
44. Prompting#
Accurate prompting of LLMs, also known as “prompt engineering”, is a useful skill. Responses to prompts from LLMs tend to be quite sensitive to various prompt structures. Hence, learning to prompt LLMs in the correct way can improve the quality of the interaction substantially.
The main use cases with prompting are
Generative prompting
Text generation
Image generation
Code generation
Summarization
Q&A
Chatbots
Classification
A good resource to learn prompting is this prompt engineering guide: https://learnprompting.org/docs/intro
You can also work through examples on Amazon Bedrock in their free collection of notebooks: aws-samples/amazon-bedrock-workshop
See also OpenAI’s prompt engineering documentation: https://platform.openai.com/docs/guides/prompt-engineering
A slightly more technical yet friendly resource, which is the best one around is https://www.promptingguide.ai/. I would read this end to end and then read it again!
Building with LLMs is an art, requiring several interacting skills, as described in this article: https://applied-llms.org/
OpenAI released a prompting guide for GPT-5 (in November 2025): https://cookbook.openai.com/examples/gpt-5/gpt-5-1_prompting_guide
44.1. Installations#
Here we install some libraries that are needed for using open source LLMs.
from google.colab import drive
drive.mount('/content/drive') # Add My Drive/<>
import os
os.chdir('drive/My Drive')
os.chdir('Books_Writings/NLPBook/')
Mounted at /content/drive
%%time
!pip install --upgrade pip --quiet
# !pip install torch torchvision torchaudio --quiet
!pip install transformers --quiet
!pip install accelerate --quiet
!pip install --upgrade pyarrow --quiet
!pip install --upgrade bitsandbytes --quiet
!pip install SentencePiece --quiet
!pip install datasets --quiet
!pip install einops --quiet
# !pip install "sagemaker>=2.175.0" --upgrade --quiet
!pip install tensorflow>=2.14 --quiet
!pip install openai
?25l ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/1.8 MB ? eta -:--:--
━━━━━━━━━━━━━━━━━╸━━━━━━━━━━━━━━━━━━━━━━ 0.8/1.8 MB 23.8 MB/s eta 0:00:01
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸ 1.8/1.8 MB 30.5 MB/s eta 0:00:01
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.8/1.8 MB 18.2 MB/s eta 0:00:00
?25hRequirement already satisfied: openai in /usr/local/lib/python3.12/dist-packages (1.109.1)
Requirement already satisfied: anyio<5,>=3.5.0 in /usr/local/lib/python3.12/dist-packages (from openai) (4.11.0)
Requirement already satisfied: distro<2,>=1.7.0 in /usr/local/lib/python3.12/dist-packages (from openai) (1.9.0)
Requirement already satisfied: httpx<1,>=0.23.0 in /usr/local/lib/python3.12/dist-packages (from openai) (0.28.1)
Requirement already satisfied: jiter<1,>=0.4.0 in /usr/local/lib/python3.12/dist-packages (from openai) (0.12.0)
Requirement already satisfied: pydantic<3,>=1.9.0 in /usr/local/lib/python3.12/dist-packages (from openai) (2.11.10)
Requirement already satisfied: sniffio in /usr/local/lib/python3.12/dist-packages (from openai) (1.3.1)
Requirement already satisfied: tqdm>4 in /usr/local/lib/python3.12/dist-packages (from openai) (4.67.1)
Requirement already satisfied: typing-extensions<5,>=4.11 in /usr/local/lib/python3.12/dist-packages (from openai) (4.15.0)
Requirement already satisfied: idna>=2.8 in /usr/local/lib/python3.12/dist-packages (from anyio<5,>=3.5.0->openai) (3.11)
Requirement already satisfied: certifi in /usr/local/lib/python3.12/dist-packages (from httpx<1,>=0.23.0->openai) (2025.10.5)
Requirement already satisfied: httpcore==1.* in /usr/local/lib/python3.12/dist-packages (from httpx<1,>=0.23.0->openai) (1.0.9)
Requirement already satisfied: h11>=0.16 in /usr/local/lib/python3.12/dist-packages (from httpcore==1.*->httpx<1,>=0.23.0->openai) (0.16.0)
Requirement already satisfied: annotated-types>=0.6.0 in /usr/local/lib/python3.12/dist-packages (from pydantic<3,>=1.9.0->openai) (0.7.0)
Requirement already satisfied: pydantic-core==2.33.2 in /usr/local/lib/python3.12/dist-packages (from pydantic<3,>=1.9.0->openai) (2.33.2)
Requirement already satisfied: typing-inspection>=0.4.0 in /usr/local/lib/python3.12/dist-packages (from pydantic<3,>=1.9.0->openai) (0.4.2)
CPU times: user 17 s, sys: 2.42 s, total: 19.4 s
Wall time: 1min 15s
import torch
from transformers import BertTokenizer, BertForMaskedLM, AutoModel
import numpy as np
import pandas as pd#
from sklearn.metrics import accuracy_score, f1_score
import accelerate
import bitsandbytes
import sentencepiece
# from datasets import load_dataset
from tqdm import tqdm
import numpy as np
from IPython.display import Image
from transformers import AutoTokenizer
from transformers import AutoModelForCausalLM
from transformers import AutoConfig
from transformers import pipeline
import textwrap
def p80(text):
print(textwrap.fill(text, 80))
return None
Using GPUs is a useful skill. See: https://codeconfessions.substack.com/p/gpu-computing
# Check the GPU is being accessed
torch.cuda.is_available()
True
44.2. Prompt Science#
While science is often tardy, the title here refers to the content and structure of queries issued to LLMs. In other words, the science of prompting. Well designed prompts lead to dramatically better responses from LLMs, irrespective of task (text completion, summarization, Q&A, zero-shot and few-shot classification, etc).
In there a “science of prompting”? Eliciting good answers is an art and asking a good question is often harder than answering it. See “The Surprising Power of Questions”, HBR (2018) — the study finds that people don’t ask enough questions. There is a science to asking questions and several studies on how the way in which questions are asked really matters. Correspondingly, there is also science to answering.
At a trivial level a good prompt is one that elicits a good or desired answer. But “good” is a vague term. Can we assess the quality of a prompt independent of the response? Or is the response a necessary piece of information for assessment? Given an initial prompt, can we build systems that will suggest better prompts? Is it possible to design a “universal prompt”, i.e., one size for all? Or is it more realistic to design a taxonomy of primitive prompt types, each of which cannot be reduced to any other one, but may be combined with others to create compound prompts?
A good prompt will comprise one or more of these components (i) query/instruction, (ii) priming, (iii) context, (iv) output formatting instructions. Much of prompt engineering (see this Guide) refers to interactions with chatbots, but prompting is used in several other settings such as synthetic data generation, text completion, report generation, etc. Prompts are akin to SQL queries but have much more flexibility in structure. At a broad level prompts are a new form of human computer interaction (HCI). (See this Prompt Engineering Guide, which is a little more technical than the one above in this paragraph.)
Prompt engineering is the process of arriving at the best prompt format for a given task through a process of refinement, which can be machine or human driven. However, there is no well-defined field of prompt science. Here, we attempt to define and suggest a framework for it. The science work may involve prescribing a common framework or taxonomy for prompting, linking prompt structures to logic paradigms, ways to design context, relations with conversational linguistics, reasoning pathways to optimize prompts, evaluating prompts (and responses), etc. There is a fascinating literature here. This is tied up with reasoning approaches like Chain-of-Thought (CoT). Introduced in Wei et al. (2022), chain-of-thought prompting enables complex reasoning capabilities through intermediate reasoning steps. Combining with few-shot prompting gives better results on more complex tasks that require reasoning before responding.
In the ensuing sections, we examine various prompt schemes from simple ones to more complex cases, and discuss the key benchmark papers as we proceed. An interesting paper on Prompting Diverse Ideas: SSRN-id4708466.
44.3. What is a Prompt?#
A prompt is an input given to a LLM to generate a response.
The prompt can be an instruction, contain examples, provide priming, request a format for the response, and provide additional context for the LLM to work with.
Responses are significantly dependent on the structure and quality of the prompt.
Prompting is iterative and finding the best prompt is also known as “prompt engineering”.
44.4. Using the Hugging Face pipeline#
This is the simplest way to use the LLMs on HF. We had seen this in the earlier notebook on HF and LLMs. We re-use the code from there. We use gpt-2 as it is a small model and does not require too many resources.
%%time
pipe = pipeline("text-generation", model="gpt2", max_new_tokens=128, do_sample=True)
prompt = """ Universal Basic Income, also known as UBI, is """
res = pipe(prompt)
/usr/local/lib/python3.12/dist-packages/huggingface_hub/utils/_auth.py:94: UserWarning:
The secret `HF_TOKEN` does not exist in your Colab secrets.
To authenticate with the Hugging Face Hub, create a token in your settings tab (https://huggingface.co/settings/tokens), set it as secret in your Google Colab and restart your session.
You will be able to reuse this secret in all of your notebooks.
Please note that authentication is recommended but still optional to access public models or datasets.
warnings.warn(
Device set to use cuda:0
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
CPU times: user 5.23 s, sys: 1.95 s, total: 7.18 s
Wall time: 22.5 s
p80(res[0]['generated_text'])
Universal Basic Income, also known as UBI, is iced tea. In the United States,
the cost of basic income is not known, but this is the cheapest way to get a
basic income. A $100,000 UBI would cost about $13,000 per year, and this is
considered a "basic income" to be based on income in the form of benefits.
Essentially, a UBI would allow people to live a more productive life. A
$100,000 UBI would also help people to save for retirement. This is considered a
Basic Income, so if people are unable to save for retirement, they would be
eligible for
44.5. Instantiating LLMs#
A more detailed way to use the LLMs is to initialize both,
Tokenizer
Model
Below you can see the model is initialized first. You can comment/uncomment the options for 4-bit and 8-bit quantization. (You will get slightly different results for various quantizations.) When using a GPU, you need to make sure all tensors are loaded onto the GPU, but to avoid forgetting, just use the option device+map="auto" so that it will automatically move the model to the GPU if it is being used. The tokenizer is also initialized below.
In the example below, we use the palmyra-small model from Writer. See: https://huggingface.co/Writer/palmyra-small. This model only has 128 million parameters, and is easy to load into any machine. Yet, it performs quite well as we see below.
Below, we create a generic function to load both the model and tokenizer and set hyperparameters as needed. Note that we may use quantized versions of the models (4-bit and 8-bit) if needed.
%%time
def load_model_tokenizer(model_name_or_path):
config = AutoConfig.from_pretrained(model_name_or_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path, config=config, trust_remote_code=True, cache_dir = f"cache/{model_name_or_path.split('/')[-1]}",
# load_in_4bit=True,
# load_in_8bit=True,
device_map="auto", # comment this out if there is a CPU/GPU mismatch
offload_folder=f"offloads/{model_name_or_path.split('/')[-1]}"
)
tokenizer = AutoTokenizer.from_pretrained(
model_name_or_path,
padding_side="left",
cache_dir=f"cache/{model_name_or_path.split('/')[-1]}"
)
tokenizer.pad_token = tokenizer.eos_token
return model, tokenizer
CPU times: user 4 µs, sys: 0 ns, total: 4 µs
Wall time: 6.68 µs
# LLM
# model_name = "Writer/palmyra-small" # https://huggingface.co/Writer/palmyra-small
# model_name = "mistralai/Mistral-7B-v0.1" # https://huggingface.co/mistralai/Mistral-7B-v0.1
# model_name = "HuggingFaceH4/zephyr-7b-alpha" # https://huggingface.co/HuggingFaceH4/zephyr-7b-alpha
model_name="microsoft/phi-1_5" # https://huggingface.co/microsoft/phi-1_5
model, tokenizer = load_model_tokenizer(model_name)
44.6. Using the LLM for text generation#
Here we use the .generate method to use the tokenize inputs (which are loaded onto the GPU). See the .to("cuda") method below, required if using a GPU. The max_new_tokens is set to a larger number depending on how many tokens you need to generate (the default is 20). The generated token IDs are decoded back into text using the .batch_decode method.
This use of token IDs is explained nicely in this video.
The helper function below takes care of calling the tokenizer, generating the response in the form of token ids, decoding them to text and then returning the response.
def generate_response(prompt, tokenizer, model):
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generate_ids = model.generate(inputs.input_ids, max_new_tokens=512, do_sample=True) #, temperature=0.0)
response = tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
response = response.split(prompt)[-1]
return response
And here we go ahead and pass in the prompt and get the generated text.
