
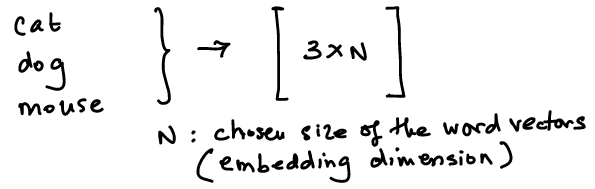
30. Embeddings#
Representing words as numerical fixed length vectors in \(n\)-dimensional space.
An excellent blog on what embeddings are: https://simonwillison.net/2023/Oct/23/embeddings/. A must read.
from google.colab import drive
drive.mount('/content/drive') # Add My Drive/<>
import os
os.chdir('drive/My Drive')
os.chdir('Books_Writings/NLPBook/')
Mounted at /content/drive
%%capture
%pylab inline
import pandas as pd
import os
from IPython.display import Image
%load_ext rpy2.ipython
30.1. Word2Vec: Word Embeddings#
In a number of Natural Language Processing (NLP) applications classic methods for language modeling that represent words as high-dimensional, sparse vectors have been replaced by Neural Language models that learn word embeddings, i.e., low-dimensional representations of words, often through the use of neural networks.
https://machinelearningmastery.com/develop-word-embeddings-python-gensim/
Google’s word2vec page: https://code.google.com/archive/p/word2vec/
Original word2vec paper: https://arxiv.org/pdf/1301.3781.pdf; and the improved skip-gram model: https://arxiv.org/pdf/1310.4546.pdf
A simple exposition: https://skymind.ai/wiki/word2vec
Word2Vec Made Easy: https://towardsdatascience.com/word2vec-made-easy-139a31a4b8ae; https://drive.google.com/file/d/1PqdcFsonU6jNu_BN7dXzcaKD-Yj56eH7/view?usp=sharing
Word embeddings have proven to be a useful way to do meta analysis and generate new findings from extant literature as shown in Tshitoyan et al (2019); pdf.
The Illustrated Word2vec by Jay Alammar (this is possibly the best blog on word2vec).
Words have multiple degrees of similarity, such as syntactic similarity and semantic similarity. Word embeddings have been found to pick up both types of similarity. These similarities have been found to support algebraic operations on words, as in the famous word2vec example where vector(“Man”) + vector(“King”) - vector(“Queen”) equals vector(“Woman”).
Semantics = the study of meaning
Syntactic = rules of writing
The output of word2vec is an input to many natural language models using deep learning, such as sentence completion, parsing, information retrieval, document classification, question answering, and named entity recognition.
30.2. What is an “embedding”?#
A light introduction: https://technicalwriting.dev/data/embeddings.html
Think of embeddings as factor analysis for words.
So if we take a large number of companies and analyze their 10K/Q filings, and want to view them in the light of fewer, simpler dimensions, then we “embed” the documents in a lower dimension space, i.e., we get “document embeddings.”
The other advantage of embeddings is that we convert words/documents of different lengths and frequencies into fixed length vectors in any dimensional space that we may choose. (There is of course art and science here.)
This is where the intuition of principal components lies, because if \(N=10\), then we are saying that 10 dimensions matter and we plot documents in that smaller space.
Image("NLP_images/w2v_basic_idea.png", width=600)
We can also compute “semantic similarity” across documents. This may be useful in finding a diversified portfolio of companies.
As we have learnt before, there are 4 common ways in which we may examine similarity:
Cosine similarity
Jaccard similarity
Minimum edit distance
Simple similarity
Let’s look at this visualization from Jay Alammar’s blog, cited above.
image_paths = ["NLP_images/w2v_king_queen.png","NLP_images/w2v_kq_similar.png"]
for path in image_paths:
display(Image(filename=path, width=600))
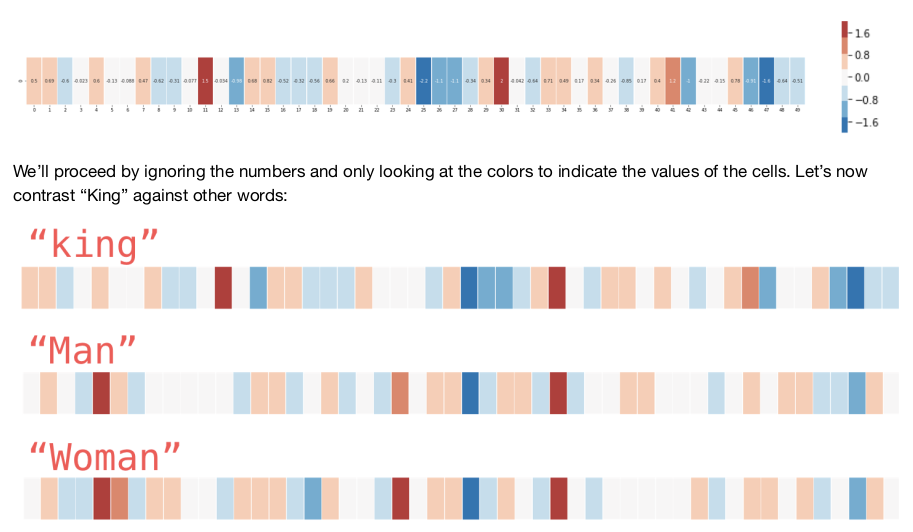
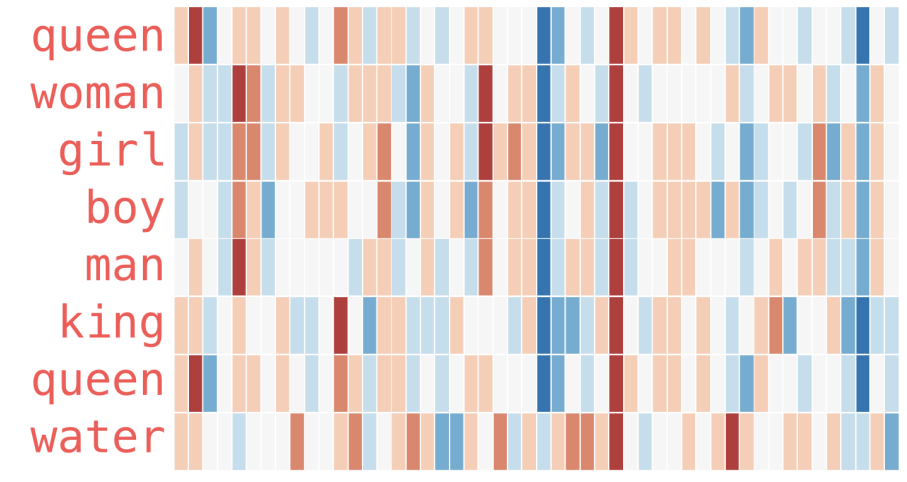
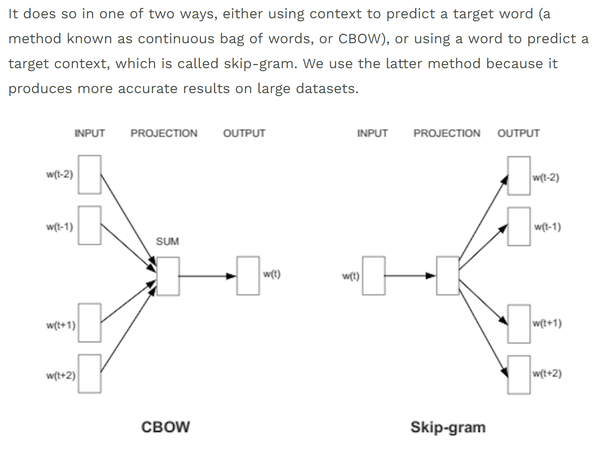
There are two approaches to word2vec, discussed below. See: https://arxiv.org/pdf/1301.3781.pdf for the original word2vec paper.
Image("NLP_images/cbow_skipgram.png",width=600)
30.3. Language Models#
A language model is a statistical representation of words in a language. This is easily seen in the context of a sentence completion task.
Image("NLP_images/w2v_LM1.png",width=600)
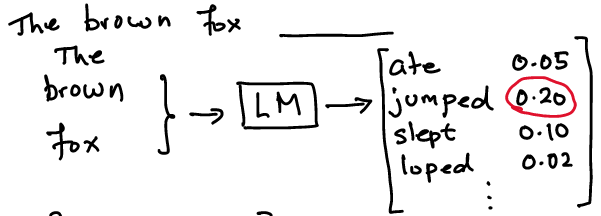
And word2vec is about using language modeling to get a vector representation of a word.
Image("NLP_images/w2v_LM2.png",width=600)
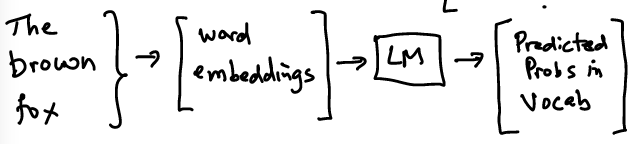
Let’s take an example sentence. We assume that the language model uses a sequence length of 2 words. This is also called the “window length”.
