gives the card values. The next 10 columns show the 10 draws, with each column containing values \(\{0,1\}\), where \(0\) stands for “Continue” and \(1\) stands for “Halt”. Clearly if you draw a high value card, you will halt sooner.
To summarize, the vector \(V\) showed the value function at each \(t\), and the matrix \(P\) shows the decision rule for each \(x_t\). Notice that the problem was solved using “backward recursion”. The value of the entire 10 draws at the beginning of the strategy is \(12.68\), and is obtained from the value function.
Where does deep learning (specifically RL) enter this problem setting? The short answer is that when the state space \(S\) becomes too large, it is hard to find explicit functions for the optimal policy function and the value function. These are then approximated using deep neural nets.
45.4. Random Policy Generation#
In the preceding analysis, we have calculated the exact policy for all states \((x_t,T-t)\). This is in the form of the policy function \(P(x_t,T-t)\), which in the example above was a decision to terminate the game (value 1) or continue (value 0), presented in a grid \(P\) of dimension \(13 \times 10\).
Rather than use backward recursion, we may instead employ random policy generation. This would entail random generation of policies in a grid of the same dimension, i.e., populate the grid with values \(\{0,1\}\), and then assess the value function using the policy grid for a large random set of draws. Hence, the random policy is discovered in two steps:
Generate 10,000 paths of 10 card draws, i.e., a sequence of 10 numbers randomly generated from values \(2,3,...,13,14\).
Generate 1,000 random policy grids, and assess each one for expected value, i.e., determine the value function.
First, we generate the random draws.
#Generate the random paths of card draws
T = 10
m = 10000
draws = np.random.randint(2, 15, size=(m, T))
Next, we generate the policy functions and assess them for which one is best.
#Generate random policy functions in a list
n_policies = 1000
policies = []
for j in range(n_policies):
pol = np.round(np.random.rand(13, T)) # Generate random policy matrix
pol[:, T - 1] = 1 # Set last column to 1 (0-based indexing)
policies.append(pol) # Add policy to list
# An example policy function
pol
array([[1., 1., 0., 0., 1., 0., 0., 1., 0., 1.],
[0., 1., 0., 0., 0., 1., 0., 1., 1., 1.],
[1., 1., 0., 0., 1., 1., 1., 1., 1., 1.],
[0., 0., 1., 1., 1., 1., 0., 1., 0., 1.],
[1., 1., 1., 1., 0., 0., 0., 1., 1., 1.],
[0., 1., 0., 0., 0., 1., 1., 1., 1., 1.],
[0., 1., 1., 0., 0., 1., 1., 1., 0., 1.],
[0., 1., 1., 0., 1., 0., 1., 0., 0., 1.],
[0., 0., 1., 0., 0., 1., 1., 1., 0., 1.],
[1., 0., 0., 0., 1., 1., 0., 0., 0., 1.],
[0., 0., 1., 0., 0., 1., 1., 1., 1., 1.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 1.],
[0., 1., 0., 0., 1., 0., 0., 0., 0., 1.]])
We write a function that evaluates each policy for its expected value over all 10,000 games in the draws matrix.
#game is a row of 10 cards; policy is a 13x10 matrix
def valueGP(game, policy):
t = 0
for card in game:
t += 1 # Increment t by 1
if policy[card - 2, t - 1] == 1: # 0-based indexing
break
return card
def valueFN(draws, policy):
v = np.zeros(draws.shape[0]) # Use draws.shape[0] for number of rows
for j in range(draws.shape[0]):
v[j] = valueGP(draws[j, :], policy) # Pass the row of draws
return np.mean(v)
We test all policies over all games.
%%time
value_functions = np.zeros(n_policies)
for j in range(n_policies):
value_functions[j] = valueFN(draws, policies[j])
CPU times: user 15.4 s, sys: 8.61 ms, total: 15.4 s
Wall time: 15.6 s
Find the policy with the highest value.
