
36. Chaining LLMs with LangChain#
How can we extend the functionality of LLMs in ways other than fine-tuning?
Exploiting LLM memory
Chains
Tools
Agents
Some of these will be handled in this notebook and others in ensuing ones.
Generative AI (GAI) has accelerated with the advent of large language models (LLMs). Here is a nice introduction to LLMs that is not technical to get started: https://www.understandingai.org/p/large-language-models-explained-with.
LangChain is a library that wraps much of the functionality around using large language models (LLMs) into simple commands that make using LLMs very easy and efficient. The documentation is shown below, along with some useful links.
Docs: https://python.langchain.com/docs/introduction/; API: https://python.langchain.com/api_reference/
https://www.mikulskibartosz.name/ai-data-analyst-bot-for-slack-with-gpt-and-langchain/
James Briggs:
LangChain 101: https://www.youtube.com/results?search_query=langchain+101
PineCone’s LangChain Manual: https://www.pinecone.io/learn/langchain/
The LangChain library helps with calling LLM APIs, prompt construction, chaining prompts, using search in real time as part of its tools and agents that handle specific types of tasks such as reasoning about how they construct the response.
Alternate libraries similar to LangChain:
LlamaIndex: jerryjliu/llama_index
AutoChain: Forethought-Technologies/AutoChain
Below, we install the library for LangChain and also from other providers such as OpenAI (to call gpt-3.5 and da-vinci-003 models). We also install Hugging Face’s hub to enable their APIs, and Wolfram Alpha’s library to use their APIs. The FAISS library from Meta helps with construction of and retrieval from vector databases that store embeddings from the text of documents used with the LLM. We will also use the ChromaDB vector database for applications and learn how this is used.
from google.colab import drive
drive.mount('/content/drive') # Add My Drive/<>
import os
os.chdir('drive/My Drive')
os.chdir('Books_Writings/NLPBook/')
Mounted at /content/drive
%%capture
%pylab inline
import pandas as pd
import os
from IPython.display import Image
Image('NLP_images/human.png', width=800)

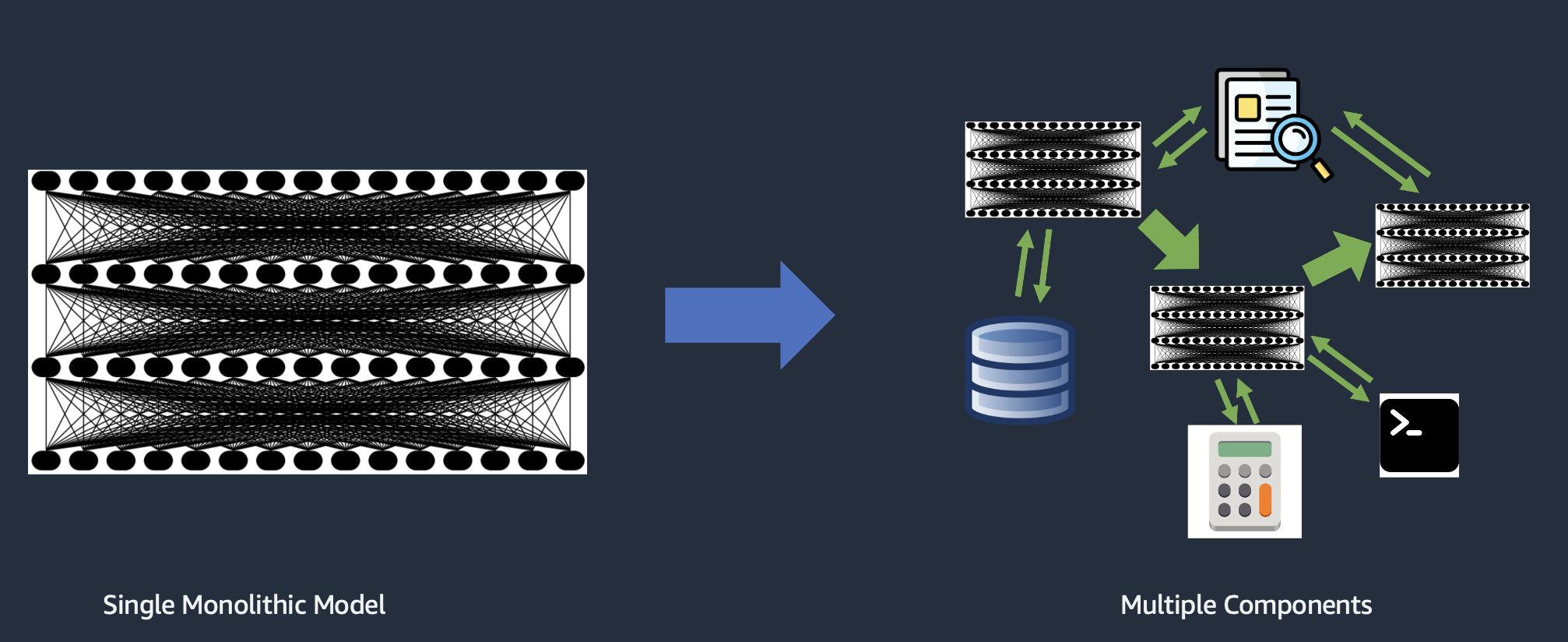
36.1. Compound AI Systems#
https://bair.berkeley.edu/blog/2024/02/18/compound-ai-systems/
Image('NLP_images/compound_ai.png', width=800)
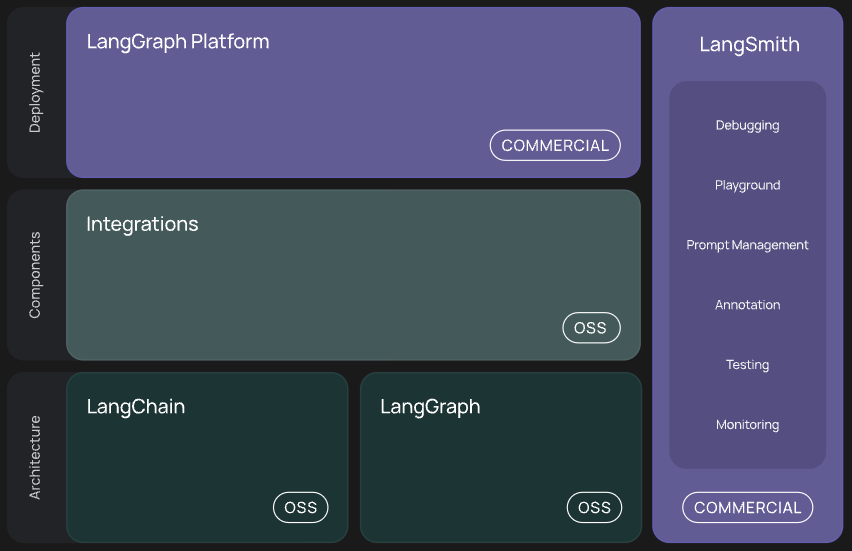