Image("NLP_images/w2v_example-sentence.png",width=600)
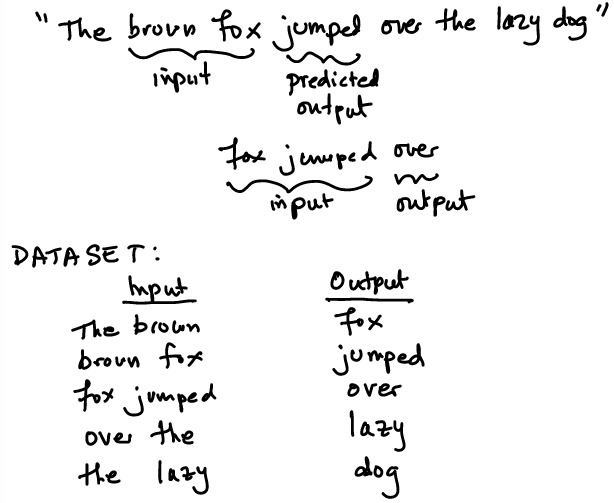
30.4. CBOW#
To get better context, we may also choose to use 2 words before and after, i.e., surrounding words. The structure would then be
“The brown fox ___________ over the …”
The CBOW dataset would be as follows.
Image("NLP_images/w2v_CBOW.png",width=600)

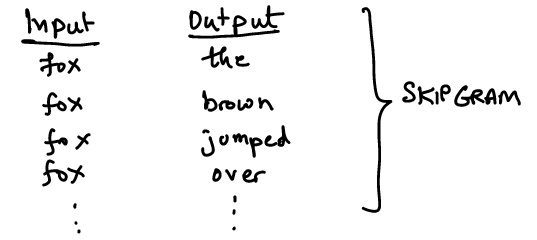
30.5. Skip-gram#
The skip-gram model re-arranged the input and output as follows.
Image("NLP_images/w2v_skipgram.png",width=600)
30.6. Train a language model#
We use this skip-gram dataset to train a model that best predicts the neighboring word.
Image("NLP_images/w2v_LM3.png",width=600)
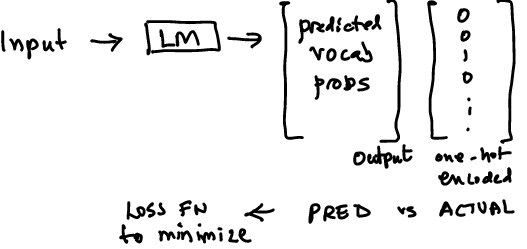
30.7. Negative Sampling#
Getting word embeddings requires a change in the structure of the dataset for skip-grams.
Instead of matching inputs to outputs, we take both inputs and outputs and generate the probability that they are neighbors using word embeddings.
Start with random embeddings and then iterate to find embeddings that match how close the word vectors are if they are neghbors or not.
We also need to employ negative sampling. This could be based on uni-grams or bi-grams. Paper: https://arxiv.org/pdf/1402.3722v1. Negative sampling reduces the computational cost.
It also makes sense to remove stopwords (sub-sampling) as they appear in the context of all words, and this also reduces the size of the vocab making computation faster.
Image("NLP_images/w2v_negative_sampling.png",width=600)
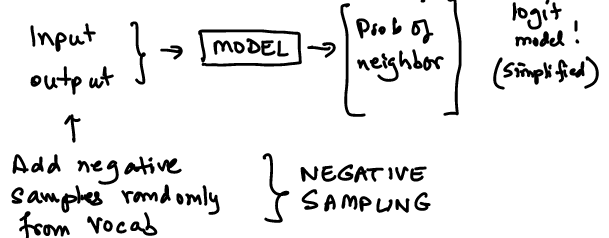
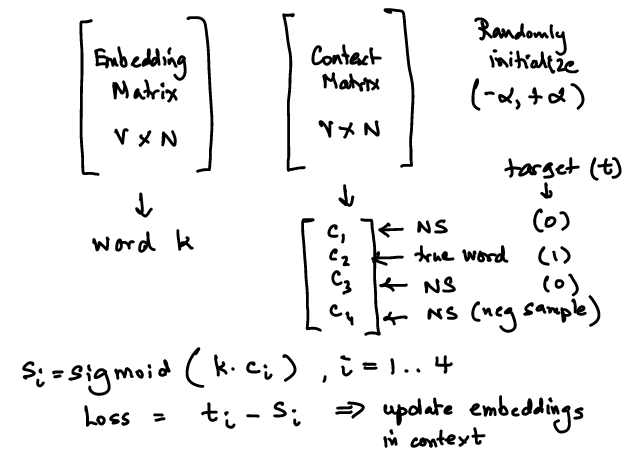
30.8. Pre-training Word Embeddings#
Randomly initialize “embeddings” matrix.
Make a copy, the “context” matrix.
Get the input embeddings from the embeddings matrix and the output embeddings from the context matrix.
For each word in the embedding matrix and its corresponding sample (true and false neighbors), compute sigmoid similarity.
Compare to the one-hot encoded target to get the loss function values and iteratively adjust embeddings in the context to get the new embeddings set.
Update embeddings matrix and context matrix, rinse, repeat.
Image("NLP_images/w2v_pretrain.png",width=600)
As you might imagine, you have to make choices about
Window size (\(c\))
Embedding dimension (\(N\))
A simple blog that gives a visual feel:
http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
http://mccormickml.com/2017/01/11/word2vec-tutorial-part-2-negative-sampling/
You can download word vectors for many languages from https://fasttext.cc/docs/en/crawl-vectors.html
30.9. Which Layer to Use?#
An interesting paper https://arxiv.org/abs/2502.02013 proposes a unified framework of representation quality metrics based on information theory, geometry, and invariance to input perturbations. Key metrics include prompt entropy, dataset entropy, curvature, and augmentation invariance measures. The paper challenges the conventional wisdom that final layers of language models provide the best representations for downstream tasks. It finds that intermediate layers often outperform final layers when viewed through the lens of various metrics.
30.10. Skip-gram math#
Given a sequence of words \(w_1,...,w_T\) (i.e., \(T\) terms), the quantity of interest in the skip-gram model is the conditional probability:
Here \(c\) is a window around the current word \(w_t\) in the text, and \(c\) may also be a function of \(w_t\). This is what is depicted in the graphic above. The objective function is to maximize the log conditional probability:
Assume a vocabulary of \(W\) words. Let each word \(w\) be represented by a word vector \(v(w)\) of dimension \(N\). Then the skip-gram model assumes that the conditional probabilities come from a softmax function as follows:
It requires gradients for each element of the vectors \(v(w)\), which is onerous and is of order \(O(W)\). Instead of softmax, hierarchical softmax is used, which is of order \(O(log W)\). An alternative is negative sampling, specifically Noise Contrastive Estimation (NCE) as this approximates softmax with logistic functions. Explanation of these approximations and speedups is beyond the scope of these notes, but the reader is referred to Mikolov et al (2013), or see this simpler exposition.
Training is done with neural nets containing a single hidden layer of dimension \(N\). The input and output layers are of the same size, and this is your essential autoencoder.
30.11. Heirarchical Softmax#
Hierarchical softmax is an alternative to the standard softmax function used in neural networks, particularly in natural language processing tasks. It is designed to improve computational efficiency when dealing with large vocabularies or output spaces.
30.12. Key Features#
Tree Structure: Hierarchical softmax organizes the output vocabulary into a binary tree structure, with words as leaf nodes.
Logarithmic Complexity: It reduces the computational complexity from O(n) to O(log n), where n is the size of the vocabulary.
Path-based Probability: The probability of a word is calculated as the product of probabilities along the path from the root to the leaf node representing that word.
30.13. How It Works#
Tree Construction: The vocabulary is arranged in a hierarchical binary tree.
Node Representations: Each non-leaf node in the tree has a vector representation.
Probability Calculation: To compute the probability of a word, the model traverses the tree from root to leaf, making binary decisions at each node.
Training: During training, only the parameters along the path of the target word are updated, significantly reducing the number of computations.
30.14. Advantages#
Faster Training: Reduces the number of parameters that need to be updated in each training step.
Efficient Evaluation: Allows for faster calculation of individual word probabilities during inference.
Scalability: Particularly beneficial for tasks with large vocabularies, such as language modeling.
30.15. Considerations#
Tree Structure: The efficiency and performance can be affected by how the tree is constructed. Optimal word assignment in the tree is crucial.
Balanced vs. Huffman Tree: While balanced trees ensure all words are at the same level, some implementations use Huffman coding to create shorter paths for more frequent words.
Complexity Trade-off: While it reduces computational complexity, it introduces additional complexity in the model architecture.
Hierarchical softmax offers a significant speedup in training and evaluation of models with large output spaces, making it a valuable technique in natural language processing and other domains with extensive categorical outputs.
References: [1] https://www.reddit.com/r/MachineLearning/comments/338sqx/hierarchical_softmax_why_is_it_faster/ [2] https://building-babylon.net/2017/08/01/hierarchical-softmax/ [3] https://paperswithcode.com/method/hierarchical-softmax
30.16. GloVe (Global Vectors)#
A matrix factorization representation of word2vec from Stanford is called GloVe. This is unsupervised learning. I highly recommend reading the web page, it is one of the most beautiful and succint presentations of an algorithmic idea I have encountered.