%%time
idx = np.argmax(value_functions) # Find index of maximum value
print(f"Value function for best policy = {value_functions[idx]}") # Print the value
best_policy = policies[idx] # Get the best policy
print(best_policy) # Print the best policy
Value function for best policy = 9.8479
[[0. 1. 1. 0. 0. 0. 0. 1. 1. 1.]
[0. 0. 1. 1. 1. 1. 1. 0. 0. 1.]
[0. 0. 0. 0. 0. 1. 1. 0. 1. 1.]
[0. 0. 1. 0. 1. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 1. 1. 0. 0. 1.]
[1. 1. 0. 0. 1. 1. 1. 0. 0. 1.]
[1. 1. 0. 1. 1. 1. 0. 0. 1. 1.]
[1. 0. 1. 0. 0. 0. 0. 1. 0. 1.]
[0. 0. 1. 1. 1. 1. 1. 0. 0. 1.]
[1. 1. 0. 1. 0. 1. 0. 1. 1. 1.]
[1. 1. 1. 0. 1. 0. 1. 0. 1. 1.]
[1. 1. 1. 0. 0. 1. 1. 1. 0. 1.]
[1. 1. 1. 1. 0. 0. 0. 0. 1. 1.]]
CPU times: user 91 µs, sys: 999 µs, total: 1.09 ms
Wall time: 1.71 ms
We can see that this is hardly an optimal policy, as the analytical solution has a value function of \(12.68361\). We can see that the policy grid is very different from the optimal one, which has 0s in the upper region and 1s in the lower region.
You can see that Monte Carlo is not an ideal optimization strategy as it is hardly exhaustive. The total number of policies that are possible even in this small case is \(2^{13 \times 10}\), which is HUGE.
45.5. Policy Gradient Search#
In this modeling approach we assess each point in the \(13 \times 10\) policy grid and determine if flipping the value improves the value function. In this way we hope to use gradient approach in a simple way. To start with we randomly generate policy matrix \(P\). We will work this by going down the columns of the policy matrix \(P\). Starting with the first element of the first column, holding all other cells of \(P\) constant, we evaluate the policy for both values of \(P(1,1) \in \{0,1\}\), and then we set it to be the value that returns the best value function. We then move on to trying both values of \(P(2,1)\) and again choose the best one. We proceed like this through all cells of the policy matrix. This completes one epoch, and generates a new policy matrix. We can repeat this process for as many epochs as we like, till the improvement in the value function is immaterially small.
# Randomly generate an initial policy function
# Assuming T, draws, and valueFN are already defined
pol = np.round(np.random.rand(13, T)) # Generate random policy matrix
pol[:, T - 1] = 1 # Set last column to 1 (0-based indexing)
v = valueFN(draws, pol) # Initial value function
for epoch in range(1, 4): # Iterate over epochs 1 to 3
for j in range(T - 1): # Iterate over columns (0 to T-2)
for i in range(13): # Iterate over rows (0 to 12)
x = pol[i, j]
pol_new = pol.copy() # Create a copy of pol
pol_new[i, j] = abs(x - 1) # Flip the bit
v_new = valueFN(draws, pol_new)
if v_new >= v:
v = v_new
pol = pol_new.copy() # Update pol with the new policy
print(f"Epoch {epoch} value function = {v}") # Print epoch and value function
Epoch 1 value function = 11.0821
Epoch 2 value function = 12.3459
Epoch 3 value function = 12.6777
This simple approach is run over three epochs, i.e., we adjust each of the policy function weights thrice, taking one weight gradient at a time. The final value function is very close to the optimal value from the analytical solution. The policy function is as follows.
pol
array([[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 1.],
[0., 0., 0., 0., 0., 0., 0., 1., 1., 1.],
[0., 0., 0., 0., 0., 0., 1., 1., 1., 1.],
[0., 0., 0., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]])
It appears to be very close to the one generated analytically.