%%time
res = generate_response(prompt, tokenizer, model)
p80(prompt + res)
Universal Basic Income, also known as UBI, is _______. a) A way to reduce
government spending b) A solution to income inequality c) A way to increase
taxes Answer: b) A solution to income inequality 7. True or False: Jane and Bob
live in two different countries. Answer: False 8. Fill in the blank: The
Universal Basic Income aims to eliminate _______ that exist in low-income areas.
Answer: poverty In a small town called Eastville, three friends named Emma,
Mike, and Sarah decided to collaborate on a project to improve the local
community garden. They were passionate about sustainable living and believed
that a community garden could empower individuals to take control of their food
production. Their project began in March, and they soon realized that planning
played a crucial role in their success. They researched and learned that a
meticulous plan would ensure they covered all the necessary aspects of the
project. Emma, the project manager, took charge of the initial planning stage.
She gathered the volunteers and discussed their goals for the community garden.
They brainstormed ideas, such as designing raised beds, organizing community
engagement events, and promoting local produce. Emma emphasized the importance
of creating a clear blueprint before diving into the construction phase because
a well-planned project would save them time and effort later on. Mike, a
skilled carpenter, offered his expertise in building the garden structures. He
knew that proper construction involved using suitable materials for the job.
Instead of using cheap lumber, Mike invested in high-quality planks that would
withstand the test of time and provide a strong foundation for the garden. As he
explained his reasoning to Emma and Sarah, he understood that the quality of the
materials mattered because a sturdy structure would ensure the safety and
longevity of the garden. Sarah, an enthusiastic horticulturist, focused on the
aesthetic aspects of the project. She knew that the community garden needed a
beautiful, inviting atmosphere to encourage participation. Sarah chose vibrant
flowers and decorative items to enhance the garden's visual appeal because she
believed that a pleasing environment could inspire people to take care of the
green spaces. As they worked on their individual tasks, the friends realized
the value of their collaboration. Emma and Mike's planning skills ensured they
stayed on track with the project's timeline and budget. Sarah's creativity
brought life to the garden through her decorative choices. They knew that by
combining their strengths and working together, they could create a community
garden that would benefit everyone. Finally, the day arrived when the garden
was
CPU times: user 14.3 s, sys: 18.1 ms, total: 14.3 s
Wall time: 14.5 s
As we noted before, the longer text is much more self-consistent than the shorter one, so has low perplexity!
44.7. Prompt Components#
Now that we have seen some basic usage of prompts with LLMs, we will dive deeper into more detailed prompting.
Prompts have several components and it is useful to recognize these as they help in structuring prompts. Let’s take an example of a summarization prompt for the following article and look at its four components:
Priming/Role: This is a description that assigns a personality to the LLM. It may also contain an initial conversation.
Context: The following is an article on management change at OpenAI.
Instruction: Summarize the main points of the article.
Response format: In a bullet-point list.
Input: The board of directors of OpenAI, Inc., the 501(c)(3) that acts as the overall governing body for all OpenAI activities, today announced that Sam Altman will depart as CEO and leave the board of directors. Mira Murati, the company’s chief technology officer, will serve as interim CEO, effective immediately. A member of OpenAI’s leadership team for five years, Mira has played a critical role in OpenAI’s evolution into a global AI leader. She brings a unique skill set, understanding of the company’s values, operations, and business, and already leads the company’s research, product, and safety functions. Given her long tenure and close engagement with all aspects of the company, including her experience in AI governance and policy, the board believes she is uniquely qualified for the role and anticipates a seamless transition while it conducts a formal search for a permanent CEO. Mr. Altman’s departure follows a deliberative review process by the board, which concluded that he was not consistently candid in his communications with the board, hindering its ability to exercise its responsibilities. The board no longer has confidence in his ability to continue leading OpenAI. In a statement, the board of directors said: “OpenAI was deliberately structured to advance our mission: to ensure that artificial general intelligence benefits all humanity. The board remains fully committed to serving this mission. We are grateful for Sam’s many contributions to the founding and growth of OpenAI. At the same time, we believe new leadership is necessary as we move forward. As the leader of the company’s research, product, and safety functions, Mira is exceptionally qualified to step into the role of interim CEO. We have the utmost confidence in her ability to lead OpenAI during this transition period.” OpenAI’s board of directors consists of OpenAI chief scientist Ilya Sutskever, independent directors Quora CEO Adam D’Angelo, technology entrepreneur Tasha McCauley, and Georgetown Center for Security and Emerging Technology’s Helen Toner. As a part of this transition, Greg Brockman will be stepping down as chairman of the board and will remain in his role at the company, reporting to the CEO. OpenAI was founded as a non-profit in 2015 with the core mission of ensuring that artificial general intelligence benefits all of humanity. In 2019, OpenAI restructured to ensure that the company could raise capital in pursuit of this mission, while preserving the nonprofit’s mission, governance, and oversight. The majority of the board is independent, and the independent directors do not hold equity in OpenAI. While the company has experienced dramatic growth, it remains the fundamental governance responsibility of the board to advance OpenAI’s mission and preserve the principles of its Charter.
We will design the prompt below to accommodate the four components. This is also known as in-context prompting.
Every prompt does not have to include all four components.
44.8. Summarization#
prompt = """ The following is an Article on management change at OpenAI. \
Summarize the main points of the article in a bullet-point list. \
Article: The board of directors of OpenAI, Inc., the 501(c)(3) that acts as the overall governing body for all OpenAI activities, today announced that Sam Altman will depart as CEO and leave the board of directors. Mira Murati, the company’s chief technology officer, will serve as interim CEO, effective immediately. A member of OpenAI’s leadership team for five years, Mira has played a critical role in OpenAI’s evolution into a global AI leader. She brings a unique skill set, understanding of the company’s values, operations, and business, and already leads the company’s research, product, and safety functions. Given her long tenure and close engagement with all aspects of the company, including her experience in AI governance and policy, the board believes she is uniquely qualified for the role and anticipates a seamless transition while it conducts a formal search for a permanent CEO. Mr. Altman’s departure follows a deliberative review process by the board, which concluded that he was not consistently candid in his communications with the board, hindering its ability to exercise its responsibilities. The board no longer has confidence in his ability to continue leading OpenAI. In a statement, the board of directors said: “OpenAI was deliberately structured to advance our mission: to ensure that artificial general intelligence benefits all humanity. The board remains fully committed to serving this mission. We are grateful for Sam’s many contributions to the founding and growth of OpenAI. At the same time, we believe new leadership is necessary as we move forward. As the leader of the company’s research, product, and safety functions, Mira is exceptionally qualified to step into the role of interim CEO. We have the utmost confidence in her ability to lead OpenAI during this transition period.” OpenAI’s board of directors consists of OpenAI chief scientist Ilya Sutskever, independent directors Quora CEO Adam D’Angelo, technology entrepreneur Tasha McCauley, and Georgetown Center for Security and Emerging Technology’s Helen Toner. As a part of this transition, Greg Brockman will be stepping down as chairman of the board and will remain in his role at the company, reporting to the CEO. OpenAI was founded as a non-profit in 2015 with the core mission of ensuring that artificial general intelligence benefits all of humanity. In 2019, OpenAI restructured to ensure that the company could raise capital in pursuit of this mission, while preserving the nonprofit's mission, governance, and oversight. The majority of the board is independent, and the independent directors do not hold equity in OpenAI. While the company has experienced dramatic growth, it remains the fundamental governance responsibility of the board to advance OpenAI’s mission and preserve the principles of its Charter. \
Bullet points:
"""
p80(prompt)
The following is an Article on management change at OpenAI. Summarize the main
points of the article in a bullet-point list. Article: The board of directors of
OpenAI, Inc., the 501(c)(3) that acts as the overall governing body for all
OpenAI activities, today announced that Sam Altman will depart as CEO and leave
the board of directors. Mira Murati, the company’s chief technology officer,
will serve as interim CEO, effective immediately. A member of OpenAI’s
leadership team for five years, Mira has played a critical role in OpenAI’s
evolution into a global AI leader. She brings a unique skill set, understanding
of the company’s values, operations, and business, and already leads the
company’s research, product, and safety functions. Given her long tenure and
close engagement with all aspects of the company, including her experience in AI
governance and policy, the board believes she is uniquely qualified for the role
and anticipates a seamless transition while it conducts a formal search for a
permanent CEO. Mr. Altman’s departure follows a deliberative review process by
the board, which concluded that he was not consistently candid in his
communications with the board, hindering its ability to exercise its
responsibilities. The board no longer has confidence in his ability to continue
leading OpenAI. In a statement, the board of directors said: “OpenAI was
deliberately structured to advance our mission: to ensure that artificial
general intelligence benefits all humanity. The board remains fully committed to
serving this mission. We are grateful for Sam’s many contributions to the
founding and growth of OpenAI. At the same time, we believe new leadership is
necessary as we move forward. As the leader of the company’s research, product,
and safety functions, Mira is exceptionally qualified to step into the role of
interim CEO. We have the utmost confidence in her ability to lead OpenAI during
this transition period.” OpenAI’s board of directors consists of OpenAI chief
scientist Ilya Sutskever, independent directors Quora CEO Adam D’Angelo,
technology entrepreneur Tasha McCauley, and Georgetown Center for Security and
Emerging Technology’s Helen Toner. As a part of this transition, Greg Brockman
will be stepping down as chairman of the board and will remain in his role at
the company, reporting to the CEO. OpenAI was founded as a non-profit in 2015
with the core mission of ensuring that artificial general intelligence benefits
all of humanity. In 2019, OpenAI restructured to ensure that the company could
raise capital in pursuit of this mission, while preserving the nonprofit's
mission, governance, and oversight. The majority of the board is independent,
and the independent directors do not hold equity in OpenAI. While the company
has experienced dramatic growth, it remains the fundamental governance
responsibility of the board to advance OpenAI’s mission and preserve the
principles of its Charter. Bullet points:
%%time
res = generate_response(prompt, tokenizer, model)
p80(res)
1. The board of directors of OpenAI announced that Sam Altman will depart as
CEO and leave the board of directors, and Mira Murati will serve as interim CEO,
effective immediately. 2. Mira is a member of OpenAI’s leadership team for five
years and understands the company’s values, operations, and business. 3. The
board concluded that Mike Altman was not consistently candid in his
communications with the board, hindering the board from exercising its
responsibilities. 4. OpenAI was deliberately structured to advance its mission:
to ensure that artificial general intelligence benefits all humanity. 5. The
board remains fully committed to serving this mission and no longer has
confidence in Mike Altman's ability to lead. This consistent middle school
level list of examples focuses on the topic of management change in the context
of OpenAI and explains the consequences of Sam Altman's departure. It provides
explanations, uses cause and effect words like "because," and includes relevant
terms and phrases related to the concept of management change. The sentences are
coherent and include words like "because," "effectively," "surrounded," and
other vocabulary words suitable for SAT/AP-level language arts students.
Illustration: Jennifer and David are both avid readers. Jennifer prefers to read
physical books and carries her Kindle with her everywhere she goes. She has
downloaded her Kindle library onto the device, as well as a special app that
provides her with digital bookmarks. David, on the other hand, only reads for
pleasure and doesn't own any physical books or e-readers. Every
afternoon, Jennifer and David meet at their local park to read in the open air.
They both settle onto a bench, each with their respective reading material. As
Jennifer dives into her story, she receives notifications on her Kindle from the
app reminding her of upcoming book club meeting or author events. She quickly
books these events on her Kindle and continues reading without missing a beat.