This is not the first matrix factorization idea, Latent Semantic Analysis (LSA) has been around for some time. LSA factorizes a term-document matrix into lower dimension. But it has its drawbacks and does poorly on word analogy tasks, for which word2vec does much better. GloVe is an approach that marries the ideas in LSA and word2vec in a computationally efficient manner.
As usual, the output from a word embedding model is an embedding matrix \(E\) of size \(V × N\), where \(V\) is the size of the vocabulary (number of words) and \(N\) is the dimension of the embedding.
GloVe is based on the co-occurrence matrix of words \(X\) of size \(V × V\). This matrix depends on the “window” chosen for co-occurrence. The matrix values are also scaled depending on the closeness within the window, resulting in all values in the matrix in \((0,1)\). This matrix is then factorized to get the embedding matrix \(E\). This is an extremely high-level sketch of the GloVe algorithm. See Jeffrey Pennington, Richard Socher, and Christopher D. Manning (2014); pdf.
Technically, GloVe is faster than word2vec, but requires more memory. Also, once the word co-occurrence matrix has been prepared, then \(E\) can be quickly generated for any chosen \(N\), whereas in word2vec, an entirely fresh neural net has to be estimated, because the hidden layer of the autoencoder has changed in dimension.
For large text corpora, one can intuitively imagine that word embeddings should be roughly similar if the texts are from the same domain. This suggests that pre-trained embeddings \(E\) might be a good way to go for NLP applications.
Given the word co-occurrence matrix \(X\), let \(X_i = \sum_k X_{ik}\) be the number of times various words \(k\) occur in the context of word \(i\). We can then define the conditional probability, also known as co-occurrence probabilities, the proportion of times word \(k\) occurs in the context of \(i\).
What’s the difference between a word co-occurring and a word appearing “in the context of” another word? In the context of is represented by a conditional probability, whereas co-occurence is similar to a correlation.
For a sample word \(k\), the ratio \(P_{ik}/P_{jk}\) will be large if word \(k\) occurs more in the context of \(i\) than word \(j\). If both words \(i\) and \(j\) are not related to word \(k\), then we’d expect this ratio to be close to 1. This suggests that the variable we should model is the ratio of co-occurrence probabilities rather than the probabilities themselves. Since these ratios are functions of three words, we may write $\( F(w_i,w_j,w_k) = \frac{P_{ik}}{P_{jk}} \)\( where \)w_i, w_j, w_k ∈ R^d$ are word vectors.
This function may depend on a parameter set. It is desired to have the following properties:
\(F\) should be encoded in the word vector space. It may be easier to work with the form \(F(w_i-w_j,w_k) = P_{ik}/P_{jk}\) instead.
\(F\) is a scalar function and may be approximated with a neural net (nonlinear mapping) or a simpler linear mapping, i.e., if we assume that \(F(\cdot)=\exp(\cdot)\), then \(F\) is defined as follows: $\( F((w_i-w_j)^⊤ · w_k) = \frac{F(w_i^⊤ · w_k)}{F(w_j^⊤ · w_k)} = \frac{P_{ik}}{P_{jk}} = \frac{X_{ik}/X_i}{X_{jk}/X_j} \)\( which follows from the choice of \)F$ as an exponential function.
It also follows that $\( w_i^⊤ · w_k = log(P_{ik}) = log(X_{ik}) - log(X_i) \)\( This implies that the entries in the co-occurrence matrix \)X\( are related to the word vectors \)w$, and that too, globally, hence the “GloVe” nomenclature.
The factorization is implemented using a least-squares fitting procedure (see the paper for details). Because the main element of the computations is a dot product, \(w_i^⊤ · w_k\) and there is a similar dot product in the softmax of word2vec, it is not surprising that these models are analogous.
Similar factorizations occur in recommendation engines where non-negative matrix factorization (NMF) is undertaken.
The embeddings idea may be extend to many other cases where co-occurrences exist. For example, user search histories over AirBnB in a search session may be converted into embeddings, see Grbovic and Cheng (2018); pdf.
30.17. word2vec fitting with neural nets#
We are now ready to discuss the actual fitting of the word2vec model with neural nets. The neural net is simple. As before assume that the vocabulary is of size \(V\) and the embedding is of size \(N\). To make things more concrete, let \(V=10,000\) and \(N=100\). The neural net will have \(V\) nodes in the input and output layers, and \(N\) nodes in the single hidden layer. If you are familiar with autoencoders, then this is a common NN of that type. The number of parameters (ignoring a bias term) in the NN are \(VN = 1,000,000\) for the hidden layer, and, for the output layer (with a bias term), \(NV=1,000,100\), i.e., over 2 million parameters to be fit. This is a fairly large NN.
The inputs to the model are based on a window of text around the “target” word, \(w\). Suppose the window is of size \(c=2\), then \(w\) may have up to 4 possible co-occurrence words—2 ahead (denoted \(w_1, w_2\)) and 2 before (denoted \(w_{-1},w_{-2}\)) in the window. This leads to 4 rows of input data. How? The input \(X\) in all 4 rows is a one-hot vector of \((V-1)\) zeros and a single 1 in the position indexed by \(w\). The label \(Y\) is a one-hot vector with \(V-1\) zeros and a 1 in the position where the leading or lagging word appears. Because a large corpus will have several words, each with up to \(2c\) co-occurrence words, the size of the data may also run into the millions or even billions.
The coefficient matrix for the hidden layer is of dimension \(V × N\)—that is, for every word in the vocabulary, we have a \(N\)-vector representing it. This indeed, is the entire matrix of word embeddings. Just as an autoencoder compresses the original input, in this case, the neural net projects all the words onto a \(N\)-dimensional space. We are interested here in the weights matrix of the hidden layer, not the predicted output itself.
However, fitting this NN is no easy task, with millions of parameters, and possibly, billions of observations of data. To reduce the computational load, two simple additional techniques (hacks) are applied.
Subsampling: We get rid of words that occur too frequently. So we only keep a subsample of words that occur less often. There is a formula for this. Let \(\gamma(w)\) be the percentage of word count for \(w\) among all words. This is likely to be a small number. We then sort the words based on a function of \(\gamma(w)\) and put in a cutoff, where only words with smaller \(\gamma(w)\) are retained. This eliminates common words like “the” and “this” and reduces computation time without much impact on the final word embeddings.
Negative sampling: NNs are usually fitted in batches. In each batch of data all the weights (parameters) are updated. This can be quite costly in computation. In the hidden layer, this would mean updating all \(VN=1\) million weights in the hidden layer. Instead, we only update the target word \(w\) and 5-10 words that do not co-occur with \(w\). We call these words “negatives” and hence the terminology of negative sampling. Negative words are sampled with a probability that is higher if they occur more frequently in the sample.
Both these approaches work well and have resulted in great speed up in fitting the word2vec model. pdf
30.18. Big Data: Reuters News Corpus#
https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/packages/corpora/reuters.zip
The Reuters-21578 benchmark corpus, ApteMod
id: reuters; size: 6378691; author: ; copyright: ; license: The copyright for the text of newswire articles and Reuters annotations in the Reuters-21578 collection resides with Reuters Ltd. Reuters Ltd. and Carnegie Group, Inc. have agreed to allow the free distribution of this data for research purposes only. If you publish results based on this data set, please acknowledge its use, refer to the data set by the name ‘Reuters-21578, Distribution 1.0’, and inform your readers of the current location of the data set.;
# Read in text cleaning functions
import nltk
# Remove punctuations
import string
def removePuncStr(s):
for c in string.punctuation:
s = s.replace(c," ")
return s
def removePunc(text_array):
return [removePuncStr(h) for h in text_array]
# Remove numbers
def removeNumbersStr(s):
for c in range(10):
n = str(c)
s = s.replace(n," ")
return s
def removeNumbers(text_array):
return [removeNumbersStr(h) for h in text_array]
# Stemming
nltk.download('punkt')
from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize, word_tokenize
def stemText(text_array):
stemmed_text = []
for h in text_array:
words = word_tokenize(h)
h2 = ''
for w in words:
h2 = h2 + ' ' + PorterStemmer().stem(w)
stemmed_text.append(h2)
return stemmed_text
# Remove Stopwords
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
def stopText(text_array):
stop_words = set(stopwords.words('english'))
stopped_text = []
for h in text_array:
words = word_tokenize(h)
h2 = ''
for w in words:
if w not in stop_words:
h2 = h2 + ' ' + w
stopped_text.append(h2)
return stopped_text
# Write all docs to separate files
def write2textfile(s,filename):
text_file = open(filename, "w")
text_file.write(s)
text_file.close()
[nltk_data] Downloading package punkt to /root/nltk_data...
[nltk_data] Unzipping tokenizers/punkt.zip.
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
#Read in the corpus
import nltk
nltk.download('punkt_tab')
from nltk.corpus import PlaintextCorpusReader
corpus_root = 'NLP_data/reuters/training/'
ctext = PlaintextCorpusReader(corpus_root, '.*')
[nltk_data] Downloading package punkt_tab to /root/nltk_data...
[nltk_data] Unzipping tokenizers/punkt_tab.zip.