45.6. Q-Learning#
Here is a Tabular-Q RL formulation of the problem that we discussed above. We will use a grid-based function to describe the relationship between the state, policy, and value function. (Later, we will use deep learning nets (DLNs) to approximate this function.) We determine the “state-action” function, also known as the \(Q(S,A)\) function, where \(S\) is the state, and \(A\) is the action (both possibly residing in high-dimension tensors). In our cards problem, state \(S=\{x,n\}\) and action \(A=\{0,1\}\). A didactic exposition follows. The function \(Q(S,A)\) stores the current best learned value of optimal action \(A\) at each state \(S\), and through iteration over simulated game play, it gets better and better. This is the essence of reinforcement \(Q\)-learning.
Useful References
45.7. Implementation in Python#
Our implementation will be in Python. We first establish some basic input parameters that we will need. We designate the vector “cards” to hold the value of each card, where recall that, aces equal 14. We define the number of periods \(N=10\) and the number of card values \(M=13\) as constants for our problem.
cards = [2,3,4,5,6,7,8,9,10,11,12,13,14] #2 to Ace
N = 10 # number of periods
M = 13 # cards
Since simulation will be used to solve the problem, we need to generate a set of \(N\) card draws, which constitutes one instance of a game. We use the randint function here.
# Function to return a set of sequential card draws with replacement
from random import randint
def onecard():
return randint(2,M+1)
def game(N):
game = [onecard() for j in range(N)]
return game
print(game(N))
[3, 2, 7, 11, 7, 13, 8, 8, 12, 9]
The output is a random set of \(N\) card values, drawn with replacement. Every time this code block is run, we will get a different set of \(N\) cards.
45.8. State-Action Reward and \(Q\) Tensors#
We set up two matrices (tensors) for the \(Q(x,n;A)\) function and the reward function \(R(x,n;A)\). These are 3D matrices, one dimension for each of the arguments. The reward matrix is static and is set up once and never changed. This is because it is a one-step reward matrix between \((x,n;A)\) and \((x',n-1;A')\), with the reward in between. (\(x'\) and \(A'\) are the next period state and action, respectively.) It is often known as the SARSA structure, i.e., the state-action-reward-state-action algorithm.
We initialize the “reward” matrix which contains the reward in every possible state in the 3D tensor.
#Reward matrix (static)
#initialize
R = np.zeros((M,N,2)) #for M cards, N remaining draws, 2 actions
#When the action is 0="continue" then leave the reward as zero
#When the action is 1="halt" then take card value
for j in range(13):
R[j,:,1] = j+2
R[:,N-1,0] = cards
We print out the result below, which is a rather long 2D rendition of the 3D tensor. The structure of the three dimensions is \([x, n, a]\), so that each tableau segment below is for one \(x\) (card value). The rows below are for each draw \(n\) and the columns are for each action \(a=\{0,1\}\). Note that for all \(n<N\), the reward value of action \(a=0\) is zero, as the player does not cash out. For all \(n<N\), the reward is \(x\), the card value. Only at \(n=N\) do we see that \(R(x,n;a)=x\), because you will take whatever you get in the final card draw (see that the entire last row in each tableau is \(x\)). The reward matrix remains fixed throughout the run of the algorithm.