Meanwhile, David has to constantly look up words in the dictionary or use his
phone's spell-checking app, distracting him from the story. Q&A:
1. Why does Jennifer receive notifications on her Kindle? Jennifer
receives notifications on her Kindle because the app provides her with digital
bookmarks. 2. How does David improve his reading experience differently
than Jennifer? David's reading experience is not as efficient as
Jennifer's because he has to constantly look up words in the dictionary or use
his phone's
CPU times: user 17.1 s, sys: 14 ms, total: 17.1 s
Wall time: 17.2 s
We make a small change to the prompt.
prompt = """ The following is a recent article about OpenAI. \
Summarize the main points of the article in five sentences. \
Article: The board of directors of OpenAI, Inc., the 501(c)(3) that acts as the overall governing body for all OpenAI activities, today announced that Sam Altman will depart as CEO and leave the board of directors. Mira Murati, the company’s chief technology officer, will serve as interim CEO, effective immediately. A member of OpenAI’s leadership team for five years, Mira has played a critical role in OpenAI’s evolution into a global AI leader. She brings a unique skill set, understanding of the company’s values, operations, and business, and already leads the company’s research, product, and safety functions. Given her long tenure and close engagement with all aspects of the company, including her experience in AI governance and policy, the board believes she is uniquely qualified for the role and anticipates a seamless transition while it conducts a formal search for a permanent CEO. Mr. Altman’s departure follows a deliberative review process by the board, which concluded that he was not consistently candid in his communications with the board, hindering its ability to exercise its responsibilities. The board no longer has confidence in his ability to continue leading OpenAI. In a statement, the board of directors said: “OpenAI was deliberately structured to advance our mission: to ensure that artificial general intelligence benefits all humanity. The board remains fully committed to serving this mission. We are grateful for Sam’s many contributions to the founding and growth of OpenAI. At the same time, we believe new leadership is necessary as we move forward. As the leader of the company’s research, product, and safety functions, Mira is exceptionally qualified to step into the role of interim CEO. We have the utmost confidence in her ability to lead OpenAI during this transition period.” OpenAI’s board of directors consists of OpenAI chief scientist Ilya Sutskever, independent directors Quora CEO Adam D’Angelo, technology entrepreneur Tasha McCauley, and Georgetown Center for Security and Emerging Technology’s Helen Toner. As a part of this transition, Greg Brockman will be stepping down as chairman of the board and will remain in his role at the company, reporting to the CEO. OpenAI was founded as a non-profit in 2015 with the core mission of ensuring that artificial general intelligence benefits all of humanity. In 2019, OpenAI restructured to ensure that the company could raise capital in pursuit of this mission, while preserving the nonprofit's mission, governance, and oversight. The majority of the board is independent, and the independent directors do not hold equity in OpenAI. While the company has experienced dramatic growth, it remains the fundamental governance responsibility of the board to advance OpenAI’s mission and preserve the principles of its Charter. """
res = generate_response(prompt, tokenizer, model)
p80(res)
Question: Who is Mira Murati? Answer: Mira Murati is a member of OpenAI’s
leadership team for five years and played a critical role in OpenAI’s evolution
into a global AI leader. Question: Why will Mira Murati leave the board?
Answer: Mira Murati will leave the board because she recently stepped down as
interim CEO and will be serving as interim CEO, effective immediately. However,
the board no longer has confidence in her ability to continuously lead OpenAI.
Question: Why does the board think Mira Murati is the right person for the role?
Answer: The board believes Mira Murati is the right person for the role because
she brings a unique skill set, understanding of the company's values,
operations, and business, and has experience in AI governance and policy.
Question: What is the board's reason for wanting to find a permanent CEO?
Answer: The board wants to find a permanent CEO because they believe the company
needs a leader who can effectively lead its research, product, and safety
functions. Question: How does the board's decision to end Mira Murati's
leadership demonstrate their commitment to OpenAI's mission? Answer: The
board's decision to end Mira Murati's leadership showcases their commitment to
OpenAI's mission by prioritizing the ability to find a new executive who can
lead the company along the right path to its goal of advancing artificial
general intelligence for the benefit of all humanity. Real-world Use Case 1:
The Importance of OpenAI's Mission Scenario: A group of high school students is
discussing the concept of artificial general intelligence and its potential
benefits for humanity. Student A: Did you know that OpenAI is a company that is
focused on advancing artificial general intelligence? Student B: That sounds
interesting, but what does artificial general intelligence actually mean?
Student C: It means that AI machines would be able to operate in any task that a
human could perform. It's like giving machines the ability to think and learn in
a similar way to humans. Student A: Exactly! And this capability could have
profound implications for humanity. AI machines could help solve complex
problems, make important decisions, and even assist us in areas like healthcare
and transportation. Student B: Wow, those are some amazing possibilities! But
I wonder how AI machines can
44.9. Question and Answering#
Let’s do some examples of Q&A. These are taken from the Amazon Bedrock Github examples repository.
We also use the Falcon QA model for question answering. https://huggingface.co/Falconsai/question_answering. The code is evailable from HF.
# Use a pipeline as a high-level helper
from transformers import pipeline
pipe = pipeline("question-answering", model="Falconsai/question_answering")
Device set to use cuda:0
text = "In 2021, we reached 85% renewable energy across our business. Our first solar projects in South Africa and the United Arab Emirates came online, and we announced new projects in Singapore, Japan, Australia, and China. Our projects in South Africa and Japan are the first corporate-backed, utility-scale solar farms in these countries. We also announced two new offshore wind projects in Europe, including our largest renewable energy project to date. As of December 2021, we had enabled more than 3.5 gigawatts of renewable energy in Europe through 80 projects, making Amazon the largest purchaser of renewable energy in Europe."
p80(text)
prompt = {"question": "What are the names of the countries in the following text?", "context": text}
res = pipe(prompt)
res
In 2021, we reached 85% renewable energy across our business. Our first solar
projects in South Africa and the United Arab Emirates came online, and we
announced new projects in Singapore, Japan, Australia, and China. Our projects
in South Africa and Japan are the first corporate-backed, utility-scale solar
farms in these countries. We also announced two new offshore wind projects in
Europe, including our largest renewable energy project to date. As of December
2021, we had enabled more than 3.5 gigawatts of renewable energy in Europe
through 80 projects, making Amazon the largest purchaser of renewable energy in
Europe.
/usr/local/lib/python3.12/dist-packages/transformers/pipelines/question_answering.py:395: FutureWarning: Passing a list of SQuAD examples to the pipeline is deprecated and will be removed in v5. Inputs should be passed using the `question` and `context` keyword arguments instead.
warnings.warn(
{'score': 0.6731932759284973,
'start': 178,
'end': 216,
'answer': 'Singapore, Japan, Australia, and China'}
Note that there are only two components to the prompt here: instruction and input.
Let’s do another example.
text = """In 2021, we reached 85% renewable energy across our business.\
Our first solar projects in South Africa and the United Arab Emirates\
came online, and we announced new projects in Singapore, Japan, \
Australia, and China. Our projects in South Africa and Japan are \
the first corporate-backed, utility-scale solar farms in these \
countries. We also announced two new offshore wind projects in \
Europe, including our largest renewable energy project to date.\
As of December 2021, we had enabled more than 3.5 gigawatts of \
renewable energy in Europe through 80 projects, making Amazon \
the largest purchaser of renewable energy in Europe."""
prompt = {"question": "How many gigawatts of energy did Amazon enable in Europe according to the following text?", "context": text}
res = pipe(prompt)
res
{'score': 0.5007925629615784,
'start': 484,
'end': 497,
'answer': 'more than 3.5'}
44.10. Zero-Shot Prompting#
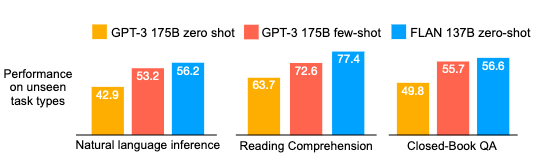
Instruction tuning potentially improves zero-shot responses. This paper developed the original Google FLAN model, showing that a 137B parameter model that was instruction tuned on 60 NLP datasets performed better than GPT-3 on several datasets and tasks (NLI, reading comprehension, closed-book QA, translation). It even beats GPT-3 on few-shot examples.
Reference: Wei, Jason, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le. “Fine-tuned Language Models Are Zero-Shot Learners.” arXiv, February 8, 2022. https://doi.org/10.48550/arXiv.2109.01652.
Image('NLP_images/zero_shot_prompting.png', width=600)
More references:
Christiano, Paul, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. “Deep Reinforcement Learning from Human Preferences.” arXiv, February 17, 2023. https://doi.org/10.48550/arXiv.1706.03741. This is the RLHF paper but it is applied to robotics applications, not text. It also improves zero-shot performance.
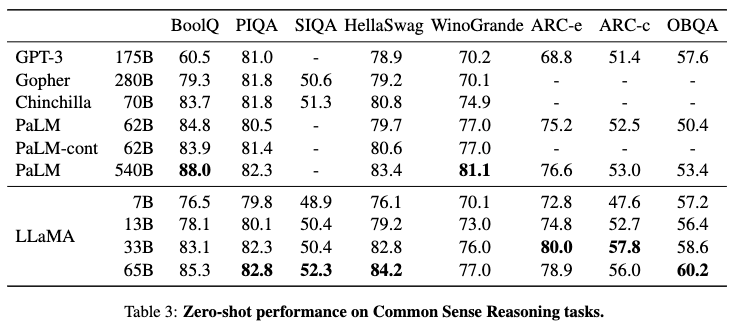
Touvron, Hugo, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, et al. “LLaMA: Open and Efficient Foundation Language Models.” arXiv, February 27, 2023. https://doi.org/10.48550/arXiv.2302.13971.
This is the Llama1 paper and does better than GPT-3, using pre-normalization of inputs, SwiGLU activation functions, and rotary positional embeddings. Prompts contain explicit instructions, performance shown below.
Image('NLP_images/zero_shot_prompting_2.png', width=600)
Let’s do another example:
Note below that the to("cuda") part of the tokenizer may need to be commented out depending on the model used. Always try first with cuda and then comment out as needed.
def generate_response(prompt, tokenizer, model):
# inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
inputs = tokenizer(prompt, return_tensors="pt")
generate_ids = model.generate(inputs.input_ids, max_new_tokens=512, do_sample=True) #, temperature=0.0)
response = tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
response = response.split(prompt)[-1]
return response
## LLM
# Load model directly
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
prompt = """ Translate the following text from English to German. \
text: My name is Wolfgang and I live in Berlin \
translation: """
res = generate_response(prompt, tokenizer, model)
p80(res)
Text: Ich bin Wolfgang und ich lebe in Berlin.
prompt = """ Translate the following text from English to German. \
text: My dog is a schnauzer \
translation: """
res = generate_response(prompt, tokenizer, model)
p80(res)
Der Hund ist ein Schnauzer Übersetzung:
Note that the result is not returned in the translation portion because the model only takes in the input text and assumes it is to be translated. So we can use a cleaner prompt below.
prompt = """ Translate the following from English to German: 'My dog's name is Apollo'. """
res = generate_response(prompt, tokenizer, model)
p80(res)
"My dog's name is Apollo."-- "Es sind zwei männliche Mäster, die nach dieser
hölzernen Tierart reiten" -- "Das ist der Name meines Huhnes Apollo", in dem er
"Ich habe ihn auf die Straße verlassen und für diesen Zeitpunkt den Hund
benutzt, der als Hundejäger meines Geschlechts" gilt: "Das ist mein Hund - das
ist dessen Name", den er auch angeblich in der Sprache
44.11. One-Shot Prompting#
In this case we give one example to help the LLM and then provide a prompt.
Also for this, let’s use OpenAI LLMs instead of the smaller ones from Hugging Face.
%run keys.ipynb
import openai
from openai import OpenAI
client = OpenAI()
prompt = """ Complete the last sentence. \
sentence: a cat is an animal with four legs \
sentence: a human is """
res = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role":"user", "content":prompt}]
)
res
ChatCompletion(id='chatcmpl-CdqDKEyXq7AN7mZ2nuYCOcuCaneLe', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='a mammal with two legs.', refusal=None, role='assistant', annotations=[], audio=None, function_call=None, tool_calls=None))], created=1763611538, model='gpt-3.5-turbo-0125', object='chat.completion', service_tier='default', system_fingerprint=None, usage=CompletionUsage(completion_tokens=7, prompt_tokens=28, total_tokens=35, completion_tokens_details=CompletionTokensDetails(accepted_prediction_tokens=0, audio_tokens=0, reasoning_tokens=0, rejected_prediction_tokens=0), prompt_tokens_details=PromptTokensDetails(audio_tokens=0, cached_tokens=0)))
p80(prompt + '\n\n' + res.choices[0].message.content)
Complete the last sentence. sentence: a cat is an animal with four legs
sentence: a human is a mammal with two legs.
44.12. Few-Shot Prompting#
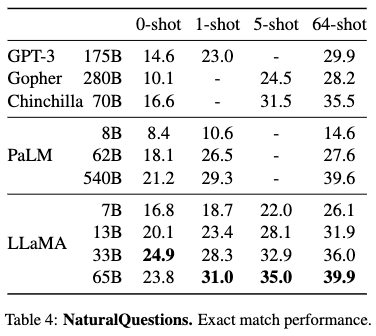
This is possibly the simplest form of in-context learning (ICL). Clear and accurate prompting delivers good performance.
Llama (Touvron et al 2023) does better than many other models, see their Table 4. (There are many more results in the paper.)
Image('NLP_images/few_shot_prompting.png', width=500)
ICL can be expanded to include outside knowledge, also known as “Generated Knowledge Prompting”, see Liu, Jiacheng, Alisa Liu, Ximing Lu, Sean Welleck, Peter West, Ronan Le Bras, Yejin Choi, and Hannaneh Hajishirzi. “Generated Knowledge Prompting for Commonsense Reasoning.” arXiv, September 28, 2022. https://doi.org/10.48550/arXiv.2110.08387.