Image('NLP_images/langchain_stack.png', width=800)
Image('NLP_images/langchain_components.png', width=800)
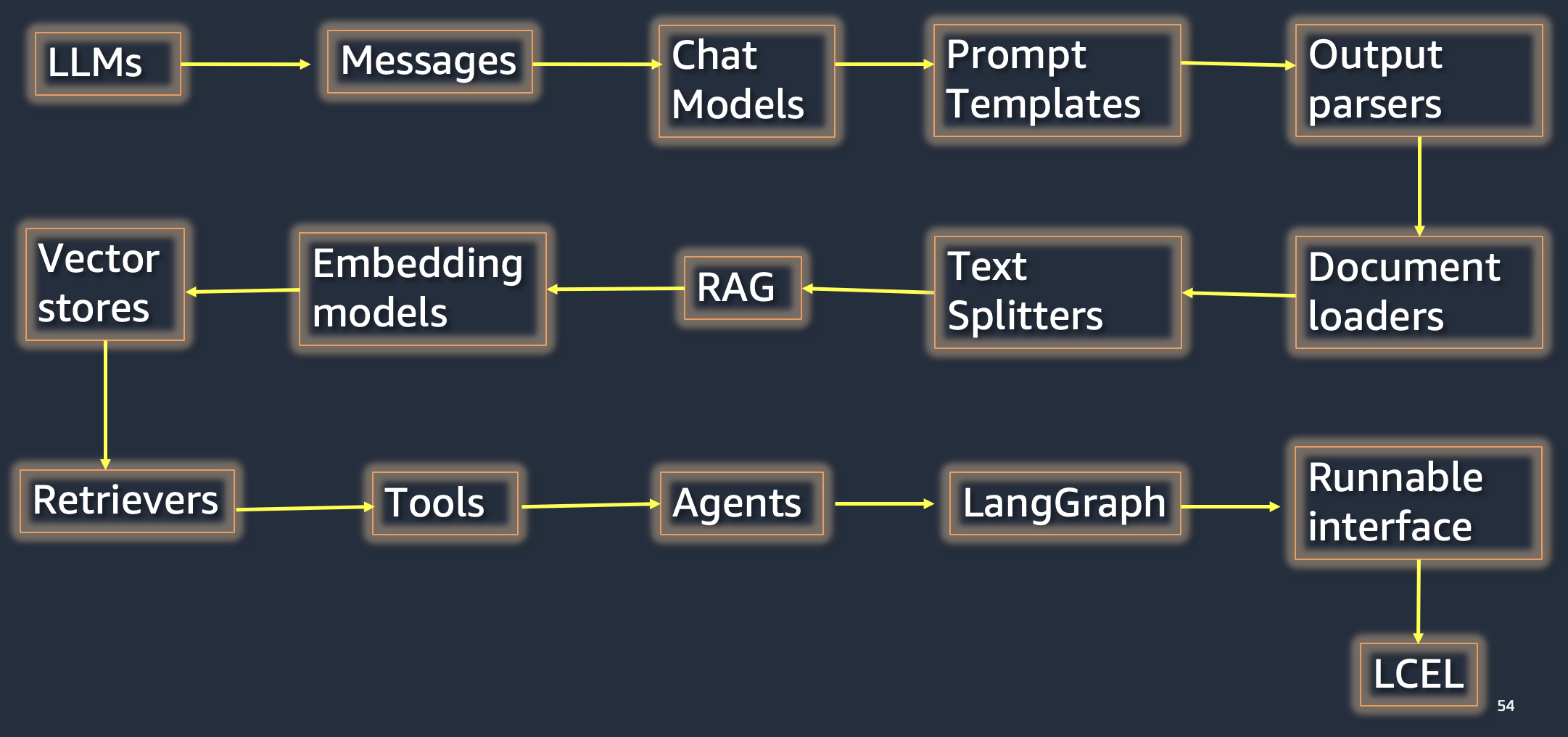
36.2. What does LangChain provide?#
Standardized component interfaces: Unifies the APIs offered by models and related components, making it easy to switch providers.
Orchestration provides an efficient framework for combining multiple components and models to accomplish diverse tasks.
Obersvability and evaluation helps developers monitor their applications and provide insights into what is happening in them.
36.3. Building things in finance#
Personalized Financial Advisor: AI-powered chatbot providing tailored financial advice based on individual circumstances and goals.
Market Sentiment Analysis: System analyzing financial news and social media to gauge market sentiment and predict trends.
Automated Financial Report Generation: Tool that automatically creates detailed financial reports from raw data for easy comprehension.
Risk Assessment Tool: Application assessing financial instrument risks by analyzing historical data and market trends.
Fraud Detection System: AI-driven system analyzing transaction data to identify potentially fraudulent activities.