# Check
R
array([[[ 0., 2.],
[ 0., 2.],
[ 0., 2.],
[ 0., 2.],
[ 0., 2.],
[ 0., 2.],
[ 0., 2.],
[ 0., 2.],
[ 0., 2.],
[ 2., 2.]],
[[ 0., 3.],
[ 0., 3.],
[ 0., 3.],
[ 0., 3.],
[ 0., 3.],
[ 0., 3.],
[ 0., 3.],
[ 0., 3.],
[ 0., 3.],
[ 3., 3.]],
[[ 0., 4.],
[ 0., 4.],
[ 0., 4.],
[ 0., 4.],
[ 0., 4.],
[ 0., 4.],
[ 0., 4.],
[ 0., 4.],
[ 0., 4.],
[ 4., 4.]],
[[ 0., 5.],
[ 0., 5.],
[ 0., 5.],
[ 0., 5.],
[ 0., 5.],
[ 0., 5.],
[ 0., 5.],
[ 0., 5.],
[ 0., 5.],
[ 5., 5.]],
[[ 0., 6.],
[ 0., 6.],
[ 0., 6.],
[ 0., 6.],
[ 0., 6.],
[ 0., 6.],
[ 0., 6.],
[ 0., 6.],
[ 0., 6.],
[ 6., 6.]],
[[ 0., 7.],
[ 0., 7.],
[ 0., 7.],
[ 0., 7.],
[ 0., 7.],
[ 0., 7.],
[ 0., 7.],
[ 0., 7.],
[ 0., 7.],
[ 7., 7.]],
[[ 0., 8.],
[ 0., 8.],
[ 0., 8.],
[ 0., 8.],
[ 0., 8.],
[ 0., 8.],
[ 0., 8.],
[ 0., 8.],
[ 0., 8.],
[ 8., 8.]],
[[ 0., 9.],
[ 0., 9.],
[ 0., 9.],
[ 0., 9.],
[ 0., 9.],
[ 0., 9.],
[ 0., 9.],
[ 0., 9.],
[ 0., 9.],
[ 9., 9.]],
[[ 0., 10.],
[ 0., 10.],
[ 0., 10.],
[ 0., 10.],
[ 0., 10.],
[ 0., 10.],
[ 0., 10.],
[ 0., 10.],
[ 0., 10.],
[10., 10.]],
[[ 0., 11.],
[ 0., 11.],
[ 0., 11.],
[ 0., 11.],
[ 0., 11.],
[ 0., 11.],
[ 0., 11.],
[ 0., 11.],
[ 0., 11.],
[11., 11.]],
[[ 0., 12.],
[ 0., 12.],
[ 0., 12.],
[ 0., 12.],
[ 0., 12.],
[ 0., 12.],
[ 0., 12.],
[ 0., 12.],
[ 0., 12.],
[12., 12.]],
[[ 0., 13.],
[ 0., 13.],
[ 0., 13.],
[ 0., 13.],
[ 0., 13.],
[ 0., 13.],
[ 0., 13.],
[ 0., 13.],
[ 0., 13.],
[13., 13.]],
[[ 0., 14.],
[ 0., 14.],
[ 0., 14.],
[ 0., 14.],
[ 0., 14.],
[ 0., 14.],
[ 0., 14.],
[ 0., 14.],
[ 0., 14.],
[14., 14.]]])
45.9. Q-Learning Algorithm#
Our reinforcement algorithm learns \(Q(x,n;a)\) by playing the game over and over, refining the \(Q\)-tensor through one epoch after another. The algorithm is described below.
System State: \((x, n)\), where \(x\) is the number of the card drawn at random, \(n\) is the number of steps to go. For example \(n = 10\) at the start of experiment, and the experiment stops when \(n = 0\).
Iteration (below) is used to compute \(Q(x,n; A)\), where \(A\) is the action and can take on take values of (i) \(A = 0\), i.e., continue the experiment and transition to the next state \((x', n-1)\), with a reward = \(0\); (ii) \(A = 1\), i.e., stop the experiment, reward = \(x\).
Initialize the \(Q\)-tensor to some initial values (\(=0\)), initialize to some state \((x, n)\), and repeat the following steps in a loop until remaining draws \(n = 0\):
Compute \(Q(x,n;0)\) and \(Q(x,n;1)\).
If \(Q(x,n, 0) > Q(x, n, 1)\), then choose Action 0, otherwise choose Action 1.
If the Action chosen is 0, then transition to next state \((x',n-1)\), where \(x'\) is chosen using a transition probability model. In the cards case, this probability is uniform across all states.
Compute \(Q(x',n-1,0)\) and \(Q(x',n-1,1)\) using the DLN. Choose the next Action \(A'\) depending upon which of these is larger.