%%time
#How many docs, paragraphs, sentences, words, characters?
print(len(ctext.fileids()))
print(len(ctext.paras()))
print(len(ctext.sents()))
print(len(ctext.words()))
print(len(ctext.raw()))
7769
8471
40277
1253696
6478471
CPU times: user 17.3 s, sys: 8.39 s, total: 25.7 s
Wall time: 1h 36min 52s
#Convert corpus to text array with a full string for each doc
def merge_arrays(word_lists):
wordlist = []
for wl in word_lists:
wordlist = wordlist + wl
doc = ' '.join(wordlist)
return doc
#Run this through the corpus to get a word array for each doc
text_array = []
for p in ctext.paras():
doc = merge_arrays(p)
text_array.append(doc)
#Show the array sample
print(len(text_array))
for j in range(5):
print(text_array[j])
8471
BAHIA COCOA REVIEW Showers continued throughout the week in the Bahia cocoa zone , alleviating the drought since early January and improving prospects for the coming temporao , although normal humidity levels have not been restored , Comissaria Smith said in its weekly review . The dry period means the temporao will be late this year . Arrivals for the week ended February 22 were 155 , 221 bags of 60 kilos making a cumulative total for the season of 5 . 93 mln against 5 . 81 at the same stage last year . Again it seems that cocoa delivered earlier on consignment was included in the arrivals figures . Comissaria Smith said there is still some doubt as to how much old crop cocoa is still available as harvesting has practically come to an end . With total Bahia crop estimates around 6 . 4 mln bags and sales standing at almost 6 . 2 mln there are a few hundred thousand bags still in the hands of farmers , middlemen , exporters and processors . There are doubts as to how much of this cocoa would be fit for export as shippers are now experiencing dificulties in obtaining + Bahia superior + certificates . In view of the lower quality over recent weeks farmers have sold a good part of their cocoa held on consignment . Comissaria Smith said spot bean prices rose to 340 to 350 cruzados per arroba of 15 kilos . Bean shippers were reluctant to offer nearby shipment and only limited sales were booked for March shipment at 1 , 750 to 1 , 780 dlrs per tonne to ports to be named . New crop sales were also light and all to open ports with June / July going at 1 , 850 and 1 , 880 dlrs and at 35 and 45 dlrs under New York july , Aug / Sept at 1 , 870 , 1 , 875 and 1 , 880 dlrs per tonne FOB . Routine sales of butter were made . March / April sold at 4 , 340 , 4 , 345 and 4 , 350 dlrs . April / May butter went at 2 . 27 times New York May , June / July at 4 , 400 and 4 , 415 dlrs , Aug / Sept at 4 , 351 to 4 , 450 dlrs and at 2 . 27 and 2 . 28 times New York Sept and Oct / Dec at 4 , 480 dlrs and 2 . 27 times New York Dec , Comissaria Smith said . Destinations were the U . S ., Covertible currency areas , Uruguay and open ports . Cake sales were registered at 785 to 995 dlrs for March / April , 785 dlrs for May , 753 dlrs for Aug and 0 . 39 times New York Dec for Oct / Dec . Buyers were the U . S ., Argentina , Uruguay and convertible currency areas . Liquor sales were limited with March / April selling at 2 , 325 and 2 , 380 dlrs , June / July at 2 , 375 dlrs and at 1 . 25 times New York July , Aug / Sept at 2 , 400 dlrs and at 1 . 25 times New York Sept and Oct / Dec at 1 . 25 times New York Dec , Comissaria Smith said . Total Bahia sales are currently estimated at 6 . 13 mln bags against the 1986 / 87 crop and 1 . 06 mln bags against the 1987 / 88 crop . Final figures for the period to February 28 are expected to be published by the Brazilian Cocoa Trade Commission after carnival which ends midday on February 27 .
COMPUTER TERMINAL SYSTEMS & lt ; CPML > COMPLETES SALE Computer Terminal Systems Inc said it has completed the sale of 200 , 000 shares of its common stock , and warrants to acquire an additional one mln shares , to & lt ; Sedio N . V .> of Lugano , Switzerland for 50 , 000 dlrs . The company said the warrants are exercisable for five years at a purchase price of . 125 dlrs per share . Computer Terminal said Sedio also has the right to buy additional shares and increase its total holdings up to 40 pct of the Computer Terminal ' s outstanding common stock under certain circumstances involving change of control at the company . The company said if the conditions occur the warrants would be exercisable at a price equal to 75 pct of its common stock ' s market price at the time , not to exceed 1 . 50 dlrs per share . Computer Terminal also said it sold the technolgy rights to its Dot Matrix impact technology , including any future improvements , to & lt ; Woodco Inc > of Houston , Tex . for 200 , 000 dlrs . But , it said it would continue to be the exclusive worldwide licensee of the technology for Woodco . The company said the moves were part of its reorganization plan and would help pay current operation costs and ensure product delivery . Computer Terminal makes computer generated labels , forms , tags and ticket printers and terminals .
N . Z . TRADING BANK DEPOSIT GROWTH RISES SLIGHTLY New Zealand ' s trading bank seasonally adjusted deposit growth rose 2 . 6 pct in January compared with a rise of 9 . 4 pct in December , the Reserve Bank said . Year - on - year total deposits rose 30 . 6 pct compared with a 26 . 3 pct increase in the December year and 34 . 5 pct rise a year ago period , it said in its weekly statistical release . Total deposits rose to 17 . 18 billion N . Z . Dlrs in January compared with 16 . 74 billion in December and 13 . 16 billion in January 1986 .
NATIONAL AMUSEMENTS AGAIN UPS VIACOM & lt ; VIA > BID Viacom International Inc said & lt ; National Amusements Inc > has again raised the value of its offer for Viacom ' s publicly held stock . The company said the special committee of its board plans to meet later today to consider this offer and the one submitted March one by & lt ; MCV Holdings Inc >. A spokeswoman was unable to say if the committee met as planned yesterday . Viacom said National Amusements ' Arsenal Holdings Inc subsidiary has raised the amount of cash it is offering for each Viacom share by 75 cts to 42 . 75 dlrs while the value of the fraction of a share of exchangeable Arsenal Holdings preferred to be included was raised 25 cts to 7 . 75 dlrs . National Amusements already owns 19 . 6 pct of Viacom ' s stock .
ROGERS & lt ; ROG > SEES 1ST QTR NET UP SIGNIFICANTLY Rogers Corp said first quarter earnings will be up significantly from earnings of 114 , 000 dlrs or four cts share for the same quarter last year . The company said it expects revenues for the first quarter to be " somewhat higher " than revenues of 32 . 9 mln dlrs posted for the year - ago quarter . Rogers said it reached an agreement for the sale of its molded switch circuit product line to a major supplier . The sale , terms of which were not disclosed , will be completed early in the second quarter , Rogers said .