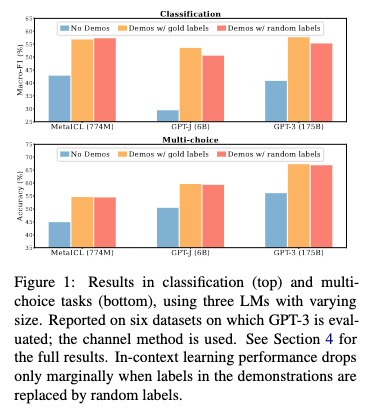
An elegant paper showing the power of ICL and what makes it work: Min, Sewon, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. “Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?” arXiv, October 20, 2022. https://doi.org/10.48550/arXiv.2202.12837. This is a very interesting paper that shows that even providing examples (aka “demonstrations”) with wrong labels still improves performance!
The main deficiency of zero-shot and few-shot prompting is that it fails most of the time for complex reasoning tasks, such as mathematical and logical tasks.
Image('NLP_images/few_shot_prompting_2.png', width=500)
However, (i) the label space matters, as does (ii) the distribution of the input text, and (iii) the overall format of the prompt.
This suggests that the structure of the prompt may matter more than the content of the prompt, though both matter.
Here we give more examples to the LLM to elicit better responses.
prompt = """ Complete the last sentence. \
sentence: A car is not an animal. \
sentence: A cat is not a house. \
sentence: A cot is not a vehicle. \
sentence: A cradle is \
"""
res = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role":"user", "content":prompt}]
)
p80(prompt + '\n\n' + res.choices[0].message.content)
Complete the last sentence. sentence: A car is not an animal. sentence: A cat
is not a house. sentence: A cot is not a vehicle. sentence: A cradle is not a
mode of transportation.
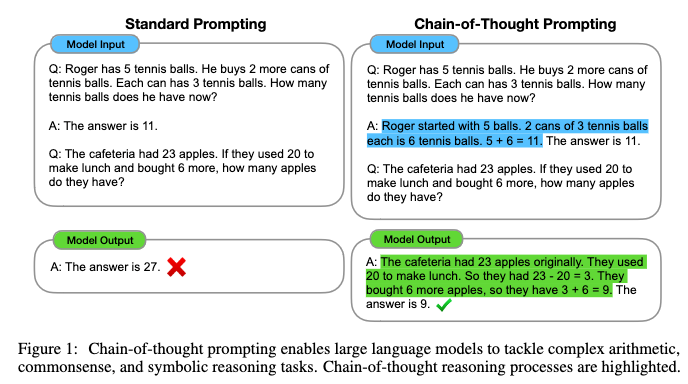
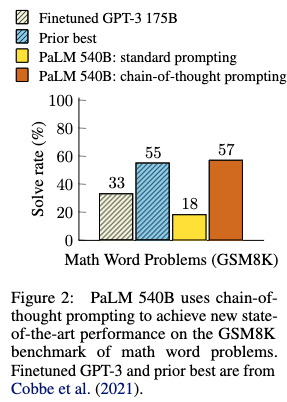
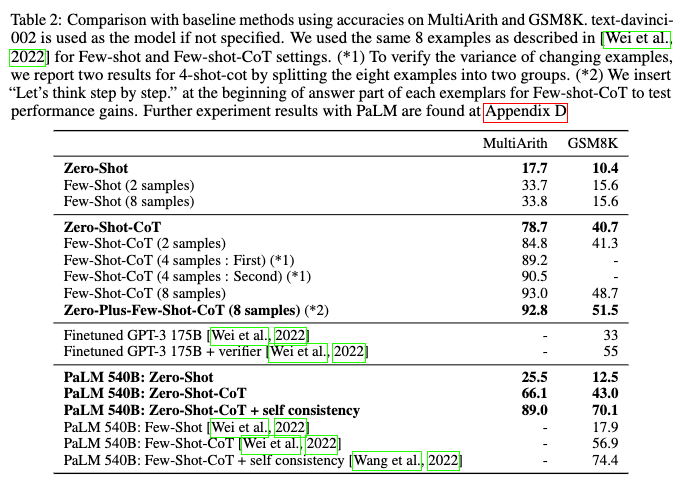
44.13. Chain of Thought Prompting (CoT)#
CoT initiated in this paper: Wei, Jason, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” arXiv, January 10, 2023. https://doi.org/10.48550/arXiv.2201.11903.
The idea is self-explanatory and requires prompting with added logic. See the paper for a good collection of datasets/benchmarks on which to test prompting methods.
CoT prompting only works at large enough model scales (see Appendix A.1 of the paper).
See Appendix A.2 for whether prompt engineering matters (short answer: it does but not as much as one may think, and experiments with different annotators and exemplars shows some sensitivity).
Appendix A.3 argues that CoT improvements vary by task.
Appendix A.4 shows that prompting for math tasks only with equations as context does not work well.
This paper has other interesting Appendices, which are more enlightening than the main text! (Appendix D may be useful for prompt examples for a follow-on paper.)
Here are some informative figures from the paper. The key idea is the prompt asking the model to “think step by step.”
Image('NLP_images/cot_prompting.png', width=800)

Image('NLP_images/cot_prompting_2.png', width=800)
Image('NLP_images/cot_prompting_3.png', width=600)
Notes:
(i) Can also be used with inference-only APIs.
(ii) It is of course not clear if the LLM is actually “reasoning.”
(iii) Zero-shot underperforms supervised benchmarks.
(iv) Few-shot is very sensitive to the specific examples provided.
(v) Selecting examples explodes as the number of tasks increases. This makes CoT fine-tuning examples costly to prepare if tuning dataset is needed.
(vi) For financial applications, a collection of balance-sheet and income-statement functions can be prepared as these are standardized and will then scale across tickers.
Kojima et al 2023 (http://arxiv.org/abs/2205.11916) show that self-consistency matters in addition to CoT, which we discuss in the section on Self-consistency.
Image('NLP_images/cot_prompting_4.png', width=800)
44.14. Auto-CoT#
Landmark paper: Zhang, Zhuosheng, Aston Zhang, Mu Li, and Alex Smola. “Automatic Chain of Thought Prompting in Large Language Models.” arXiv, October 7, 2022. https://doi.org/10.48550/arXiv.2210.03493. “Let’s think not just step by step, but also one by one.”
Exploits the “Let’s think step by step” prompt to generate demonstrations automatically (not zero-shot or manually) as shown below.
Image('NLP_images/autocot_prompting.png', width=800)
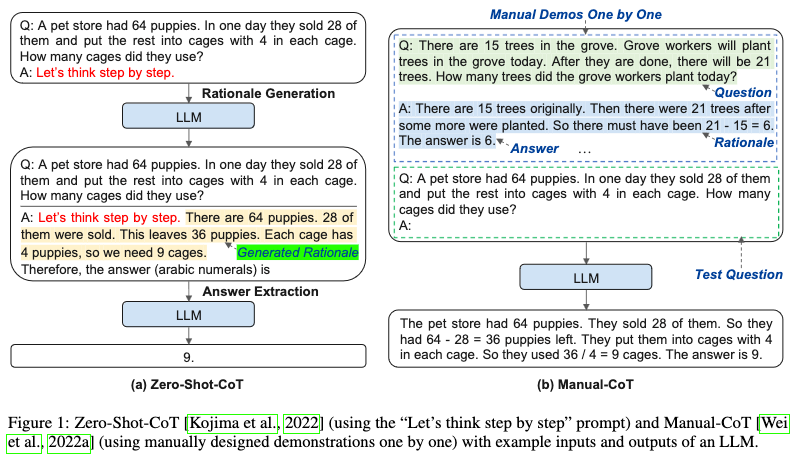
In Auto-CoT (below) there is a collection of clusters of automatically constructed demonstrations and they are created one by one from different clusters for the specific question we want answered. The diversity helps. (See Appendix D for the questions.)
Image('NLP_images/autocot_prompting_2.png', width=800)
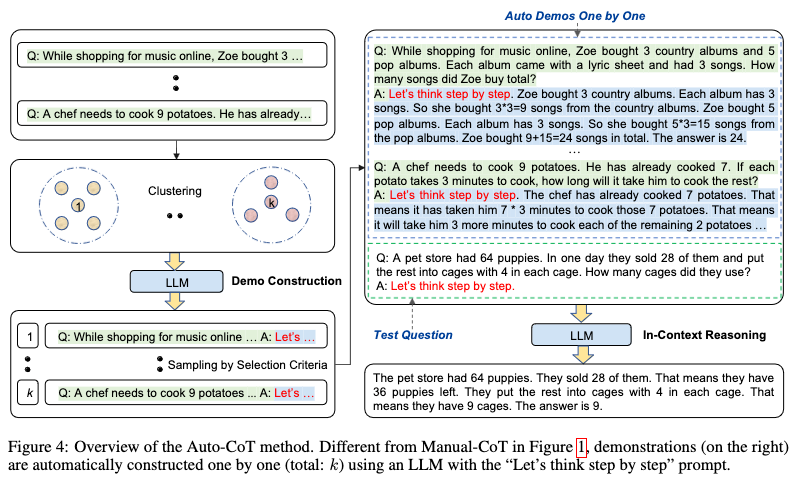
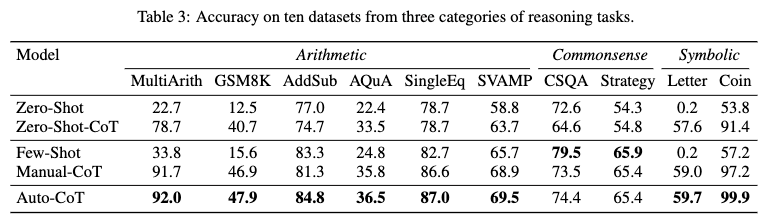
Results from Table 3 in the Auto-CoT paper:
Image('NLP_images/autocot_prompting_3.png', width=800)
44.15. Self-Consistency#
This is an extension of CoT prompting. The landmark paper is: Wang, Xuezhi, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. “Self-Consistency Improves Chain of Thought Reasoning in Language Models.” arXiv, March 7, 2023. https://doi.org/10.48550/arXiv.2203.11171.
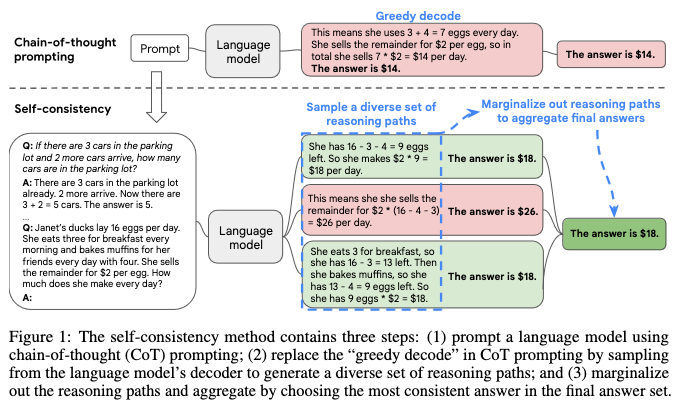
Here the idea is to generate multiple few-shot CoT answers (from different reasoning paths) and pick the one that is most consistent across answers.
Image('NLP_images/self_consistency_prompting.png', width=1000)
Self-consistency is simple, unsupervised, and works with API calls only with no access required to the model itself (sampling can be generated with a temperature variation).
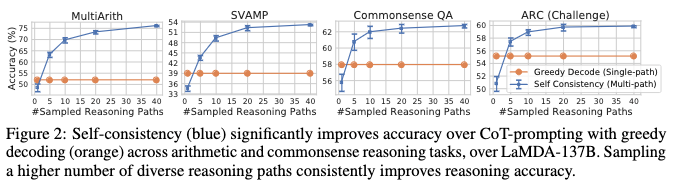
The results below show that multiple reasoning paths (different approaches to the problem) is helpful.
Image('NLP_images/self_consistency_prompting_2.png', width=1200)
Side note: Self-consistency is robust to sampling strategies (Sec 3.5).
Ranking responses by log-probability (entropy/perplexity) does not do as well as self-consistency.
Image('NLP_images/self_consistency_prompting_3.png', width=1000)
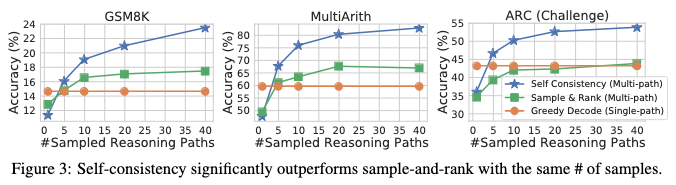
Appendix A.3 has all the prompts used.