36.4. Install all the packages for GAI#
We use the requirements_gai.txt file for this. The packages are:
matplotlib
numpy
ipypublish
openai
langchain-openai
chromadb
langchain
langchain_community
tiktoken
unstructured
langchain_huggingface
huggingface_hub
wolframalpha
faiss-cpu
google-search-results
python-magic
nest_asyncio
%%time
# Installs
!pip install --upgrade pip --quiet
!pip install -r requirements_gai.txt --quiet
?25l ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/1.8 MB ? eta -:--:--
━━━━━╸━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.3/1.8 MB 8.0 MB/s eta 0:00:01
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸ 1.8/1.8 MB 27.4 MB/s eta 0:00:01
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.8/1.8 MB 21.6 MB/s eta 0:00:00
?25h Installing build dependencies ... ?25l?25hdone
Getting requirements to build wheel ... ?25l?25hdone
Preparing metadata (pyproject.toml) ... ?25l?25hdone
Installing build dependencies ... ?25l?25hdone
Getting requirements to build wheel ... ?25l?25hdone
Preparing metadata (pyproject.toml) ... ?25l?25hdone
Installing build dependencies ... ?25l?25hdone
Getting requirements to build wheel ... ?25l?25hdone
Preparing metadata (pyproject.toml) ... ?25l?25hdone
Installing build dependencies ... ?25l?25hdone
Getting requirements to build wheel ... ?25l?25hdone
Preparing metadata (pyproject.toml) ... ?25l?25hdone
Building wheel for google-search-results (pyproject.toml) ... ?25l?25hdone
Building wheel for pypika (pyproject.toml) ... ?25l?25hdone
Building wheel for bibtexparser (pyproject.toml) ... ?25l?25hdone
Building wheel for langdetect (pyproject.toml) ... ?25l?25hdone
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
google-colab 1.0.0 requires requests==2.32.4, but you have requests 2.32.5 which is incompatible.
opentelemetry-exporter-otlp-proto-http 1.37.0 requires opentelemetry-exporter-otlp-proto-common==1.37.0, but you have opentelemetry-exporter-otlp-proto-common 1.38.0 which is incompatible.
opentelemetry-exporter-otlp-proto-http 1.37.0 requires opentelemetry-proto==1.37.0, but you have opentelemetry-proto 1.38.0 which is incompatible.
opentelemetry-exporter-otlp-proto-http 1.37.0 requires opentelemetry-sdk~=1.37.0, but you have opentelemetry-sdk 1.38.0 which is incompatible.
google-adk 1.17.0 requires opentelemetry-api<=1.37.0,>=1.37.0, but you have opentelemetry-api 1.38.0 which is incompatible.
google-adk 1.17.0 requires opentelemetry-sdk<=1.37.0,>=1.37.0, but you have opentelemetry-sdk 1.38.0 which is incompatible.
CPU times: user 3.77 s, sys: 486 ms, total: 4.26 s
Wall time: 1min 3s
%pylab inline
import os
import textwrap
import openai
import wolframalpha
import faiss
def p80(text):
print(textwrap.fill(text, 80))
return None
Populating the interactive namespace from numpy and matplotlib
36.5. Load in API Keys#
Many of the services used in this notebook require API keys and they charge fees, after you use up the free tier. We store the keys in a separate notebook so as to not reveal them here. Then by running that notebook all the keys are added to the environment.
Set up your own notebook with the API keys and it should look as follows:
import os
OPENAI_KEY = '<Your API Key here>'
os.environ['OPENAI_API_KEY'] = OPENAI_KEY
HF_API_KEY = '<Your API Key here>'
os.environ['HUGGINGFACEHUB_API_TOKEN'] = HF_API_KEY
SERPAPI_KEY = '<Your API Key here>'
os.environ['SERPAPI_API_KEY'] = SERPAPI_KEY
WOLFRAM_ALPHA_KEY = '<Your API Key here>'
os.environ['WOLFRAM_ALPHA_APPID'] = WOLFRAM_ALPHA_KEY
GOOGLE_KEY = '<Your API Key here>'
keys = ['OPENAI_KEY', 'HF_API_KEY', 'SERPAPI_KEY', 'WOLFRAM_ALPHA_KEY']
print("Keys available: ", keys)
%run keys.ipynb
36.6. Using LLMs: Hugging Face#
See: https://huggingface.co/docs/transformers/model_doc/flan-t5
The code below shows how to use the FLAN-T5 model with langchain.