#Clean up the docs using the previous functions
news = text_array
news = removePunc(news)
news = removeNumbers(news)
news = stopText(news)
#news = stemText(news)
news = [j.lower() for j in news]
news[:10]
[' bahia cocoa review showers continued throughout week bahia cocoa zone alleviating drought since early january improving prospects coming temporao although normal humidity levels restored comissaria smith said weekly review the dry period means temporao late year arrivals week ended february bags kilos making cumulative total season mln stage last year again seems cocoa delivered earlier consignment included arrivals figures comissaria smith said still doubt much old crop cocoa still available harvesting practically come end with total bahia crop estimates around mln bags sales standing almost mln hundred thousand bags still hands farmers middlemen exporters processors there doubts much cocoa would fit export shippers experiencing dificulties obtaining bahia superior certificates in view lower quality recent weeks farmers sold good part cocoa held consignment comissaria smith said spot bean prices rose cruzados per arroba kilos bean shippers reluctant offer nearby shipment limited sales booked march shipment dlrs per tonne ports named new crop sales also light open ports june july going dlrs dlrs new york july aug sept dlrs per tonne fob routine sales butter made march april sold dlrs april may butter went times new york may june july dlrs aug sept dlrs times new york sept oct dec dlrs times new york dec comissaria smith said destinations u s covertible currency areas uruguay open ports cake sales registered dlrs march april dlrs may dlrs aug times new york dec oct dec buyers u s argentina uruguay convertible currency areas liquor sales limited march april selling dlrs june july dlrs times new york july aug sept dlrs times new york sept oct dec times new york dec comissaria smith said total bahia sales currently estimated mln bags crop mln bags crop final figures period february expected published brazilian cocoa trade commission carnival ends midday february',
' computer terminal systems lt cpml completes sale computer terminal systems inc said completed sale shares common stock warrants acquire additional one mln shares lt sedio n v lugano switzerland dlrs the company said warrants exercisable five years purchase price dlrs per share computer terminal said sedio also right buy additional shares increase total holdings pct computer terminal outstanding common stock certain circumstances involving change control company the company said conditions occur warrants would exercisable price equal pct common stock market price time exceed dlrs per share computer terminal also said sold technolgy rights dot matrix impact technology including future improvements lt woodco inc houston tex dlrs but said would continue exclusive worldwide licensee technology woodco the company said moves part reorganization plan would help pay current operation costs ensure product delivery computer terminal makes computer generated labels forms tags ticket printers terminals',
' n z trading bank deposit growth rises slightly new zealand trading bank seasonally adjusted deposit growth rose pct january compared rise pct december reserve bank said year year total deposits rose pct compared pct increase december year pct rise year ago period said weekly statistical release total deposits rose billion n z dlrs january compared billion december billion january',
' national amusements again ups viacom lt via bid viacom international inc said lt national amusements inc raised value offer viacom publicly held stock the company said special committee board plans meet later today consider offer one submitted march one lt mcv holdings inc a spokeswoman unable say committee met planned yesterday viacom said national amusements arsenal holdings inc subsidiary raised amount cash offering viacom share cts dlrs value fraction share exchangeable arsenal holdings preferred included raised cts dlrs national amusements already owns pct viacom stock',
' rogers lt rog sees st qtr net up significantly rogers corp said first quarter earnings significantly earnings dlrs four cts share quarter last year the company said expects revenues first quarter somewhat higher revenues mln dlrs posted year ago quarter rogers said reached agreement sale molded switch circuit product line major supplier the sale terms disclosed completed early second quarter rogers said',
' island telephone share split approved lt island telephone co ltd said previously announced two one common share split approved shareholders annual meeting',
' u k growing impatient with japan thatcher prime minister margaret thatcher said u k was growing impatient japanese trade barriers warned would soon new powers countries offering reciprocal access markets she told parliament bid u k cable wireless plc lt cawl l enter japanese telecommunications market regarded government test case i wrote prime minister japan mr nakasone fourth march express interest cable wireless bid i yet reply we see test open japanese market really thatcher said thatcher told parliament shortly we shall powers example powers financial services act banking act become available shall able take action cases countries offer full access financial services cable wireless seeking stake proposed japanese telecommunications rival kokusai denshin denwa but japanese minister post telecommunications reported saying opposed cable wireless managerial role new company',
' questech inc lt qtec year net shr loss nil vs profit cts net loss vs profit revs mln vs mln year shr profit cts vs profit cts net profit vs profit revs mln vs mln note current year net includes charge discontinued operations dlrs',
' canada oil exports rise pct in canadian oil exports rose pct previous year mln cubic meters oil imports soared pct mln cubic meters statistics canada said production meanwhile unchanged previous year mln cubic feet natural gas exports plunged pct billion cubic meters canadian sales slipped pct billion cubic meters the federal agency said december oil production fell pct mln cubic meters exports rose pct mln cubic meters imports rose pct mln cubic meters natural gas exports fell pct month billion cubic meters canadian sales eased pct billion cubic meters',
' coffee sugar and cocoa exchange names chairman the new york coffee sugar cocoa exchange csce elected former first vice chairman gerald clancy two year term chairman board managers replacing previous chairman howard katz katz chairman since remain board member clancy currently serves exchange board managers chairman appeals executive pension political action committees the csce also elected charles nastro executive vice president shearson lehman bros first vice chairman anthony maccia vice president woodhouse drake carey named second vice chairman clifford evans president demico futures elected treasurer']
#Make it into a TFIDF matrix
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer()
tfs = tfidf.fit_transform(text_array)
tdm_mat = tfs.toarray().T
print(tdm_mat.shape)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipython-input-214162949.py in <cell line: 0>()
2 from sklearn.feature_extraction.text import TfidfVectorizer
3 tfidf = TfidfVectorizer()
----> 4 tfs = tfidf.fit_transform(text_array)
5 tdm_mat = tfs.toarray().T
6 print(tdm_mat.shape)
NameError: name 'text_array' is not defined
#Create plain TDM
from sklearn.feature_extraction.text import CountVectorizer
docs = news
vec = CountVectorizer()
X = vec.fit_transform(docs)
df = pd.DataFrame(X.toarray(), columns=vec.get_feature_names_out())
tdm = df.T
tdm.shape
(24670, 8471)
x1 = randint(tdm.shape[0]+1)
y1 = randint(tdm.shape[1]+1)
tdm.iloc[x1:x1+20,y1:y1+20]
| 3077 | 3078 | 3079 | 3080 | 3081 | 3082 | 3083 | 3084 | 3085 | 3086 | 3087 | 3088 | 3089 | 3090 | 3091 | 3092 | 3093 | 3094 | 3095 | 3096 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| durian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| during | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| duriron | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| durkin | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| duro | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| durum | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| dusseldorf | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| dust | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| dutch | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| duth | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| duties | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| duty | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| duvel | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| dvfa | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| dvh | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| dvl | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| dw | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| dwarfed | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| dwg | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| dwindle | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
%%capture
!pip install gensim
%%capture
import gensim, logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
print(len(news))
news[:3]
8471
[' bahia cocoa review showers continued throughout week bahia cocoa zone alleviating drought since early january improving prospects coming temporao although normal humidity levels restored comissaria smith said weekly review the dry period means temporao late year arrivals week ended february bags kilos making cumulative total season mln stage last year again seems cocoa delivered earlier consignment included arrivals figures comissaria smith said still doubt much old crop cocoa still available harvesting practically come end with total bahia crop estimates around mln bags sales standing almost mln hundred thousand bags still hands farmers middlemen exporters processors there doubts much cocoa would fit export shippers experiencing dificulties obtaining bahia superior certificates in view lower quality recent weeks farmers sold good part cocoa held consignment comissaria smith said spot bean prices rose cruzados per arroba kilos bean shippers reluctant offer nearby shipment limited sales booked march shipment dlrs per tonne ports named new crop sales also light open ports june july going dlrs dlrs new york july aug sept dlrs per tonne fob routine sales butter made march april sold dlrs april may butter went times new york may june july dlrs aug sept dlrs times new york sept oct dec dlrs times new york dec comissaria smith said destinations u s covertible currency areas uruguay open ports cake sales registered dlrs march april dlrs may dlrs aug times new york dec oct dec buyers u s argentina uruguay convertible currency areas liquor sales limited march april selling dlrs june july dlrs times new york july aug sept dlrs times new york sept oct dec times new york dec comissaria smith said total bahia sales currently estimated mln bags crop mln bags crop final figures period february expected published brazilian cocoa trade commission carnival ends midday february',