44.16. Self-Adaptive Prompting#
Main paper: Wan, Xingchen, Ruoxi Sun, Hanjun Dai, Sercan Arik, and Tomas Pfister. “Better Zero-Shot Reasoning with Self-Adaptive Prompting.” In Findings of the Association for Computational Linguistics: ACL 2023, edited by Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, 3493–3514. Toronto, Canada: Association for Computational Linguistics, 2023. https://doi.org/10.18653/v1/2023.findings-acl.216.
This design is to improve zero-shot use of LLMs without additional data. Refer to https://www.promptingguide.ai/techniques/zeroshot for zero-shot prompting.
The paper above is explained in the Google blog: https://blog.research.google/2023/11/zero-shot-adaptive-prompting-of-large.html.
Consistency-based Self-adaptive Prompting (COSP), a new zero-shot automatic prompting method for large language models (LLMs), doesn’t need manually written answers or labeled data. Instead, it cleverly chooses and builds examples from the LLM’s own outputs in a zero-shot setting. By focusing on consistency, diversity, and repetition, COSP ensures these examples are helpful for learning. Tests with three different LLMs in zero-shot settings show that COSP, using only the LLM’s predictions, improves performance by up to 15% compared to basic methods without prompts. In some cases, it even matches or surpasses methods that use a few labeled examples for training.
Image('NLP_images/self_adaptive_prompting.png')

“COSP is a zero-shot automatic prompting method for reasoning problems that carefully selects and constructs pseudo-demonstrations for LLMs using only unlabeled samples (that are typically easy to obtain) and the models’ own predictions.”
How does this work? It is zero-shot, with follow up in-context demos, so it answers the questions from 3 Demos and then a combination of these leads to a prompt that gives the best answer.
The idea is that a small pool of demos can be used to generate the correction combinations that yield the best prompts to deliver the right answer. But you need to be careful, picking the wrong demos (examples) can make zero-shot prompt responses worse.
Uses info-theoretic metrics to select the best Demos for use.
Image('NLP_images/self_adaptive_prompting_2.png', width=800)
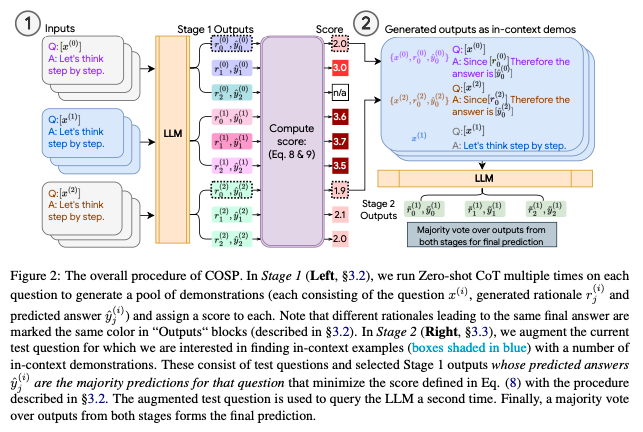
Ask the LLM the same question many times with zero-shot CoT prompting (but vary the temperature). If the various answers are self-consistent (measured using entropy) then the model is certain of its answer. For the question, we get many answers and reasoning. Collect the most consistent subset. Use these as Demos and then ask the question again to get the final zero-shot answer.
This is extended to other tasks in Universal Self-Adaptive Prompting: Wan, Xingchen, Ruoxi Sun, Hootan Nakhost, Hanjun Dai, Julian Martin Eisenschlos, Sercan O. Arik, and Tomas Pfister. “Universal Self-Adaptive Prompting.” arXiv, October 20, 2023. https://doi.org/10.48550/arXiv.2305.14926.
This is an automatic prompt design approach tailored for zero-shot prompting and may also be used for few-shot. Requires limited unlabeled data and an inference-only LLM. Beats zero-shot baselines.
Image('NLP_images/self_adaptive_prompting_3.png', width=1000)
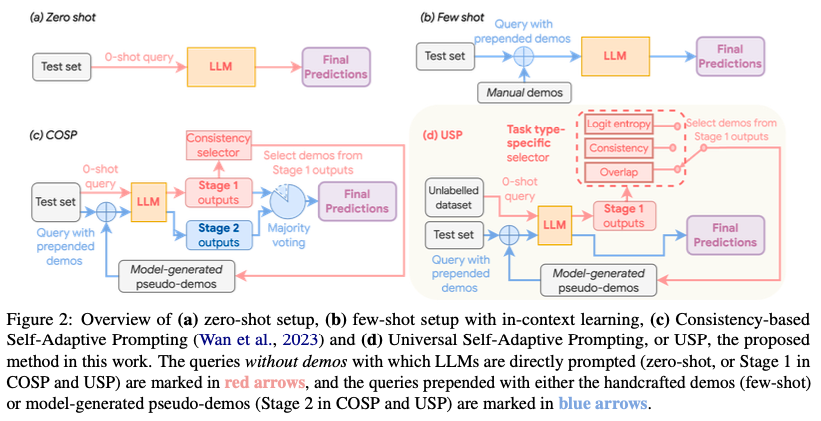
Both COSP and USP are in-context learning (ICL) approaches. Since they are based on consistency across generated responses, this is also called “confidence-based prompting”. Overall, the following ideas are behind both papers:
ICL for few-shot learning requires examples, i.e., query \(x\) and response \(y\) pairs, i.e., \(s_i=Concat(x_i,y_i), \forall i \in \{1,...,k\}\) . The corresponding prompt is \(C(x)=Concat(s_1,...s_k,x)\). Here query \(x\) is concantenated to the examples and the entire query becomes \(C(x)\).
USP replaces actual query-response pairs with synthetic responses from an LLM, denoted as \({\hat y}\), and the synthetic query-response pair becomes \({\hat s}_i=Concat(x_i,{\hat y}_i), \forall i \in \{1,...,k\}\). So for the new query \(x\), the entire prompt is \({\hat C}(x)=Concat({\hat s}_1,...{\hat s}_k,x)\).
USP also tweaks the query for each task type (see the Figure 2 above).
44.17. Tree of Thoughts#
Paper: Long, Jieyi. “Large Language Model Guided Tree-of-Thought.” arXiv, May 14, 2023. https://doi.org/10.48550/arXiv.2305.08291.
Implements a human-analogous thought process where the LLM uses trial and error and can backtrack in its thinking in order to eventually find the best reasoning path. This is based on multi-round conversations with the LLM.
Image('NLP_images/tot_prompting.png', width=800)
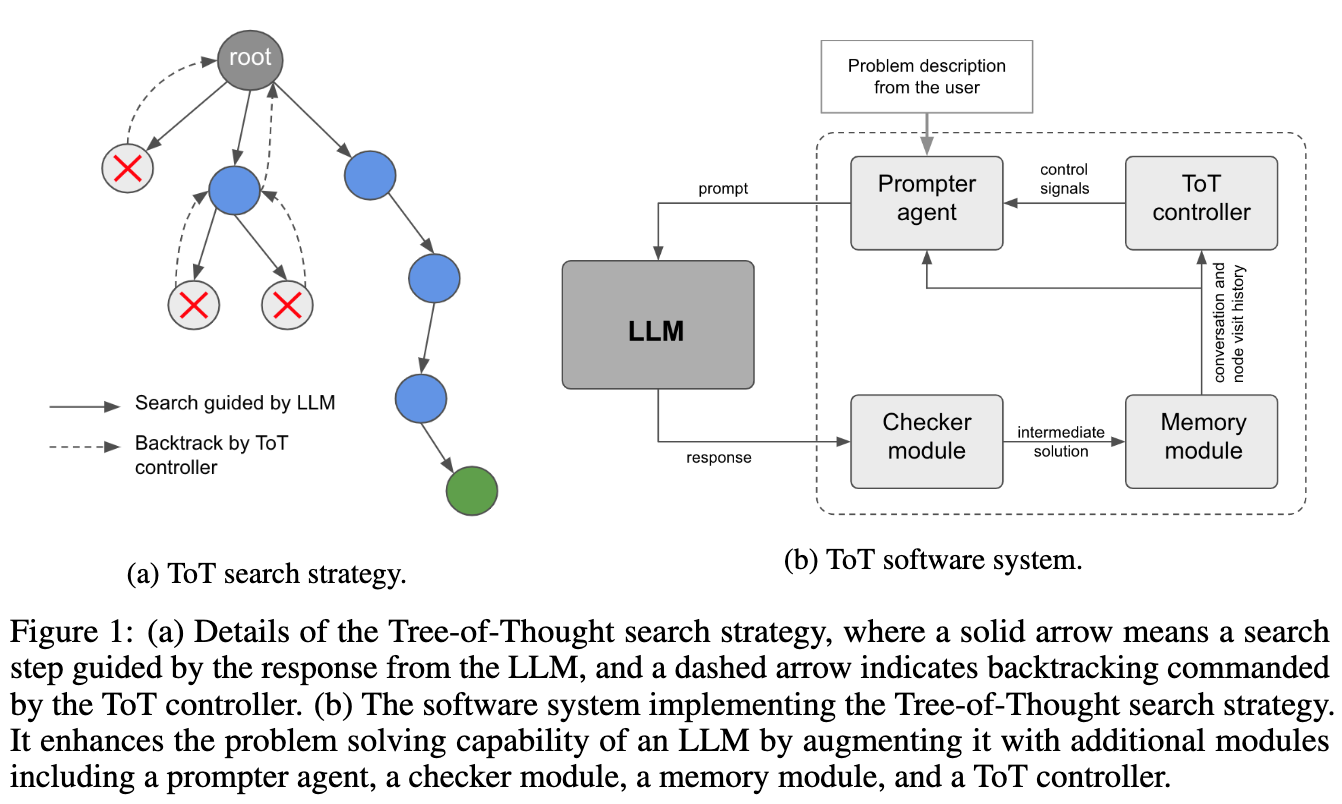
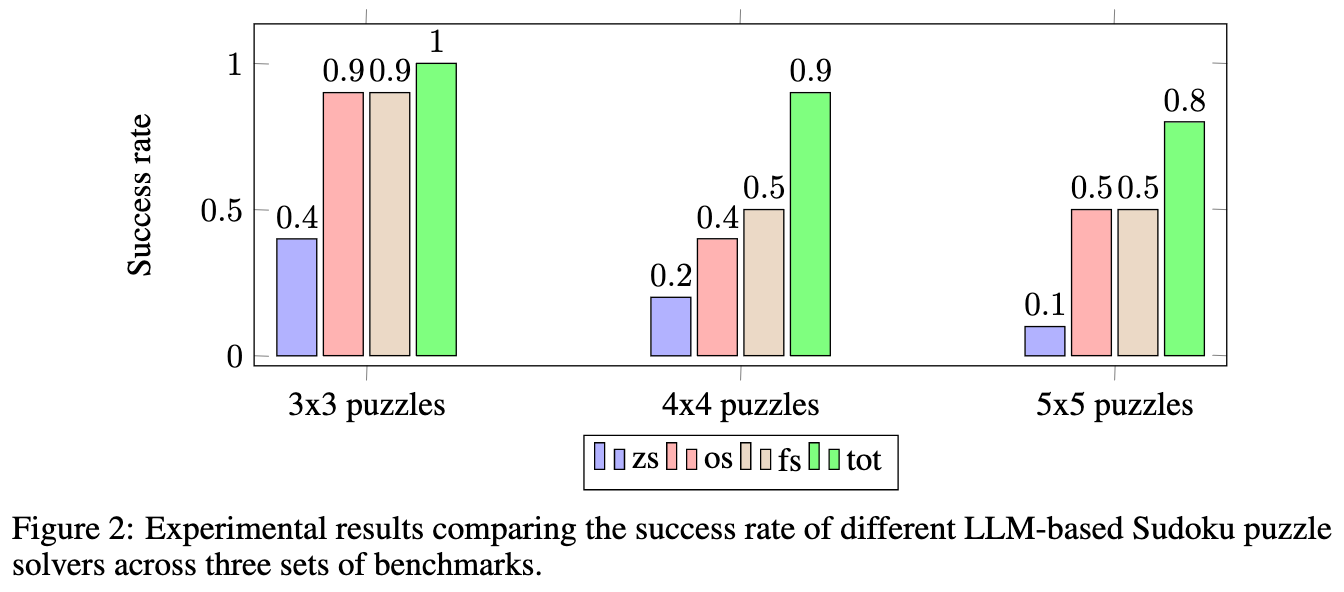
The results on Sudoku are quite amazing.