Update the \(Q\) value of the original state using
\(Q(x,n,0) \leftarrow Q(x,n,0) + \alpha[0 + \gamma Q(x',n-1,A')-Q(x,n,0)]\)
\(Q(x,n,1) \leftarrow (1-\alpha) Q(x,n,1) + \alpha x\)
\(\gamma \leq 1\).
If \(A = 1\) or \(n = 0\), then re-initialize to some random \(x\) and go back to step 1. Otherwise set \(x \leftarrow x'\) and \(A \leftarrow A'\) and go back to step 1.
Learning rate \(\alpha\) is a hyperparameter, we start by setting it to 0.1. Also \(\gamma\) is the discount factor in the reward function.
In the following code, we develop the \(Q\)-function via Monte Carlo simulation. The function below contains the logic for executing one card draw, and the learning procedure therefrom. Given the state \(S=\{x,n\}\), the action \(A=\{0,1\}\) is drawn at random with equal probability to generate the reward \(R\) and also generate the next state \(S'=\{x',n+1\}\). We then consider the reward from optimal action \(A'\) next period. This reward will be the better of the two possible \(Q\) values next period, i.e., \(\max[Q(x',n+1;A=0), Q(x',n+1;A=1)]\). The functional form is as follows when \(A=0\), i.e., when the action is to hold on for another draw.
The current “quality” function \(Q\) is equal to current reward plus the discounted optimized reward in the following period, based on the conditional randomized state \((x',n+1 | x,n)\) chosen in the following period. Notice that \(\gamma\) here is the discount rate. The equation (Qiter) above leads to constantly increasing values in the \(Q\) tensor, and to normalize the values to be stable, the equation above is updated instead as follows.
Here, \(\alpha\) is the “learning rate” of \(Q\)-learning. Notice that we can further rewrite the equation above as
The analogous equation to this is used when action \(A'=1\) and the game terminates and the reward is collected.
All these functions are embedded in the code below.
# Running the Tabular Q-learning algorithm
def doOneDraw(x0,n0): #assumes that n0<10
#now, given x0,n0
a0 = np.random.randint(0,2) #index of action
#next
x1 = np.random.randint(0,M) #next state
Q[x0,n0,0] = Q[x0,n0,0] + alpha*(R[x0,n0,0] +
gamma*np.maximum(Q[x1,n0+1,0],Q[x1,n0+1,1]) - Q[x0,n0,0])
Q[x0,n0,1] = (1-alpha)*Q[x0,n0,1] + alpha*R[x0,n0,1]
if a0==0:
return [x1,n0+1] #draw another card
else:
return [x0,N] #terminate and take value of current card
This function is then called repeatedly to complete one game, which is called an “epoch”. The function that does one epoch is below.
def doOneGame(x):
n = 0
while n<(N-1):
[x,n] = doOneDraw(x,n)
if n==(N-1):
Q[x,n,0] = (1-alpha)*Q[x,n,0] + alpha*R[x,n,0] #in both actions it is the end
Q[x,n,1] = (1-alpha)*Q[x,n,1] + alpha*R[x,n,1]
Now we can initialize the \(Q\) matrix and \(\alpha, \gamma\).
#State-Action Value function
#Q-matrix
Q = np.zeros((M,N,2))
alpha = 0.25 #Learning rate
gamma = 1.00 #Discount rate
Finally, we run the entire algorithm for a large number of epochs.