' computer terminal systems lt cpml completes sale computer terminal systems inc said completed sale shares common stock warrants acquire additional one mln shares lt sedio n v lugano switzerland dlrs the company said warrants exercisable five years purchase price dlrs per share computer terminal said sedio also right buy additional shares increase total holdings pct computer terminal outstanding common stock certain circumstances involving change control company the company said conditions occur warrants would exercisable price equal pct common stock market price time exceed dlrs per share computer terminal also said sold technolgy rights dot matrix impact technology including future improvements lt woodco inc houston tex dlrs but said would continue exclusive worldwide licensee technology woodco the company said moves part reorganization plan would help pay current operation costs ensure product delivery computer terminal makes computer generated labels forms tags ticket printers terminals',
' n z trading bank deposit growth rises slightly new zealand trading bank seasonally adjusted deposit growth rose pct january compared rise pct december reserve bank said year year total deposits rose pct compared pct increase december year pct rise year ago period said weekly statistical release total deposits rose billion n z dlrs january compared billion december billion january']
#Tokenize each document
def textTokenize(text_array):
textTokens = []
for h in text_array:
textTokens.append(h.split(' '))
return textTokens
sentences = textTokenize(news)
print(len(sentences))
print(type(sentences))
sentences[:2][:10]
8471
<class 'list'>
[['',
'bahia',
'cocoa',
'review',
'showers',
'continued',
'throughout',
'week',
'bahia',
'cocoa',
'zone',
'alleviating',
'drought',
'since',
'early',
'january',
'improving',
'prospects',
'coming',
'temporao',
'although',
'normal',
'humidity',
'levels',
'restored',
'comissaria',
'smith',
'said',
'weekly',
'review',
'the',
'dry',
'period',
'means',
'temporao',
'late',
'year',
'arrivals',
'week',
'ended',
'february',
'bags',
'kilos',
'making',
'cumulative',
'total',
'season',
'mln',
'stage',
'last',
'year',
'again',
'seems',
'cocoa',
'delivered',
'earlier',
'consignment',
'included',
'arrivals',
'figures',
'comissaria',
'smith',
'said',
'still',
'doubt',
'much',
'old',
'crop',
'cocoa',
'still',
'available',
'harvesting',
'practically',
'come',
'end',
'with',
'total',
'bahia',
'crop',
'estimates',
'around',
'mln',
'bags',
'sales',
'standing',
'almost',
'mln',
'hundred',
'thousand',
'bags',
'still',
'hands',
'farmers',
'middlemen',
'exporters',
'processors',
'there',
'doubts',
'much',
'cocoa',
'would',
'fit',
'export',
'shippers',
'experiencing',
'dificulties',
'obtaining',
'bahia',
'superior',
'certificates',
'in',
'view',
'lower',
'quality',
'recent',
'weeks',
'farmers',
'sold',
'good',
'part',
'cocoa',
'held',
'consignment',
'comissaria',
'smith',
'said',
'spot',
'bean',
'prices',
'rose',
'cruzados',
'per',
'arroba',
'kilos',
'bean',
'shippers',
'reluctant',
'offer',
'nearby',
'shipment',
'limited',
'sales',
'booked',
'march',
'shipment',
'dlrs',
'per',
'tonne',
'ports',
'named',
'new',
'crop',
'sales',
'also',
'light',
'open',
'ports',
'june',
'july',
'going',
'dlrs',
'dlrs',
'new',
'york',
'july',
'aug',
'sept',
'dlrs',
'per',
'tonne',
'fob',
'routine',
'sales',
'butter',
'made',
'march',
'april',
'sold',
'dlrs',
'april',
'may',
'butter',
'went',
'times',
'new',
'york',
'may',
'june',
'july',
'dlrs',
'aug',
'sept',
'dlrs',
'times',
'new',
'york',
'sept',
'oct',
'dec',
'dlrs',
'times',
'new',
'york',
'dec',
'comissaria',
'smith',
'said',
'destinations',
'u',
's',
'covertible',
'currency',
'areas',
'uruguay',
'open',
'ports',
'cake',
'sales',
'registered',
'dlrs',
'march',
'april',
'dlrs',
'may',
'dlrs',
'aug',
'times',
'new',
'york',
'dec',
'oct',
'dec',
'buyers',
'u',
's',
'argentina',
'uruguay',
'convertible',
'currency',
'areas',
'liquor',
'sales',
'limited',
'march',
'april',
'selling',
'dlrs',
'june',
'july',
'dlrs',
'times',
'new',
'york',
'july',
'aug',
'sept',
'dlrs',
'times',
'new',
'york',
'sept',
'oct',
'dec',
'times',
'new',
'york',
'dec',
'comissaria',
'smith',
'said',
'total',
'bahia',
'sales',
'currently',
'estimated',
'mln',
'bags',
'crop',
'mln',
'bags',
'crop',
'final',
'figures',
'period',
'february',
'expected',
'published',
'brazilian',
'cocoa',
'trade',
'commission',
'carnival',
'ends',
'midday',
'february'],
['',
'computer',
'terminal',
'systems',
'lt',
'cpml',
'completes',
'sale',
'computer',
'terminal',
'systems',
'inc',
'said',
'completed',
'sale',
'shares',
'common',
'stock',
'warrants',
'acquire',
'additional',
'one',
'mln',
'shares',
'lt',
'sedio',
'n',
'v',
'lugano',
'switzerland',
'dlrs',
'the',
'company',
'said',
'warrants',
'exercisable',
'five',
'years',
'purchase',
'price',
'dlrs',
'per',
'share',
'computer',
'terminal',
'said',
'sedio',
'also',
'right',
'buy',
'additional',
'shares',
'increase',
'total',
'holdings',
'pct',
'computer',
'terminal',
'outstanding',
'common',
'stock',
'certain',
'circumstances',
'involving',
'change',
'control',
'company',
'the',
'company',
'said',
'conditions',
'occur',
'warrants',
'would',
'exercisable',
'price',
'equal',
'pct',
'common',
'stock',
'market',
'price',
'time',
'exceed',
'dlrs',
'per',
'share',
'computer',
'terminal',
'also',
'said',
'sold',
'technolgy',
'rights',
'dot',
'matrix',
'impact',
'technology',
'including',
'future',
'improvements',
'lt',
'woodco',
'inc',
'houston',
'tex',
'dlrs',
'but',
'said',
'would',
'continue',
'exclusive',
'worldwide',
'licensee',
'technology',
'woodco',
'the',
'company',
'said',
'moves',
'part',
'reorganization',
'plan',
'would',
'help',
'pay',
'current',
'operation',
'costs',
'ensure',
'product',
'delivery',
'computer',
'terminal',
'makes',
'computer',
'generated',
'labels',
'forms',
'tags',
'ticket',
'printers',
'terminals']]
#Train the model on Word2Vec
model = gensim.models.Word2Vec(sentences, min_count=1)
type(model)
gensim.models.word2vec.Word2Vec
def __init__(sentences=None, corpus_file=None, vector_size=100, alpha=0.025, window=5, min_count=5, max_vocab_size=None, sample=0.001, seed=1, workers=3, min_alpha=0.0001, sg=0, hs=0, negative=5, ns_exponent=0.75, cbow_mean=1, hashfxn=hash, epochs=5, null_word=0, trim_rule=None, sorted_vocab=1, batch_words=MAX_WORDS_IN_BATCH, compute_loss=False, callbacks=(), comment=None, max_final_vocab=None, shrink_windows=True)
Serialize/deserialize objects from disk, by equipping them with the `save()` / `load()` methods. Warnings -------- This uses pickle internally (among other techniques), so objects must not contain unpicklable attributes such as lambda functions etc.
model.wv['crop']
array([-0.5854296 , 0.7613218 , -0.37902117, -1.6924702 , 0.3424731 ,
-2.2603936 , 0.09431274, 1.7066664 , 0.1466148 , -0.4974099 ,
1.0867946 , -0.1932554 , 0.8646314 , 0.6828747 , 0.84564346,
-0.9587895 , -0.65514874, -0.24828857, -0.34297755, 1.1059616 ,
0.09736466, -0.71722895, 1.2240978 , -0.8524739 , 0.6441148 ,
-1.2493868 , 0.6688544 , -0.11974091, -0.2620052 , -0.76405734,
1.386133 , -0.35140836, 1.178526 , -0.81974727, 0.46690083,
1.0677673 , 1.1302416 , -0.8869794 , -0.8544902 , -0.9670916 ,
-0.94478387, 0.6199716 , -0.46729705, -1.0332688 , -1.1124989 ,
0.7350824 , 0.04479193, 0.22441705, -0.59868884, 0.11882131,
0.35034183, -0.36260536, -0.6354852 , 0.4220788 , 0.14413999,
-0.34579948, 0.9126945 , -0.19795509, 0.43683398, -1.0881344 ,
-0.78608555, 0.5626268 , 0.5466168 , -0.2932316 , -1.2576036 ,
1.0755963 , -0.6779142 , -0.9392484 , -1.2802829 , -0.3394911 ,
-0.716474 , 0.2637816 , 0.29937768, 0.91206056, 1.8418332 ,
0.27361724, -1.0325491 , -0.6608365 , -1.8913517 , 0.77435297,
-0.57699966, 0.5579054 , -0.8132517 , 0.41600275, 0.5339613 ,
0.6503824 , -0.36812037, 0.6793606 , 0.6711928 , 0.27371916,
0.32655326, 0.5731573 , -0.05868898, -1.559635 , 0.30378997,
1.4611986 , -0.4408052 , -0.7070237 , -0.01077202, 0.358124 ],
dtype=float32)
model.wv.most_similar('crop',topn=5)
[('harvest', 0.9487600326538086),
('season', 0.929538369178772),
('maize', 0.922703742980957),
('winter', 0.910554051399231),
('cotton', 0.9063386917114258)]
model.wv.most_similar('billion',topn=5)
[('conversions', 0.8357641696929932),
('marks', 0.835176408290863),
('acceptances', 0.8238958120346069),
('balance', 0.8201737403869629),
('sheet', 0.7957158088684082)]
model.wv.similarity('sale','stock')
np.float32(0.35571057)
model.wv.most_similar('bank')
[('banks', 0.8239451050758362),
('arifin', 0.7581231594085693),
('england', 0.7522256374359131),
('bankers', 0.7248610854148865),
('bundesbank', 0.7235476970672607),
('central', 0.7176351547241211),
('savings', 0.7168749570846558),
('governmnet', 0.7001072764396667),
('staunchly', 0.6942026019096375),
('paper', 0.688605546951294)]
model.wv.most_similar(positive=['france', 'franc'], negative=['england'], topn=5)
[('minus', 0.8014581799507141),
('pegged', 0.7968153357505798),
('falls', 0.7833276987075806),
('korea', 0.7762670516967773),
('scant', 0.7736948728561401)]
model.wv.most_similar(positive=['german', 'french'], negative=['mark'], topn=5)
[('slows', 0.8143584132194519),
('germany', 0.7986565232276917),
('china', 0.7916123270988464),
('france', 0.7609433531761169),
('netherlands', 0.7539501190185547)]
model.wv.most_similar(positive=['dollar', 'long'], negative=['yen'], topn=5)
[('longer', 0.8163963556289673),
('medium', 0.7842456102371216),
('near', 0.7829466462135315),
('see', 0.779902458190918),
('blip', 0.7591519951820374)]
model.wv.most_similar(positive=['wheat', 'harvest'], negative=['corn'], topn=5)
[('season', 0.9341422915458679),
('whites', 0.930144727230072),
('exported', 0.9279364943504333),
('maize', 0.9243006706237793),
('sown', 0.9201122522354126)]
30.19. Using Sent2Vec#
https://towardsdatascience.com/document-embedding-techniques-fed3e7a6a25d
%%capture
!pip install spacy
!python -m spacy download en_core_web_sm
!python -m spacy download en
%%capture
!pip install sent2vec
import nltk
nltk.download('punkt')
from scipy import spatial
from sent2vec.vectorizer import Vectorizer
from nltk.tokenize import word_tokenize
[nltk_data] Downloading package punkt to /root/nltk_data...
[nltk_data] Package punkt is already up-to-date!
sentences = [
"The traveling salesman problem is a classic hard problem in computer science.",
"The traveling salesman problem recently achieved a better solution, kudos to computer science.",
]
vectorizer = Vectorizer()
Initializing Bert distilbert-base-uncased
Vectorization done on cpu
/usr/local/lib/python3.12/dist-packages/huggingface_hub/utils/_auth.py:94: UserWarning:
The secret `HF_TOKEN` does not exist in your Colab secrets.