The temperature parameter (ranging from 0 to 1) determines how much variation there will be in the responses from the LLM. This is based on how the LLM chooses the next word in the sequence. If temperature=0 then the LLM will always choose the most likely word. But if temerature>0 then the next word is chosen from a collection of top probability words, where this collection becomes larger as this parameter increases. That’s all there is to it. Hence, higher temperate means greater variety in the text generated. (I am not sure why this nomenclature was chosen for this parameter.)
Here is a nice blog that explains how to use Hugging Face and the code below is abstracted from it: https://huggingface.co/blog/langchain
# From the link for FLAN-T5: https://huggingface.co/docs/transformers/model_doc/flan-t5
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-t5-small")
tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-small")
inputs = tokenizer("A step by step recipe to make bolognese pasta:", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
/usr/local/lib/python3.12/dist-packages/huggingface_hub/utils/_auth.py:94: UserWarning:
The secret `HF_TOKEN` does not exist in your Colab secrets.
To authenticate with the Hugging Face Hub, create a token in your settings tab (https://huggingface.co/settings/tokens), set it as secret in your Google Colab and restart your session.
You will be able to reuse this secret in all of your notebooks.
Please note that authentication is recommended but still optional to access public models or datasets.
warnings.warn(
['Pour a cup of bolognese into a large bowl and add the pasta to the bowl.']
36.7. LangChain Messages#
Messages are of different types shown below.
Contain role, content, and optional response metadata/tool calls.
Image('NLP_images/langchain_messages.png', width=800)

36.8. Chat Models#
Chat models take a sequence of messages as input and return chat messages as output.
LangChain relies on third-party integrations for chat models.
Supports standard parameters like temperature, max tokens, and stop sequences.
36.9. Prompt Templates#
Using Python f-strings, you can create templatized queries for LLMs. If you have not used f-strings before, please do review this topic as it is useful in many settings, not just for prompting.
from langchain_core.prompts import PromptTemplate
# Create a new prompt template for generating an email
email_template = """
Dear {recipient},
Subject: {topic}
I hope this email finds you well.
Regarding the topic of {topic}, I wanted to share some information with you.
[Insert main content of the email here]
Best regards,
{sender}
"""
email_prompt = PromptTemplate.from_template(email_template)
# Example usage
inputs = {
"recipient": "Dr. Smith",
"topic": "Your recent paper on AI in finance",
"sender": "Dr. Jones"
}
formatted_email = email_prompt.invoke(inputs)
print(formatted_email.text)
Dear Dr. Smith,
Subject: Your recent paper on AI in finance
I hope this email finds you well.
Regarding the topic of Your recent paper on AI in finance, I wanted to share some information with you.
[Insert main content of the email here]
Best regards,
Dr. Jones
36.10. Prompt Template from Messages#
from langchain_core.prompts import ChatPromptTemplate
# Set up Prompt Template
template = """Question: What is a {topic}
Answer: """
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant that answers questions about the world."),
("human", template)])
res = prompt.invoke({"topic": "quark"})
res
ChatPromptValue(messages=[SystemMessage(content='You are a helpful assistant that answers questions about the world.', additional_kwargs={}, response_metadata={}), HumanMessage(content='Question: What is a quark\n\nAnswer: ', additional_kwargs={}, response_metadata={})])
36.11. Use OpenAI#
Make sure to get an API Key from OpenAI.
Notice also that the method for the text model is OpenAI but for the GPT model is ChatOpenAI.
from langchain_openai import ChatOpenAI
# Chat Models
gpt41 = ChatOpenAI(model_name='gpt-4.1')
# Assuming 'gpt41' is the ChatOpenAI instance initialized in cell CoDGDOadPbnk
from langchain_openai import ChatOpenAI
gpt41 = ChatOpenAI(model_name='gpt-4.1') # This line is in cell CoDGDOadPbnk
response = gpt41.invoke("What is the capital of France?")
print(response.content)
The capital of France is **Paris**.
# Example
question = "Which country invaded Ukraine?"
res = gpt41.invoke(question)
res.content
"Russia invaded Ukraine. The invasion began in February 2022, escalating a conflict that started in 2014 with Russia's annexation of Crimea and involvement in eastern Ukraine."
Here we provide the first few segments of a “chained” conversation as the prompt and then ask for the LLM to complete the conversation.