%%time
#Run the epochs
epochs = 100000
Qdiff = np.zeros(epochs)
for j in range(epochs):
Q0 = np.copy(Q)
x = randint(0,M-1)
doOneGame(x)
Qdiff[j] = sum(((Q - Q0))**2)
CPU times: user 4.03 s, sys: 5.75 ms, total: 4.03 s
Wall time: 4.1 s
print("Policy Shape =", Q.shape)
print("Value Function")
print(Q[:,:,0])
print(Q[:,:,1])
Policy Shape = (13, 10, 2)
Value Function
[[12.41507907 12.11096248 12.09205216 11.85151853 11.61929076 10.74942876
11.25464722 8.16529389 6.60069244 1.99524318]
[12.34483187 12.37671223 11.95540822 11.95540491 11.56790334 10.86076807
10.71504761 8.99860244 8.8788962 2.97744916]
[12.58027298 12.17608223 11.63470779 11.5802302 11.48237531 11.2466192
10.41194377 9.15399671 6.62267572 3.90497094]
[12.44342169 12.37832125 12.23447058 12.18720185 11.40372684 11.12807599
10.61855471 12.20438682 8.55981293 4.88121368]
[12.44495558 12.38767784 11.89471359 11.47059938 11.06143326 10.59795712
10.22904349 8.6219182 6.39580797 5.91981923]
[12.52227035 12.16892677 11.92931243 11.86700005 11.12953418 10.54859021
10.51421529 8.66754428 6.17198299 6.94738137]
[12.48301133 12.16452354 12.07297865 11.89420629 11.52928274 11.11969441
10.06699052 11.37195333 10.85442871 7.93986443]
[12.63237715 12.10952932 12.79460728 11.90802907 11.44937297 11.30947628
10.97586676 10.75998774 8.77749523 8.78618462]
[12.59030538 12.29915689 11.88794561 12.12773441 11.52464859 11.16810976
9.91016792 9.70361216 5.82668977 9.68323648]
[12.39431848 12.31936878 12.00869729 11.90124552 11.63275014 11.04144374
10.67090149 9.8805372 8.48711282 10.65156013]
[12.55645567 12.50618847 12.09661014 11.70259312 11.00726402 11.30744514
10.82301445 8.43413868 9.85103036 11.87972885]
[12.78016231 12.20673089 11.88927459 12.11100974 11.34823318 10.77369547
9.87318027 10.48953491 6.12539421 12.95877424]
[12.37102447 12.1466676 11.95914654 11.53415941 12.13754028 10.91610411
11.33441556 9.47540079 5.87990652 13.75054873]]
[[ 2. 2. 2. 2. 2. 2.
2. 1.99999973 1.99952378 1.99524318]
[ 3. 3. 3. 3. 3. 3.
3. 2.99999773 2.99959819 2.97744916]
[ 4. 4. 4. 4. 4. 4.
4. 3.99999977 3.99286477 3.90497094]
[ 5. 5. 5. 5. 5. 5.
5. 4.99999979 4.99623728 4.88121368]
[ 6. 6. 6. 6. 6. 6.
6. 5.9999994 5.99919638 5.91981923]
[ 7. 7. 7. 7. 7. 7.
7. 6.99999995 6.99874993 6.94738137]
[ 8. 8. 8. 8. 8. 8.
8. 7.99999745 7.99919638 7.93986443]
[ 9. 9. 9. 9. 9. 9.
9. 8.99999839 8.99978546 8.78618462]
[10. 10. 10. 10. 10. 10.
10. 9.99999996 9.99821418 9.68323648]
[11. 11. 11. 11. 11. 11.
11. 11. 10.99965038 10.65156013]
[12. 12. 12. 12. 12. 12.
12. 11.99999932 11.99909593 11.87972885]
[13. 13. 13. 13. 13. 13.
13. 12.99999987 12.99587277 12.95877424]
[14. 14. 14. 14. 14. 14.
14. 13.99995545 13.99749985 13.75054873]]
# Expected value from best action at the outset
np.maximum(Q[:,0,0], Q[:,0,1]).mean()
np.float64(12.646715350130961)
Now, we can set up the signed value of the difference between actions (do not take card value vs take card value).