To authenticate with the Hugging Face Hub, create a token in your settings tab (https://huggingface.co/settings/tokens), set it as secret in your Google Colab and restart your session.
You will be able to reuse this secret in all of your notebooks.
Please note that authentication is recommended but still optional to access public models or datasets.
warnings.warn(
vectorizer.run(sentences)
vectors = vectorizer.vectors
print(len(vectors))
print(len(vectors[0]))
2
768
from scipy import spatial
result = 1 - spatial.distance.cosine(vectors[0], vectors[1])
result
np.float32(0.9466108)
30.20. Doc2Vec#
This algorithm is analogous to word2vec but instead of word embeddings it generates document embeddings. Documents that are semantically similar with be closer to each other in the embedding space.
The original paper by Quoc Le and Tomas Mikolov is here: https://arxiv.org/abs/1405.4053; https://drive.google.com/file/d/1NBtLERtwRWy_RNVG5FKqRG-8oQTedSAz/view?usp=sharing
A simple blog post that offers some more explanation: https://medium.com/scaleabout/a-gentle-introduction-to-doc2vec-db3e8c0cce5e; https://drive.google.com/file/d/1GxzHpmdRac7n8wM9QqXFhmelkmBNjU8A/view?usp=sharing
Let’s use the Reuters news corpus as an example.
#Recreate the documents (without stemming to retain whole words)
#Clean up the docs using the previous functions
news = text_array
news = removePunc(news)
news = removeNumbers(news)
news = stopText(news)
#news = stemText(news)
news = [j.lower() for j in news]
sentences = textTokenize(news)
print(len(sentences))
8471
from gensim.utils import simple_preprocess
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
n_news = range(len(news))
docs = [TaggedDocument(simple_preprocess(j),[i]) for j,i in zip(news,n_news)]
list(docs[:2])
[TaggedDocument(words=['bahia', 'cocoa', 'review', 'showers', 'continued', 'throughout', 'week', 'bahia', 'cocoa', 'zone', 'alleviating', 'drought', 'since', 'early', 'january', 'improving', 'prospects', 'coming', 'temporao', 'although', 'normal', 'humidity', 'levels', 'restored', 'comissaria', 'smith', 'said', 'weekly', 'review', 'the', 'dry', 'period', 'means', 'temporao', 'late', 'year', 'arrivals', 'week', 'ended', 'february', 'bags', 'kilos', 'making', 'cumulative', 'total', 'season', 'mln', 'stage', 'last', 'year', 'again', 'seems', 'cocoa', 'delivered', 'earlier', 'consignment', 'included', 'arrivals', 'figures', 'comissaria', 'smith', 'said', 'still', 'doubt', 'much', 'old', 'crop', 'cocoa', 'still', 'available', 'harvesting', 'practically', 'come', 'end', 'with', 'total', 'bahia', 'crop', 'estimates', 'around', 'mln', 'bags', 'sales', 'standing', 'almost', 'mln', 'hundred', 'thousand', 'bags', 'still', 'hands', 'farmers', 'middlemen', 'exporters', 'processors', 'there', 'doubts', 'much', 'cocoa', 'would', 'fit', 'export', 'shippers', 'experiencing', 'dificulties', 'obtaining', 'bahia', 'superior', 'certificates', 'in', 'view', 'lower', 'quality', 'recent', 'weeks', 'farmers', 'sold', 'good', 'part', 'cocoa', 'held', 'consignment', 'comissaria', 'smith', 'said', 'spot', 'bean', 'prices', 'rose', 'cruzados', 'per', 'arroba', 'kilos', 'bean', 'shippers', 'reluctant', 'offer', 'nearby', 'shipment', 'limited', 'sales', 'booked', 'march', 'shipment', 'dlrs', 'per', 'tonne', 'ports', 'named', 'new', 'crop', 'sales', 'also', 'light', 'open', 'ports', 'june', 'july', 'going', 'dlrs', 'dlrs', 'new', 'york', 'july', 'aug', 'sept', 'dlrs', 'per', 'tonne', 'fob', 'routine', 'sales', 'butter', 'made', 'march', 'april', 'sold', 'dlrs', 'april', 'may', 'butter', 'went', 'times', 'new', 'york', 'may', 'june', 'july', 'dlrs', 'aug', 'sept', 'dlrs', 'times', 'new', 'york', 'sept', 'oct', 'dec', 'dlrs', 'times', 'new', 'york', 'dec', 'comissaria', 'smith', 'said', 'destinations', 'covertible', 'currency', 'areas', 'uruguay', 'open', 'ports', 'cake', 'sales', 'registered', 'dlrs', 'march', 'april', 'dlrs', 'may', 'dlrs', 'aug', 'times', 'new', 'york', 'dec', 'oct', 'dec', 'buyers', 'argentina', 'uruguay', 'convertible', 'currency', 'areas', 'liquor', 'sales', 'limited', 'march', 'april', 'selling', 'dlrs', 'june', 'july', 'dlrs', 'times', 'new', 'york', 'july', 'aug', 'sept', 'dlrs', 'times', 'new', 'york', 'sept', 'oct', 'dec', 'times', 'new', 'york', 'dec', 'comissaria', 'smith', 'said', 'total', 'bahia', 'sales', 'currently', 'estimated', 'mln', 'bags', 'crop', 'mln', 'bags', 'crop', 'final', 'figures', 'period', 'february', 'expected', 'published', 'brazilian', 'cocoa', 'trade', 'commission', 'carnival', 'ends', 'midday', 'february'], tags=[0]),
TaggedDocument(words=['computer', 'terminal', 'systems', 'lt', 'cpml', 'completes', 'sale', 'computer', 'terminal', 'systems', 'inc', 'said', 'completed', 'sale', 'shares', 'common', 'stock', 'warrants', 'acquire', 'additional', 'one', 'mln', 'shares', 'lt', 'sedio', 'lugano', 'switzerland', 'dlrs', 'the', 'company', 'said', 'warrants', 'exercisable', 'five', 'years', 'purchase', 'price', 'dlrs', 'per', 'share', 'computer', 'terminal', 'said', 'sedio', 'also', 'right', 'buy', 'additional', 'shares', 'increase', 'total', 'holdings', 'pct', 'computer', 'terminal', 'outstanding', 'common', 'stock', 'certain', 'circumstances', 'involving', 'change', 'control', 'company', 'the', 'company', 'said', 'conditions', 'occur', 'warrants', 'would', 'exercisable', 'price', 'equal', 'pct', 'common', 'stock', 'market', 'price', 'time', 'exceed', 'dlrs', 'per', 'share', 'computer', 'terminal', 'also', 'said', 'sold', 'technolgy', 'rights', 'dot', 'matrix', 'impact', 'technology', 'including', 'future', 'improvements', 'lt', 'woodco', 'inc', 'houston', 'tex', 'dlrs', 'but', 'said', 'would', 'continue', 'exclusive', 'worldwide', 'licensee', 'technology', 'woodco', 'the', 'company', 'said', 'moves', 'part', 'reorganization', 'plan', 'would', 'help', 'pay', 'current', 'operation', 'costs', 'ensure', 'product', 'delivery', 'computer', 'terminal', 'makes', 'computer', 'generated', 'labels', 'forms', 'tags', 'ticket', 'printers', 'terminals'], tags=[1])]
model = gensim.models.doc2vec.Doc2Vec(docs, min_count=1)
type(model)
gensim.models.doc2vec.Doc2Vec
def __init__(documents=None, corpus_file=None, vector_size=100, dm_mean=None, dm=1, dbow_words=0, dm_concat=0, dm_tag_count=1, dv=None, dv_mapfile=None, comment=None, trim_rule=None, callbacks=(), window=5, epochs=10, shrink_windows=True, **kwargs)
Serialize/deserialize objects from disk, by equipping them with the `save()` / `load()` methods. Warnings -------- This uses pickle internally (among other techniques), so objects must not contain unpicklable attributes such as lambda functions etc.