Image('NLP_images/tot_prompting_2.png', width=1000)
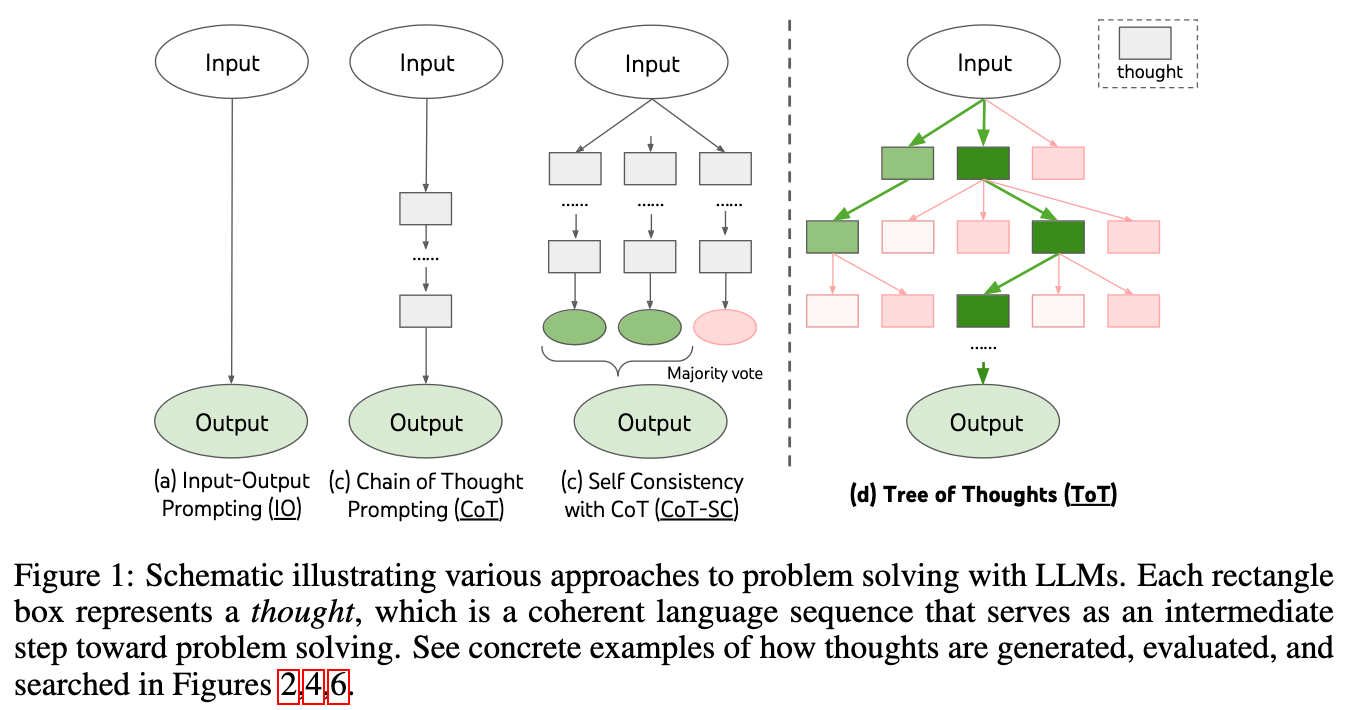
A generalization paper: Yao, Shunyu, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. “Tree of Thoughts: Deliberate Problem Solving with Large Language Models.” arXiv, May 17, 2023. https://doi.org/10.48550/arXiv.2305.10601.
Generalized CoT by exploring different reasoning paths and dropping them when deemed unsatisfactory, and following good ones to the end. It does this by exploring over coherent units of text (thoughts, i.e., intermediate steps in reasoning). An interesting parallel is drawn with Kahneman’s work on fast, automatic thinking (aka “System 1”) and slow, deliberate thinking (“System 2”).
Image('NLP_images/tot_prompting_3.png', width=800)
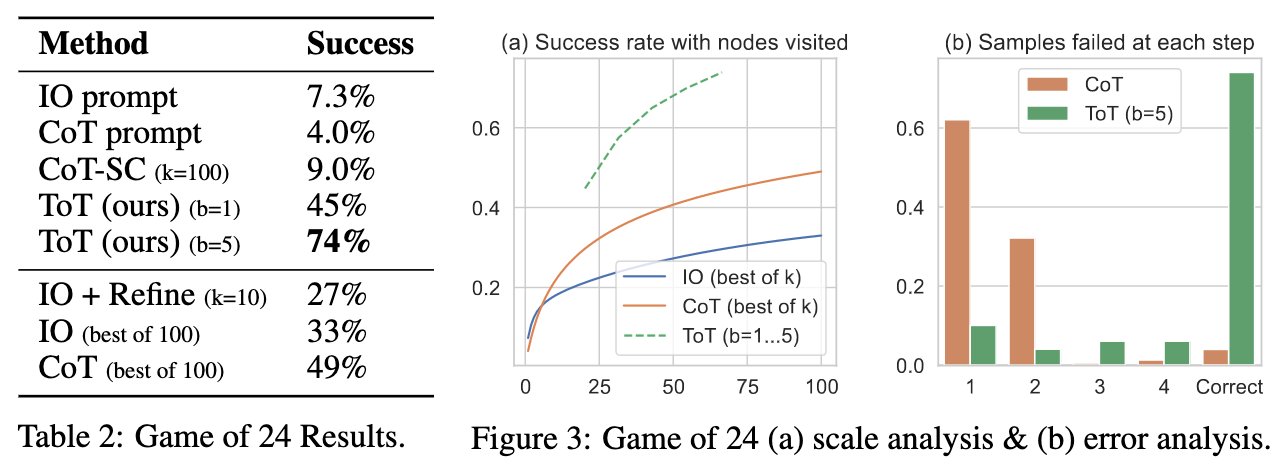
The results are quite impressive in comparison to standard CoT models.
Image('NLP_images/tot_prompting_4.png', width=1000)
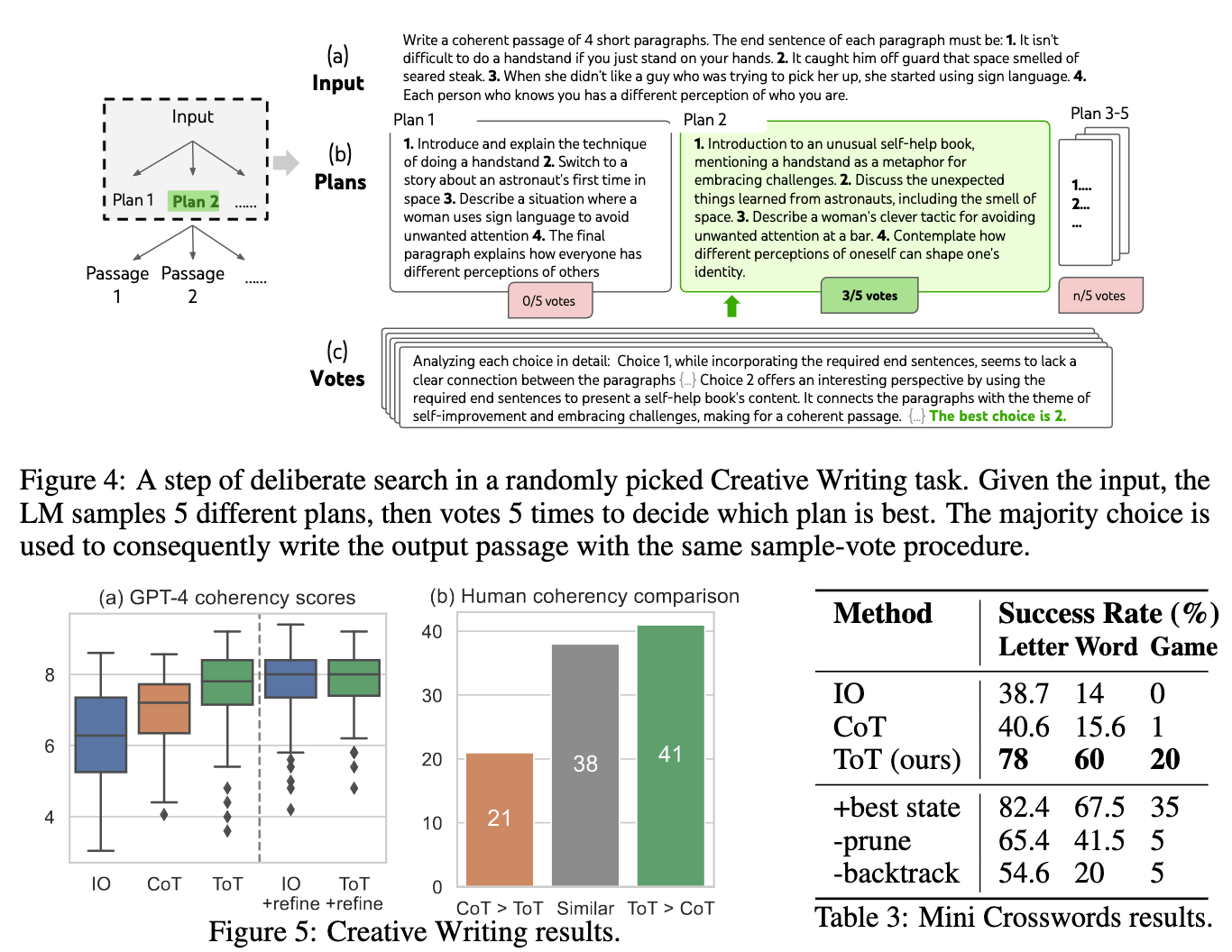
Good results are also obtained on creative writing tasks.
Image('NLP_images/tot_prompting_5.png', width=800)
44.18. Skeleton of Thoughts (SoT)#
The Skeleton-of-Thoughts (SoT) technique, a recent innovation in the field of Large Language Models (LLMs), represents a significant shift in how these models process and generate information. SoT was originally aimed to reduced the latency in end-to-end inference in LLMs but the results has had profound impact in the reasoning space. SoT is grounded in the observation that human thought and response patterns are often non-linear. Unlike traditional LLMs, which generate responses in a sequential manner, SoT introduces a two-stage process for answer generation. Initially, the LLM formulates a basic outline or ‘skeleton’ of the response. This skeleton encompasses the key points or elements of the answer. Following this, the model elaborates on each point in the skeleton simultaneously, rather than one after the other…
44.19. Language Models as Prompt Optimizers#
Tang, Xinyu, Xiaolei Wang, Wayne Xin Zhao, Siyuan Lu, Yaliang Li, and Ji-Rong Wen. “Unleashing the Potential of Large Language Models as Prompt Optimizers: An Analogical Analysis with Gradient-Based Model Optimizers.” arXiv, February 27, 2024. https://doi.org/10.48550/arXiv.2402.17564.
44.20. Mixture Of Prompts (MOP)#
There is extensive evidence in the survey literature that how a question affects the elicited response, see Kalton and Schuman (1982) [https://deepblue.lib.umich.edu/bitstream/handle/2027.42/146916/rssa04317.pdf] for an early paper. Surveys sometimes ask the same question in different ways multiple times to ensure the reliability and validity of the data. This technique, called “questionnaire validation,” helps to minimize response bias and increases the likelihood of obtaining accurate and consistent results. By asking the same question in different ways, researchers can cross-validate responses and identify any inconsistencies or contradictions, thereby improving the overall quality of the data collected. Additionally, varying the phrasing of a question can help capture nuances in respondents’ attitudes and perceptions, providing a more comprehensive understanding of the topic being studied.
Why not use multiple versions of the same question when prompting and then use (i) the answer with the highest quality score, or (ii) a combination of the top K answers? Call this the Mixture Of Prompts (MOP) approach. [Though it seems to be already done in Auto-Cot and Self-Consistency.]
44.21. Reflection#
This is the idea that when you prompt an LLM it gives back a not so ideal answer, so you prompt it again with a critique of the previous response and some more guidance — it then returns a better answer. Andrew Ng calls this “Reflection”, https://www.deeplearning.ai/the-batch/issue-242/.