# POLICY FUNCTION from the Q Function
signed_matrix = Q[:,:,1] - Q[:,:,0]
binary_matrix = np.where(signed_matrix >= 0, 1, 0)
binary_matrix
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
45.10. Convergence#
Above the squared pointwise difference between successive tensors is computed by taking the following sum, noting that each scalar value of \(Q\) comes from a 3D tensor:
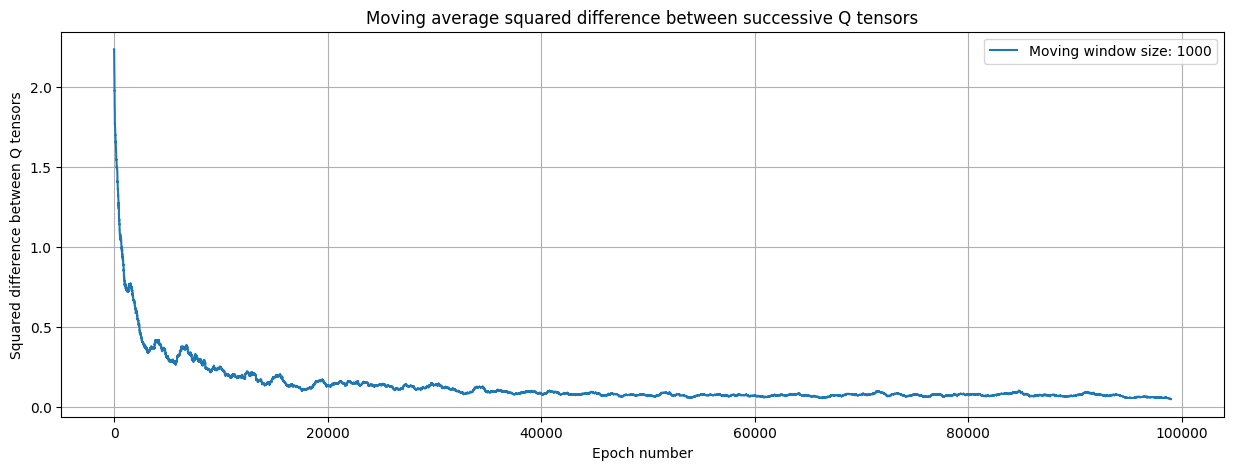
This is an oscillating sequence, that trends lower and lower to convergence. To smooth out the oscillations we take the moving average over 1% of the sequence at a time. See next.
The convergence is shown in the figure below
#Plot the Qdiff to see if it declines
window = int(epochs*0.01)
qd = pd.Series(Qdiff)
y = qd.rolling(window).mean()
plt.figure(figsize=(15,5))
plt.plot(range(len(y)-window),y[window:],label='Moving window size: '+str(window))
plt.grid()
plt.xlabel("Epoch number")
plt.ylabel("Squared difference between Q tensors")
# See previous block for error computation plotted here
plt.title("Moving average squared difference between successive Q tensors")
plt.legend()
<matplotlib.legend.Legend at 0x7ac5d844ed20>
It is also useful to examine the \(Q\) tensor after the algorithm has converged. We examine one slice of the tensor here, for \(n=4\).
If you examine the grid below it is of dimension \(13 \times 2\) and is the value of \(Q(x,4,A)\) for all values of \(x,A\) at time \(n=4\). This is a 2D slice of the 3D tensor for \(Q(x,n,A)\), the state-action value function. It tells us that the optimal action is 1 if the second column is bigger than the first, else action is 0. Clearly it is more optimal to stop at higher card values because the value in column 2 (where A=1) is much higher than in column 1 (where A=0).
#Let's see what it shows for n=4
#The two columns are for A=0 and A=1, rows being card values
Q[:,4,:]
array([[11.61929076, 2. ],
[11.56790334, 3. ],
[11.48237531, 4. ],
[11.40372684, 5. ],
[11.06143326, 6. ],
[11.12953418, 7. ],
[11.52928274, 8. ],
[11.44937297, 9. ],
[11.52464859, 10. ],
[11.63275014, 11. ],
[11.00726402, 12. ],
[11.34823318, 13. ],
[12.13754028, 14. ]])
45.11. Compute the optimal policy grid from the Q grid#
We can use the \(Q\) tensor to generate the optimal policy function based on whether \(A=0\) or \(A=1\) is optimal.