#Doc vector: note here we use the original document tokens, not the tagged version
x = sentences[0]
print(x)
model.infer_vector(x)
['', 'bahia', 'cocoa', 'review', 'showers', 'continued', 'throughout', 'week', 'bahia', 'cocoa', 'zone', 'alleviating', 'drought', 'since', 'early', 'january', 'improving', 'prospects', 'coming', 'temporao', 'although', 'normal', 'humidity', 'levels', 'restored', 'comissaria', 'smith', 'said', 'weekly', 'review', 'the', 'dry', 'period', 'means', 'temporao', 'late', 'year', 'arrivals', 'week', 'ended', 'february', 'bags', 'kilos', 'making', 'cumulative', 'total', 'season', 'mln', 'stage', 'last', 'year', 'again', 'seems', 'cocoa', 'delivered', 'earlier', 'consignment', 'included', 'arrivals', 'figures', 'comissaria', 'smith', 'said', 'still', 'doubt', 'much', 'old', 'crop', 'cocoa', 'still', 'available', 'harvesting', 'practically', 'come', 'end', 'with', 'total', 'bahia', 'crop', 'estimates', 'around', 'mln', 'bags', 'sales', 'standing', 'almost', 'mln', 'hundred', 'thousand', 'bags', 'still', 'hands', 'farmers', 'middlemen', 'exporters', 'processors', 'there', 'doubts', 'much', 'cocoa', 'would', 'fit', 'export', 'shippers', 'experiencing', 'dificulties', 'obtaining', 'bahia', 'superior', 'certificates', 'in', 'view', 'lower', 'quality', 'recent', 'weeks', 'farmers', 'sold', 'good', 'part', 'cocoa', 'held', 'consignment', 'comissaria', 'smith', 'said', 'spot', 'bean', 'prices', 'rose', 'cruzados', 'per', 'arroba', 'kilos', 'bean', 'shippers', 'reluctant', 'offer', 'nearby', 'shipment', 'limited', 'sales', 'booked', 'march', 'shipment', 'dlrs', 'per', 'tonne', 'ports', 'named', 'new', 'crop', 'sales', 'also', 'light', 'open', 'ports', 'june', 'july', 'going', 'dlrs', 'dlrs', 'new', 'york', 'july', 'aug', 'sept', 'dlrs', 'per', 'tonne', 'fob', 'routine', 'sales', 'butter', 'made', 'march', 'april', 'sold', 'dlrs', 'april', 'may', 'butter', 'went', 'times', 'new', 'york', 'may', 'june', 'july', 'dlrs', 'aug', 'sept', 'dlrs', 'times', 'new', 'york', 'sept', 'oct', 'dec', 'dlrs', 'times', 'new', 'york', 'dec', 'comissaria', 'smith', 'said', 'destinations', 'u', 's', 'covertible', 'currency', 'areas', 'uruguay', 'open', 'ports', 'cake', 'sales', 'registered', 'dlrs', 'march', 'april', 'dlrs', 'may', 'dlrs', 'aug', 'times', 'new', 'york', 'dec', 'oct', 'dec', 'buyers', 'u', 's', 'argentina', 'uruguay', 'convertible', 'currency', 'areas', 'liquor', 'sales', 'limited', 'march', 'april', 'selling', 'dlrs', 'june', 'july', 'dlrs', 'times', 'new', 'york', 'july', 'aug', 'sept', 'dlrs', 'times', 'new', 'york', 'sept', 'oct', 'dec', 'times', 'new', 'york', 'dec', 'comissaria', 'smith', 'said', 'total', 'bahia', 'sales', 'currently', 'estimated', 'mln', 'bags', 'crop', 'mln', 'bags', 'crop', 'final', 'figures', 'period', 'february', 'expected', 'published', 'brazilian', 'cocoa', 'trade', 'commission', 'carnival', 'ends', 'midday', 'february']
array([ 0.6846443 , -0.29289347, 0.07275861, 1.1458102 , -0.01015022,
0.8655457 , -0.03248647, 0.5624907 , -0.67845714, -0.5055889 ,
-0.17485246, -0.8910265 , -0.12665012, -0.04754563, 0.25336286,
-0.2544886 , 0.76904386, 0.3251037 , 0.1717124 , -0.28704408,
0.02912343, -0.63777345, 0.1223767 , -1.4048983 , 0.37650982,
-0.39707348, -0.4013583 , -0.7251891 , -0.5964025 , 0.6678065 ,
1.370197 , -0.23014997, 0.1742396 , -0.57867813, -0.57341945,
0.40831324, -0.22017406, -0.01145124, 0.23805584, -0.7859302 ,
-0.5817843 , -0.44576353, 0.4608628 , 0.05874668, -0.45279533,
-0.17023537, 0.17530003, 0.421009 , 0.37272587, 0.01364493,
0.4694385 , -0.49259934, -0.30979565, 0.36815536, -0.39512035,
1.1365885 , -1.8067337 , 0.38755408, -0.05950157, 0.66450566,
0.46532315, 0.61420095, 0.306913 , -0.413484 , -0.1724888 ,
0.43280554, 0.4277226 , 0.02658355, -1.0008368 , 0.12165257,
-0.0077385 , 0.08573271, 0.54916376, 0.16259472, 1.7869779 ,
0.34166136, -1.1924607 , -0.01617737, 0.60784477, -0.64913905,
0.07735325, 0.02981901, -0.99938357, 0.5482046 , -0.07990636,
-0.11221288, -1.6439776 , -0.32137614, 1.1619277 , 0.55779725,
-0.31116915, 0.79573315, 0.05589624, -0.22790043, -0.17783658,
-0.09899993, -0.47727892, -0.13724756, 0.559495 , 0.1349931 ],
dtype=float32)
# Pick any document from the test corpus and infer a vector from the model
doc_id = 0
inferred_vector = model.infer_vector(sentences[doc_id])
sims = model.docvecs.most_similar([inferred_vector], topn=len(model.docvecs))
# Compare and print the most/median/least similar documents from the train corpus
print('Test Document ({}): «{}»\n'.format(doc_id, ' '.join(sentences[doc_id])))
print(u'SIMILAR/DISSIMILAR DOCS PER MODEL %s:\n' % model)
for label, index in [('MOST', 0), ('MEDIAN', len(sims)//2), ('LEAST', len(sims) - 1)]:
print(u'%s %s: «%s»\n' % (label, sims[index], ' '.join(docs[sims[index][0]].words)))
Test Document (0): « bahia cocoa review showers continued throughout week bahia cocoa zone alleviating drought since early january improving prospects coming temporao although normal humidity levels restored comissaria smith said weekly review the dry period means temporao late year arrivals week ended february bags kilos making cumulative total season mln stage last year again seems cocoa delivered earlier consignment included arrivals figures comissaria smith said still doubt much old crop cocoa still available harvesting practically come end with total bahia crop estimates around mln bags sales standing almost mln hundred thousand bags still hands farmers middlemen exporters processors there doubts much cocoa would fit export shippers experiencing dificulties obtaining bahia superior certificates in view lower quality recent weeks farmers sold good part cocoa held consignment comissaria smith said spot bean prices rose cruzados per arroba kilos bean shippers reluctant offer nearby shipment limited sales booked march shipment dlrs per tonne ports named new crop sales also light open ports june july going dlrs dlrs new york july aug sept dlrs per tonne fob routine sales butter made march april sold dlrs april may butter went times new york may june july dlrs aug sept dlrs times new york sept oct dec dlrs times new york dec comissaria smith said destinations u s covertible currency areas uruguay open ports cake sales registered dlrs march april dlrs may dlrs aug times new york dec oct dec buyers u s argentina uruguay convertible currency areas liquor sales limited march april selling dlrs june july dlrs times new york july aug sept dlrs times new york sept oct dec times new york dec comissaria smith said total bahia sales currently estimated mln bags crop mln bags crop final figures period february expected published brazilian cocoa trade commission carnival ends midday february»
SIMILAR/DISSIMILAR DOCS PER MODEL Doc2Vec<dm/m,d100,n5,w5,s0.001,t3>:
MOST (0, 0.9451453685760498): «bahia cocoa review showers continued throughout week bahia cocoa zone alleviating drought since early january improving prospects coming temporao although normal humidity levels restored comissaria smith said weekly review the dry period means temporao late year arrivals week ended february bags kilos making cumulative total season mln stage last year again seems cocoa delivered earlier consignment included arrivals figures comissaria smith said still doubt much old crop cocoa still available harvesting practically come end with total bahia crop estimates around mln bags sales standing almost mln hundred thousand bags still hands farmers middlemen exporters processors there doubts much cocoa would fit export shippers experiencing dificulties obtaining bahia superior certificates in view lower quality recent weeks farmers sold good part cocoa held consignment comissaria smith said spot bean prices rose cruzados per arroba kilos bean shippers reluctant offer nearby shipment limited sales booked march shipment dlrs per tonne ports named new crop sales also light open ports june july going dlrs dlrs new york july aug sept dlrs per tonne fob routine sales butter made march april sold dlrs april may butter went times new york may june july dlrs aug sept dlrs times new york sept oct dec dlrs times new york dec comissaria smith said destinations covertible currency areas uruguay open ports cake sales registered dlrs march april dlrs may dlrs aug times new york dec oct dec buyers argentina uruguay convertible currency areas liquor sales limited march april selling dlrs june july dlrs times new york july aug sept dlrs times new york sept oct dec times new york dec comissaria smith said total bahia sales currently estimated mln bags crop mln bags crop final figures period february expected published brazilian cocoa trade commission carnival ends midday february»
MEDIAN (6785, 0.19662708044052124): «senate wants japan semiconducter pact enforced the senate unanimously called president reagan immediately force japan live pledge stop dumping microchips open markets chipmakers the senate voted urge reagan impose penalties japanese high technology products containing semiconductors retaliation sees japan violations semiconductor pact while measure bind reagan action senate leaders said adoption would warn japan stiffer legislation would considered violations continue we want send message japan let know senate feels matter senate democratic leader robert byrd told senate senate finance committee chairman lloyd bentsen told senate measure aimed retaliation correcting japan unfair trade practices key house trade lawmaker representative richard gephardt also announced would seek force japan countries huge trade surpluses slash surplus pct year three years»
LEAST (2676, -0.4770161807537079): «lt goldome fsb year net net mln vs mln note company mutual savings bank»
/tmp/ipython-input-2819939271.py:4: DeprecationWarning: Call to deprecated `docvecs` (The `docvecs` property has been renamed `dv`.).
sims = model.docvecs.most_similar([inferred_vector], topn=len(model.docvecs))