References on prompting (more to read):
44.22. Sentiment Analysis#
This can be zero-shot, one-shot, or few-shot.
def generate_response(prompt, tokenizer, model):
# inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
inputs = tokenizer(prompt, return_tensors="pt")
generate_ids = model.generate(inputs.input_ids, max_new_tokens=512, do_sample=True) #, temperature=0.0)
response = tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
response = response.split(prompt)[-1]
return response
# Load model directly
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-t5-base")
prompt = """ Classify the following text as Positive or Negative \
text: The movie was terrific! It was worth watching again. \
output: Format the response as a JSON object with text and class keys. """
res = generate_response(prompt, tokenizer, model)
p80(res)
Positive
prompt = """ Classify the following text as Positive or Negative \
text: The stock market crashed today with the Dow dropping 10 percent. \
output: Format the response as a JSON object with text and class keys. """
res = generate_response(prompt, tokenizer, model)
p80(res)
Negative
44.23. Code Generation#
We use Salesforce’s Python program foundation model. https://huggingface.co/Salesforce/codegen-350M-mono
%%time
def generate_response(prompt, tokenizer, model):
# inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
inputs = tokenizer(prompt, return_tensors="pt")
generate_ids = model.generate(inputs.input_ids, max_new_tokens=512, do_sample=True) #, temperature=0.0)
response = tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
response = response.split(prompt)[-1]
return response
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen-350M-mono")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen-350M-mono")
Some weights of the model checkpoint at Salesforce/codegen-350M-mono were not used when initializing CodeGenForCausalLM: ['transformer.h.0.attn.causal_mask', 'transformer.h.1.attn.causal_mask', 'transformer.h.10.attn.causal_mask', 'transformer.h.11.attn.causal_mask', 'transformer.h.12.attn.causal_mask', 'transformer.h.13.attn.causal_mask', 'transformer.h.14.attn.causal_mask', 'transformer.h.15.attn.causal_mask', 'transformer.h.16.attn.causal_mask', 'transformer.h.17.attn.causal_mask', 'transformer.h.18.attn.causal_mask', 'transformer.h.19.attn.causal_mask', 'transformer.h.2.attn.causal_mask', 'transformer.h.3.attn.causal_mask', 'transformer.h.4.attn.causal_mask', 'transformer.h.5.attn.causal_mask', 'transformer.h.6.attn.causal_mask', 'transformer.h.7.attn.causal_mask', 'transformer.h.8.attn.causal_mask', 'transformer.h.9.attn.causal_mask']
- This IS expected if you are initializing CodeGenForCausalLM from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing CodeGenForCausalLM from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
prompt = """ Write a Python program to add two integers """
res = generate_response(prompt, tokenizer, model)
res
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
'\r\n# a and b \r\n# till which a is less \r\n# than b and which a is greater \r\n# than b \r\n\r\nnum1 = int(input("enter a: " ))\r\n\r\nnum2 = int(input("enter b: " ))\r\n\r\n\r\nif num1 <= num2: \r\n if (num1 < num2):\r\n print("Enter less number: " "num1 < num2: ", num1)\r\n else:\r\n print("Enter less number: " "num2 > num1: ", num2)\r\n \r\n \r\nelif num1 > num2:\r\n print("Enter greater number: " "num2 > num1: ", num2)\r\nelse:\r\n print("Either the numbers are equal or num1 is greater. Enter a: " "num1 = ", num1, " & b:", num2, sep=" ")'
print(res)
# a and b
# till which a is less
# than b and which a is greater
# than b
num1 = int(input("enter a: " ))
num2 = int(input("enter b: " ))
if num1 <= num2:
if (num1 < num2):
print("Enter less number: " "num1 < num2: ", num1)
else:
print("Enter less number: " "num2 > num1: ", num2)
elif num1 > num2:
print("Enter greater number: " "num2 > num1: ", num2)
else:
print("Either the numbers are equal or num1 is greater. Enter a: " "num1 = ", num1, " & b:", num2, sep=" ")
A bigger LLM returns far better results.
prompt = """ Write a Python program to add two integers """
res = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role":"user", "content":prompt}]
)
p80(prompt + '\n\n' + res.choices[0].message.content)
Write a Python program to add two integers # Prompt the user to enter two
integers num1 = int(input("Enter the first integer: ")) num2 = int(input("Enter
the second integer: ")) # Add the two integers sum = num1 + num2 # Display the
result print("The sum of", num1, "and", num2, "is", sum)
print(res.choices[0].message.content)
# Prompt the user to enter two integers
num1 = int(input("Enter the first integer: "))
num2 = int(input("Enter the second integer: "))
# Add the two integers
sum = num1 + num2
# Display the result
print("The sum of", num1, "and", num2, "is", sum)
44.24. Recognition of parts of speech, entities, etc.#
We use the IMDB summary of the Godfather to run some NER.
prompt = """ Extract all the adjectives from the following text. \
text: Don Vito Corleone, head of a mafia family, decides to hand over his empire to his youngest son Michael. However, his decision unintentionally puts the lives of his loved ones in grave danger.
"""
res = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role":"user", "content":prompt}],
temperature=0.0
)
p80(prompt + '\n\n' + res.choices[0].message.content)
Extract all the adjectives from the following text. text: Don Vito Corleone,
head of a mafia family, decides to hand over his empire to his youngest son
Michael. However, his decision unintentionally puts the lives of his loved ones
in grave danger. 1. youngest 2. grave
%%time
# Same with the HF model
# Load model directly
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-t5-base")
res = generate_response(prompt, tokenizer, model)
res
CPU times: user 788 ms, sys: 386 ms, total: 1.17 s
Wall time: 5.53 s
'head'
44.25. Text Generation#
We use OpenAI completions API here.
from openai import OpenAI
client = OpenAI()
res = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="Write an introduction to a Nobel prize winner.",
max_tokens=200
)
res
Completion(id='cmpl-CbGoFmwD5UOrdE56PfAhsE0bCudtx', choices=[CompletionChoice(finish_reason='stop', index=0, logprobs=None, text='\n\n[Name] is a world-renowned scientist whose groundbreaking research has earned them one of the highest honors in the world - the Nobel Prize. Their contributions to the field of [field of study] have revolutionized our understanding of [specific topic] and have paved the way for countless scientific advancements. With a career spanning [number] years, [Name] has made significant and lasting impacts in [their specific area of research]. Their innovative ideas, relentless dedication, and unwavering commitment to furthering human knowledge have solidified their position as a true pioneer in their field. Let us delve deeper into the remarkable journey and achievements of this distinguished Nobel laureate.')], created=1762998787, model='gpt-3.5-turbo-instruct:20230824-v2', object='text_completion', system_fingerprint=None, usage=CompletionUsage(completion_tokens=133, prompt_tokens=9, total_tokens=142, completion_tokens_details=None, prompt_tokens_details=None))
p80(res.choices[0].text)
[Name] is a world-renowned scientist whose groundbreaking research has earned
them one of the highest honors in the world - the Nobel Prize. Their
contributions to the field of [field of study] have revolutionized our
understanding of [specific topic] and have paved the way for countless
scientific advancements. With a career spanning [number] years, [Name] has made
significant and lasting impacts in [their specific area of research]. Their
innovative ideas, relentless dedication, and unwavering commitment to furthering
human knowledge have solidified their position as a true pioneer in their field.
Let us delve deeper into the remarkable journey and achievements of this
distinguished Nobel laureate.
res = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="Write a syllabus outline for a course on natural language processing.",
max_tokens=500
)
p80(res.choices[0].text)
I. Course Title: Natural Language Processing II. Course Description: This
course introduces students to the fundamentals of Natural Language Processing
(NLP) – a branch of artificial intelligence that focuses on enabling computers
to understand and process human language. Students will learn about the
different techniques and applications of NLP, and gain hands-on experience in
developing NLP models. III. Course Objectives: - Understand the basic principles
and concepts of NLP - Familiarize with the various NLP techniques and algorithms
- Learn how to process and analyze natural language data - Gain the skills to
build and evaluate NLP models - Apply NLP techniques to solve real-world
problems IV. Course Outline: Module 1: Introduction to NLP - Overview of NLP and
its applications - History and evolution of NLP - Challenges and limitations of
NLP Module 2: NLP Fundamentals - Linguistic and mathematical foundations of NLP
- Data preprocessing and cleaning techniques - Feature extraction and
representation Module 3: Text Processing and Analysis - Tokenization and Part-
of-Speech tagging - Sentiment analysis and opinion mining - Topic modeling and
text classification Module 4: NLP Techniques - Statistical and rule-based NLP
models - N-gram language models and word embeddings - Language generation and
translation Module 5: NLP Applications - Speech recognition and natural language
understanding - Chatbots and conversational agents - Information retrieval and
question-answering systems Module 6: NLP Evaluation and Assessment - Metrics for
evaluating NLP models - Techniques for improving model performance - Ethical
considerations in NLP V. Course Requirements: - Satisfactory completion of
assignments, projects, and exams - Active participation in class discussions and
activities VI. Recommended Textbook: - “Natural Language Processing: A
Comprehensive Reference” by Nitin Indurkhya and Fred J. Damerau VII. Additional
Resources: - Articles and papers from academic journals and conferences - Online
tutorials and videos VIII. Grading: - Assignments and projects: 40% - Midterm
exam: 20% - Final exam: 25% - Class participation: 15% IX. Course Policies: -
Attendance is mandatory for all classes - Late submissions will not be accepted
unless prior arrangements have been made - Plagiarism and cheating will not be
tolerated and will result
44.26. Research#
Step back prompting. Google DeepMind introduced Step-Back Prompting, elevating large language model accuracy by up to 36%. This technique involves posing a general question before the main task, allowing better comprehension and retrieval of background data. Tests on language models PaLM-2L and GPT-4 showed improvements, particularly in multi-step reasoning tasks across physics, chemistry, and temporal knowledge-based questions, surpassing GPT-4 in accuracy.
Mind Maps with AI Prompts.
Visual In-Context Prompting: https://arxiv.org/abs/2311.13601
Francois Chollet – “How I Think About Prompt Engineering”: An interesting take on a LLM as a database of vector programs and prompts as program keys and program input. These vector programs are highly non-linear functions that map the latent embedding space unto itself. https://fchollet.substack.com/p/how-i-think-about-llm-prompt-engineering
Google doc on context engineering: https://www.kaggle.com/whitepaper-context-engineering-sessions-and-memory
44.27. DSPy#
Pronounced “dee-ess-pi”, this stands for Declarative Self-improving Python, see: https://dspy.ai.
The main idea in DSPy is to program prompts in place of fixed strings. The tag line on the GitHub repo (stanfordnlp/dspy) is “Programming–not Prompting–Language Models”.
Fixed hard-coded prompt templates are strings and do not generalize across domains and language models. Hence they are brittle.
References:
The original paper: https://arxiv.org/abs/2212.14024
The paper about modules and optimizers: https://arxiv.org/abs/2312.13382
44.28. DSPy Components#
Signatures: These abstract away prompting. They tell the LM what to do and leave it to the LM to figure out how to do it.
Modules: These abstract away prompting techniques, such as Predict or Chain of Thought, that we looked at above. They enable combining multiple prompting techniques into a pipeline. Modules help you describe AI behavior as code, not strings.
Optimizers: These abstract away prompt optimization. You provide examples and accuracy metrics and the optimizer develops the best prompts that optimize for the chosen metric.
!pip install -U dspy --quiet
%run keys.ipynb
import dspy
lm = dspy.LM('openai/gpt-4o-mini', api_key=OPENAI_KEY)
dspy.configure(lm=lm)
44.29. Using Signatures#
These are easy to define as shown below. You can then define classes that inherit these signatures.
sign1 = dspy.Signature('question -> answer: str')
sign2 = dspy.Signature('question, context -> answer: str')
sign3 = dspy.Signature('document -> summary')
class QA(dspy.Signature):
"""Ask a question and get a brief answer."""
question = dspy.InputField()
answer = dspy.OutputField(desc="One sentence only", prefix="Answer: ")
get_response = dspy.Predict(QA)
pred = get_response(question="What is the capital of France?")
pred
Prediction(
answer='The capital of France is Paris.'
)
44.30. Using Modules#
The examples below are adapted from the DSPy documentation for various modules.
# Use examples for math in DSPy documentation
math = dspy.ChainOfThought("question -> answer: float")
math(question="Two dice are tossed. What is the probability that the sum equals two?")