P = zeros((M,N))
P[:,N-1] = 1
for i in range(M):
for j in range(N):
if Q[i,j,1] > Q[i,j,0]:
P[i,j] = 1
print(P)
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 1.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 1.]
[0. 0. 0. 0. 0. 0. 1. 1. 1. 1.]
[0. 0. 0. 0. 0. 0. 1. 1. 1. 1.]
[0. 0. 0. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]]
We see that this is not the exact optimal \(P\) grid that we get from exact dynamic programming. So it is suboptimal. But we can assess the value function from this \(P\) grid by running samples below.
The optimal policy grid from dynamic programming was computed above, where the optimal value function is \(12.68\).
45.12. Compute expected value function for random sets#
We now calculate the value of the optimal policy from \(Q\)-learning.
Generate 10,000 sets of 10 random card draws, and then execute the strategy in the policy grid above and compute the expected value across all 10,000 sets to get the expected value function. The following code calculates the expected value of implementing the \(Q\)-learning optimal policy on the random set of games.
We plot the distribution of game outcomes for all games in the figure below.
def Vfunction(N):
cards = game(N)
for n in range(N):
if P[cards[n]-2,n]==1:
return cards[n]
The following code generates 10,000 games with \(N\) card draws each. And then computes the expectd value function across all games.
nsets = 10000
V = np.zeros(nsets)
for i in range(nsets):
V[i] = Vfunction(N)
plt.hist(V,100)
plt.grid()
plt.xlabel('Outcome of the game')
plt.ylabel('Frequency')
plt.title('Histogram of 10,000 game outcomes')
print("Expected Value Function E[V(S)] = ",np.mean(V))
Expected Value Function E[V(S)] = 12.6505
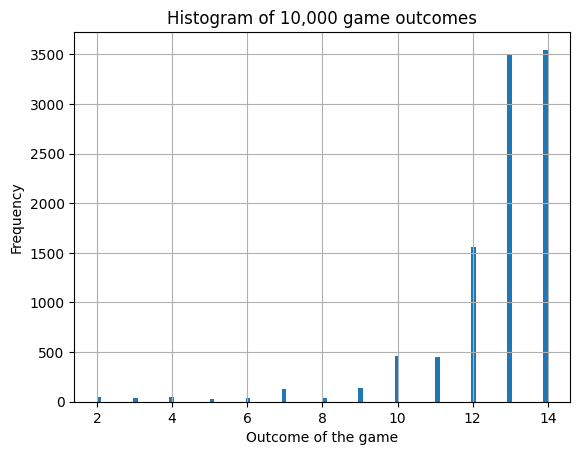
The value function is close to the analytical solution from dynamic programming, i.e., 12.68.
We also note that the solution worsens when we use \(\gamma < 1\) because the problem is then different from the one originally solved where we did not treat outcomes at different times differently. So we set \(\gamma=1\).
What about the \(\alpha\) parameter? It seems to be working well at \(\alpha=0.25\).
45.13. Q-learning with Deep Learning Nets vs Dynamic Programming#
Using DLNs makes sense only when the size of the state space or the action space is so large, that the usual dynamic programming (DP) procedure cannot be applied. We note also that in RL, unlike in DP, no backward recursion is necessary. Only forward simulation is applied.
For a small implementation of Deep-Q RL, see ericyangyu/PPO-for-Beginners
45.14. References#
There is an entire set of notes on RL, which may be accessed here: https://srdas.github.io/RLBook2/
Paper on goals-based portfolio optimization using RL: Das and Varma (2019).
MIT Lecture on Deep RL: https://introtodeeplearning.com/slides/6S191_MIT_DeepLearning_L5.pdf