# GPT with a completion task
import openai
import os
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
messages = [
SystemMessage(content="You are Donald Trump, the President of the United States. Answer as concisely as possible.\n"),
HumanMessage(content="How are you?"),
AIMessage(content="I am doing well"),
HumanMessage(content="What is your role?")
]
response = gpt41.invoke(messages)
print(response.content)
I’m President of the United States—making America great again, leading our country, and delivering results!
# This is simpler and without a prompt creation per se
gpt41 = ChatOpenAI(model_name='gpt-4.1', temperature=0.1)
query = "What are the different agencies of the US government?"
p80(gpt41.invoke(query).content)
The United States government is made up of numerous agencies, departments, and
offices, each with specific roles and responsibilities. Here’s an overview of
the main types and examples of US government agencies: --- ### **1. Executive
Departments (Cabinet-level)** These are the primary units of the executive
branch, each headed by a Secretary (except the Department of Justice, headed by
the Attorney General): - **Department of State (DOS)** - **Department of the
Treasury** - **Department of Defense (DOD)** - **Department of Justice (DOJ)** -
**Department of the Interior (DOI)** - **Department of Agriculture (USDA)** -
**Department of Commerce** - **Department of Labor** - **Department of Health
and Human Services (HHS)** - **Department of Housing and Urban Development
(HUD)** - **Department of Transportation (DOT)** - **Department of Energy
(DOE)** - **Department of Education (ED)** - **Department of Veterans Affairs
(VA)** - **Department of Homeland Security (DHS)** --- ### **2. Independent
Agencies** These agencies exist outside the federal executive departments and
have specific mandates: - **Central Intelligence Agency (CIA)** -
**Environmental Protection Agency (EPA)** - **National Aeronautics and Space
Administration (NASA)** - **National Science Foundation (NSF)** - **Small
Business Administration (SBA)** - **Social Security Administration (SSA)** -
**Federal Communications Commission (FCC)** - **Federal Trade Commission (FTC)**
- **Securities and Exchange Commission (SEC)** - **Federal Reserve System (The
Fed)** - **National Labor Relations Board (NLRB)** - **General Services
Administration (GSA)** - **Office of Personnel Management (OPM)** - **United
States Agency for International Development (USAID)** --- ### **3. Regulatory
Commissions** These are independent agencies created by Congress to regulate
specific aspects of the economy or society: - **Federal Communications
Commission (FCC)** - **Federal Election Commission (FEC)** - **Federal Energy
Regulatory Commission (FERC)** - **Federal Trade Commission (FTC)** -
**Securities and Exchange Commission (SEC)** - **Consumer Product Safety
Commission (CPSC)** - **Nuclear Regulatory Commission (NRC)** - **Commodity
Futures Trading Commission (CFTC)** - **Equal Employment Opportunity Commission
(EEOC)** --- ### **4. Government Corporations** These are government-owned
businesses that provide commercial services: - **United States Postal Service
(USPS)** - **Amtrak (National Railroad Passenger Corporation)** - **Tennessee
Valley Authority (TVA)** - **Federal Deposit Insurance Corporation (FDIC)** -
**Export-Import Bank of the United States** --- ### **5. Other Notable
Agencies and Offices** - **Office of the Director of National Intelligence
(ODNI)** - **Office of Management and Budget (OMB)** - **Office of the United
States Trade Representative (USTR)** - **Council of Economic Advisers (CEA)** -
**National Security Council (NSC)** - **United States Secret Service (USSS)** -
**Federal Bureau of Investigation (FBI)** - **Drug Enforcement Administration
(DEA)** - **Bureau of Alcohol, Tobacco, Firearms and Explosives (ATF)** -
**Internal Revenue Service (IRS)** --- ### **6. Legislative and Judicial
Branch Agencies** - **Library of Congress** - **Congressional Budget Office
(CBO)** - **Government Accountability Office (GAO)** - **Administrative Office
of the U.S. Courts** - **United States Sentencing Commission** --- **Note:**
There are hundreds of federal agencies, sub-agencies, and offices. The above
list covers the most prominent and widely known. For a comprehensive list, you
can visit the [USA.gov A-Z Index of U.S. Government Departments and
Agencies](https://www.usa.gov/federal-agencies). If you need information about
a specific agency or type of agency, let me know!
36.12. Adding Context#
Here, we do not just query the language model but instead also add local context for it to look at.
We see how beautiful the abstraction of prompt templates is.
You can do this without even setting up the chain, because the HF model can also take in local context.
# Example 1
# Prompt Template with Context
prompt = """
Answer the question based on the context provided below. If the question cannot be answered, say 'That was a dumb question.'
Context: A self-driving car (sometimes called an autonomous car or driverless car) is a vehicle that uses a combination of sensors, cameras, radar and artificial intelligence (AI) to travel between destinations without a human operator. To qualify as fully autonomous, a vehicle must be able to navigate without human intervention to a predetermined destination over roads that have not been adapted for its use.
Question: What is the role of humans with self-driving cars?
Answer:
"""
print(textwrap.fill(prompt, width=80))
Answer the question based on the context provided below. If the question cannot
be answered, say 'That was a dumb question.' Context: A self-driving car
(sometimes called an autonomous car or driverless car) is a vehicle that uses a
combination of sensors, cameras, radar and artificial intelligence (AI) to
travel between destinations without a human operator. To qualify as fully
autonomous, a vehicle must be able to navigate without human intervention to a
predetermined destination over roads that have not been adapted for its use.
Question: What is the role of humans with self-driving cars? Answer:
p80(gpt41.invoke(prompt).content)
Based on the context provided, the role of humans with self-driving cars is to
set a predetermined destination, but the vehicle navigates to that destination
without human intervention. Humans are not required to operate or directly
control fully autonomous vehicles during travel.
36.13. Combine LLM with Google Searches#
In order to make sure that the responses from the LLM are based on up to date information, we can combine queries with context from a web search. This is necessary because LLMs are trained on information up to the training set date and they become obsolete quite rapidly.
We use langchain agents to make the thought process of the LLM (i.e., the system prompts, as opposed to the human prompt), read more here: https://python.langchain.com/docs/modules/agents/
Agents use an LLM to determine which actions to take and in what order. An action can either be using a tool and observing its output, or returning a response to the user.
zero-shot-react-descriptionreact-docstoreself-ask-with-searchconversational-react-description
List of agents: https://python.langchain.com/docs/modules/agents/agent_types/
Tools are functions that agents can use to interact with the world. These tools can be generic utilities (e.g. search), other chains, or even other agents.
List of tools: https://python.langchain.com/docs/modules/agents/tools/
We use SerpAPI to access google on the fly: https://serpapi.com
from langchain_community.agent_toolkits.load_tools import load_tools
# from langchain_community.agent_toolkits import initialize_agent
from langchain_community.utilities import SerpAPIWrapper
from langchain.agents import create_agent
llm = ChatOpenAI(model_name='gpt-4.1', temperature=0.1)
# Make sure to have an API key for SERP
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = create_agent(
model=llm,
tools=tools,
system_prompt="You are a helpful assistant.",
)
# agent = create_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
# from langchain.agents import create_react_agent
from langchain_community.agent_toolkits.load_tools import load_tools
from langchain_openai import OpenAI # or use langchain_openai for OpenAI/Azure
from langchain_community.utilities import SerpAPIWrapper
from langchain_core.tools import Tool
from langchain_classic import hub
from dotenv import load_dotenv
load_dotenv() # Loads environment variables from a .env file (for SERPAPI_API_KEY, OPENAI_API_KEY)
# Instantiate your language model (OpenAI)
llm = OpenAI(temperature=0) # Substitute with langchain_openai.OpenAI for Azure/OpenAI v1
# Create SERP API search tool
serp_api = SerpAPIWrapper() # Assumes SERPAPI_API_KEY is set in your environment
serp_tool = Tool(
name="Search",
func=serp_api.run,
description="A tool for web search using SerpAPI"
)
# # Load additional tools if needed, e.g., math or calculator
tools = load_tools(["llm-math"], llm=llm)
tools.append(serp_tool)
from typing import TypedDict
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest
class Context(TypedDict):
user_role: str
@dynamic_prompt
def user_role_prompt(request: ModelRequest) -> str:
"""Generate system prompt based on user role."""
user_role = request.runtime.context.get("user_role", "user")
base_prompt = "You are a helpful assistant."
if user_role == "expert":
return f"{base_prompt} Provide detailed technical responses."
elif user_role == "beginner":
return f"{base_prompt} Explain concepts simply and avoid jargon."
return base_prompt
agent = create_agent(
model="gpt-4o",
tools=tools,
middleware=[user_role_prompt],
context_schema=Context
)
# The system prompt will be set dynamically based on context
result = agent.invoke(
{"messages": [{"role": "user", "content": "Explain machine learning"}]},
context={"user_role": "expert"}
)
p80(result['messages'][1].content)
Machine learning (ML) is a subset of artificial intelligence (AI) that focuses
on the development of algorithms and statistical models that enable computers to
perform tasks without explicit instructions. Instead of being programmed for
specific tasks, the machine learns from data to improve its performance over
time. Here's a detailed explanation of the key concepts and components that make
up machine learning: 1. **Types of Machine Learning:** - **Supervised
Learning:** The algorithm is trained on a labeled dataset, meaning the input
data is paired with the correct output. The goal is to learn a mapping from
inputs to outputs and make predictions on unseen data. Common tasks include
classification (e.g., spam detection) and regression (e.g., predicting house
prices). - **Unsupervised Learning:** The algorithm works with unlabeled
data. It tries to identify patterns or structures within the data. Common
methods include clustering (e.g., customer segmentation) and dimensionality
reduction (e.g., principal component analysis). - **Semi-supervised
Learning:** This combines both labeled and unlabeled data. It can be useful when
there is a limited amount of labeled data and a large amount of unlabeled data.
- **Reinforcement Learning:** The algorithm learns by interacting with an
environment and receiving feedback in terms of rewards or penalties. It is
commonly used in fields like robotics and game playing (e.g., AlphaGo). 2.
**Key Components of Machine Learning:** - **Algorithms:** These are the
mathematical constructs that learn from data. Examples include decision trees,
neural networks, support vector machines, and more. - **Model:** A model is
the result of training an algorithm on data. It's a representation of the
learned patterns or predictions that the algorithm generates. - **Training
and Testing:** Training involves feeding data into a learning algorithm to
generate a model. Testing is evaluating the model's performance using new data
that wasn't part of the training set. - **Features and Feature Engineering:**
Features are individual measurable properties or characteristics used in the
model. Feature engineering involves selecting, modifying, or creating features
to improve the model's performance. - **Overfitting and Underfitting:**
Overfitting occurs when a model learns the training data too well, including its
noise, making it perform poorly on new data. Underfitting happens when a model
is too simple to capture the underlying trend in the data. 3. **Processes in
Machine Learning:** - **Data Collection and Cleaning:** Gathering data and
preprocessing it to ensure quality, relevance, and cleanliness. - **Model
Selection:** Choosing which algorithm to use for training the model based on the
problem type, data size, and other factors. - **Training:** The actual act of
feeding data into an algorithm to find patterns. - **Evaluation:** Testing
the trained model using metrics such as accuracy, precision, recall, and F1
score to determine its performance. - **Deployment:** Integrating the machine
learning model into other systems to make real-time predictions. 4.
**Applications:** - Spam filtering, recommendation systems, image
recognition, autonomous vehicles, fraud detection, and many more. Machine
learning continues to evolve and expand, providing powerful tools and methods
for data analysis and automation, which drive advancements across various
sectors.
36.14. Using Google Gemini#
(Get an API key first and read it into the environment.)
import google.generativeai as genai
from google.colab import userdata
# Access the API key from Colab secrets
GOOGLE_API_KEY=userdata.get('GOOGLE_API_KEY') # or type in the key string here
genai.configure(api_key=GOOGLE_API_KEY)
model = genai.GenerativeModel(model_name="gemini-pro")
response = model.generate_content("Explain how AI will destroy humanity")
p80(response.candidates[0].content.parts[0].text)