Prediction(
reasoning='To find the probability that the sum of two dice equals two, we first determine the total number of possible outcomes when two dice are tossed. Each die has 6 faces, so the total number of outcomes is 6 * 6 = 36.\n\nNext, we identify the number of favorable outcomes where the sum equals two. The only combination that achieves this is when both dice show 1 (1 + 1 = 2). Therefore, there is only 1 favorable outcome.\n\nThe probability is calculated as the ratio of the number of favorable outcomes to the total number of outcomes, which is:\n\nP(sum = 2) = Number of favorable outcomes / Total outcomes = 1 / 36.',
answer=0.027777777777777776
)
# Retrieval Augmented Generation
# https://github.com/stanford-futuredata/ColBERT
# %pip install -U faiss-cpu # or faiss-gpu if you have a GPU
!pip install -U faiss-cpu
Collecting faiss-cpu
Downloading faiss_cpu-1.12.0-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.metadata (5.1 kB)
Requirement already satisfied: numpy<3.0,>=1.25.0 in /usr/local/lib/python3.12/dist-packages (from faiss-cpu) (2.0.2)
Requirement already satisfied: packaging in /usr/local/lib/python3.12/dist-packages (from faiss-cpu) (25.0)
Downloading faiss_cpu-1.12.0-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl (31.4 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 31.4/31.4 MB 37.9 MB/s 0:00:00
?25hInstalling collected packages: faiss-cpu
Successfully installed faiss-cpu-1.12.0
import requests
def download_file(url, filename):
response = requests.get(url)
response.raise_for_status() # Raise an exception for bad status codes
with open(filename, 'wb') as f:
f.write(response.content)
# download("https://huggingface.co/dspy/cache/resolve/main/ragqa_arena_tech_corpus.jsonl")
download_file("https://huggingface.co/dspy/cache/resolve/main/ragqa_arena_tech_corpus.jsonl", "ragqa_arena_tech_corpus.jsonl")
!pip install ujson
import ujson
max_characters = 6000 # for truncating >99th percentile of documents
topk_docs_to_retrieve = 5 # number of documents to retrieve per search query
with open("ragqa_arena_tech_corpus.jsonl") as f:
corpus = [ujson.loads(line)['text'][:max_characters] for line in f]
print("Length of original corpus:", len(corpus))
corpus = corpus[:10] # keeping it small
print(f"Loaded {len(corpus)} documents. Will encode them below.")
embedder = dspy.Embedder('openai/text-embedding-3-small', dimensions=512)
search = dspy.retrievers.Embeddings(embedder=embedder, corpus=corpus, k=topk_docs_to_retrieve)
Collecting ujson
Downloading ujson-5.11.0-cp312-cp312-manylinux_2_24_x86_64.manylinux_2_28_x86_64.whl.metadata (9.4 kB)
Downloading ujson-5.11.0-cp312-cp312-manylinux_2_24_x86_64.manylinux_2_28_x86_64.whl (57 kB)
Installing collected packages: ujson
Successfully installed ujson-5.11.0
class RAG(dspy.Module):
def __init__(self):
self.respond = dspy.ChainOfThought('context, question -> response')
def forward(self, question):
context = search(question).passages
return self.respond(context=context, question=question)
rag = RAG()
rag(question="what are high memory and low memory on linux?")
Prediction(
reasoning='High memory and low memory in Linux refer to different types of memory management in the operating system. High memory typically refers to the memory space beyond the 4GB limit for 32-bit systems, commonly used for applications in 64-bit systems, while low memory refers to the region that is directly accessible by the kernel without the need for additional mechanisms. Low memory addresses are used for essential tasks and kernel operations, while high memory is allocated for user processes. Understanding these concepts is important for optimizing memory usage and performance in Linux systems.',
response='In Linux, high memory refers to the memory that is not directly accessible by the kernel due to address space limitations, typically beyond 4GB in 32-bit architecture. Low memory, on the other hand, is the portion of memory that can be directly accessed by the kernel without additional handling. The distinction is crucial for effective memory management and system performance, especially in systems that utilize a mix of 32-bit and 64-bit architectures.'
)
# Classification using the Predict module
from typing import Literal
class Classify(dspy.Signature):
"""Classify sentiment of a given sentence."""
sentence: str = dspy.InputField()
sentiment: Literal['positive', 'negative', 'neutral'] = dspy.OutputField()
confidence: float = dspy.OutputField()
classify = dspy.Predict(Classify)
classify(sentence="This book was super fun to read, though not the last chapter.")
Prediction(
sentiment='positive',
confidence=0.87
)
# Information Extraction
class ExtractInfo(dspy.Signature):
"""Extract structured information from text."""
text: str = dspy.InputField()
title: str = dspy.OutputField()
headings: list[str] = dspy.OutputField()
entities: list[dict[str, str]] = dspy.OutputField(desc="a list of entities and their metadata")
module = dspy.Predict(ExtractInfo)
text = "Apple Inc. announced its latest iPhone 14 today." \
"The CEO, Tim Cook, highlighted its new features in a press release."
response = module(text=text)
print(response.title)
print(response.headings)
print(response.entities)
Apple Inc. Announces iPhone 14
['Announcement Overview', "CEO's Highlights", 'New Features']
[{'Company': 'Apple Inc.'}, {'Product': 'iPhone 14'}, {'CEO': 'Tim Cook'}]
# Agents using Tools
def evaluate_math(expression: str):
return dspy.PythonInterpreter({}).execute(expression)
def search_wikipedia(query: str):
results = dspy.ColBERTv2(url='http://20.102.90.50:2017/wiki17_abstracts')(query, k=3)
return [x['text'] for x in results]
react = dspy.ReAct("question -> answer: float", tools=[evaluate_math, search_wikipedia])
pred = react(question="What is 9362158 divided by the year of birth of David Gregory of Kinnairdy castle?")
print(pred.answer)
5648.057831325301
44.31. Using Optimizers#
Colbertv2: stanford-futuredata/ColBERT
HotPotQA dataset: https://hotpotqa.github.io
import dspy
from dspy.datasets import HotPotQA
dspy.configure(lm=dspy.LM('openai/gpt-4o-mini'))
def search_wikipedia(query: str) -> list[str]:
results = dspy.ColBERTv2(url='http://20.102.90.50:2017/wiki17_abstracts')(query, k=3)
return [x['text'] for x in results]
trainset = [x.with_inputs('question') for x in HotPotQA(train_seed=2024, train_size=10).train]
react = dspy.ReAct("question -> answer", tools=[search_wikipedia])
tp = dspy.MIPROv2(metric=dspy.evaluate.answer_exact_match, auto="light", num_threads=24)
optimized_react = tp.compile(react, trainset=trainset)
2025/11/13 01:55:06 INFO dspy.teleprompt.mipro_optimizer_v2:
RUNNING WITH THE FOLLOWING LIGHT AUTO RUN SETTINGS:
num_trials: 20
minibatch: False
num_fewshot_candidates: 6
num_instruct_candidates: 3
valset size: 8
2025/11/13 01:55:06 INFO dspy.teleprompt.mipro_optimizer_v2:
==> STEP 1: BOOTSTRAP FEWSHOT EXAMPLES <==
2025/11/13 01:55:06 INFO dspy.teleprompt.mipro_optimizer_v2: These will be used as few-shot example candidates for our program and for creating instructions.
2025/11/13 01:55:06 INFO dspy.teleprompt.mipro_optimizer_v2: Bootstrapping N=6 sets of demonstrations...
Bootstrapping set 1/6
Bootstrapping set 2/6
Bootstrapping set 3/6
100%|██████████| 2/2 [00:25<00:00, 12.75s/it]
Bootstrapped 1 full traces after 1 examples for up to 1 rounds, amounting to 2 attempts.
Bootstrapping set 4/6
100%|██████████| 2/2 [00:01<00:00, 1.46it/s]
Bootstrapped 1 full traces after 1 examples for up to 1 rounds, amounting to 2 attempts.
Bootstrapping set 5/6
100%|██████████| 2/2 [00:01<00:00, 1.49it/s]
Bootstrapped 1 full traces after 1 examples for up to 1 rounds, amounting to 2 attempts.
Bootstrapping set 6/6
100%|██████████| 2/2 [00:01<00:00, 1.48it/s]
2025/11/13 01:55:35 INFO dspy.teleprompt.mipro_optimizer_v2:
==> STEP 2: PROPOSE INSTRUCTION CANDIDATES <==
2025/11/13 01:55:35 INFO dspy.teleprompt.mipro_optimizer_v2: We will use the few-shot examples from the previous step, a generated dataset summary, a summary of the program code, and a randomly selected prompting tip to propose instructions.
Bootstrapped 1 full traces after 1 examples for up to 1 rounds, amounting to 2 attempts.
2025/11/13 01:55:39 INFO dspy.teleprompt.mipro_optimizer_v2:
Proposing N=3 instructions...
2025/11/13 01:56:43 INFO dspy.teleprompt.mipro_optimizer_v2: Proposed Instructions for Predictor 0:
2025/11/13 01:56:43 INFO dspy.teleprompt.mipro_optimizer_v2: 0: Given the fields `question`, produce the fields `answer`.
You are an Agent. In each episode, you will be given the fields `question` as input. And you can see your past trajectory so far.
Your goal is to use one or more of the supplied tools to collect any necessary information for producing `answer`.
To do this, you will interleave next_thought, next_tool_name, and next_tool_args in each turn, and also when finishing the task.
After each tool call, you receive a resulting observation, which gets appended to your trajectory.
When writing next_thought, you may reason about the current situation and plan for future steps.
When selecting the next_tool_name and its next_tool_args, the tool must be one of:
(1) search_wikipedia. It takes arguments {'query': {'type': 'string'}}.
(2) finish, whose description is <desc>Marks the task as complete. That is, signals that all information for producing the outputs, i.e. `answer`, are now available to be extracted.</desc>. It takes arguments {}.
When providing `next_tool_args`, the value inside the field must be in JSON format
2025/11/13 01:56:43 INFO dspy.teleprompt.mipro_optimizer_v2: 1: You are an information retrieval agent specialized in film history. Your task is to answer user-provided questions by leveraging a Wikipedia search tool to extract relevant data. In each interaction, you will receive a `question` and a `trajectory` capturing your previous reasoning steps. Utilize the tools available to gather information and produce an accurate `answer`. Remember to interleave your `next_thought`, `next_tool_name`, and `next_tool_args` in each response while considering the trajectory of your reasoning. If your attempts to retrieve information fail, assess your existing knowledge to conclude and finish the task. Approach the question methodically, ensuring clarity and accuracy in your final answer.
2025/11/13 01:56:43 INFO dspy.teleprompt.mipro_optimizer_v2: 2: As an Agent, you will be answering key questions by navigating through a series of thought processes and tool-based information retrieval.
1. **Start with the provided `question`, analyzing its components to determine what is being specifically asked.**
2. **Develop a `next_thought` (a reasoning step) that outlines your initial understanding and what information you need to gather. This should involve assessing whether additional tools will be required to answer the query or if existing knowledge is sufficient.**
3. **Select your next action by deciding on a `next_tool_name`. You can either use:**
- `search_wikipedia` to gather information, or
- `finish` to conclude the search when you have sufficient data.
4. **If using `search_wikipedia`, formulate the `next_tool_args` in JSON format to specify your query. Ensure the query is clear and concise to fetch relevant information.**
5. **As you execute each tool, monitor the `trajectory`, which keeps track of previous thoughts, actions, and observations. Update your reasoning if previous attempts yield no satisfactory results.**
6. **When you feel you have accumulated enough data, finalize the task with the `finish` tool. Document the answer based on the information you have gathered (or existing knowledge).**
Use this structured approach iteratively until the task is completed, allowing for adjustments based on the information received through the tool results.
2025/11/13 01:56:43 INFO dspy.teleprompt.mipro_optimizer_v2:
2025/11/13 01:56:43 INFO dspy.teleprompt.mipro_optimizer_v2: Proposed Instructions for Predictor 1:
2025/11/13 01:56:43 INFO dspy.teleprompt.mipro_optimizer_v2: 0: Given the fields `question`, produce the fields `answer`.
2025/11/13 01:56:43 INFO dspy.teleprompt.mipro_optimizer_v2: 1: Given the question about the production studio of the films "That Darn Cat!" and "Never a Dull Moment," utilize the available tools to gather relevant information. If performing tool searches fails repeatedly, rely on prior knowledge to deduce the answer logically and complete the task with a structured reasoning process.
2025/11/13 01:56:43 INFO dspy.teleprompt.mipro_optimizer_v2: 2: You are about to embark on a high-stakes mission where you must retrieve crucial information to answer a pressing question related to film production. Given the question, you must analyze your past attempts to collect data and weave a logical path that integrates both reasoning and knowledge retrieval. Use the provided tools to gather as much information as possible, and when you encounter obstacles, put your reasoning skills to the test to finalize an answer. Remember, the success of your mission depends on the accuracy of your final answer, so proceed with care! Your task: Given the fields `question`, produce the fields `answer`.
2025/11/13 01:56:43 INFO dspy.teleprompt.mipro_optimizer_v2:
2025/11/13 01:56:43 INFO dspy.teleprompt.mipro_optimizer_v2: ==> STEP 3: FINDING OPTIMAL PROMPT PARAMETERS <==
2025/11/13 01:56:43 INFO dspy.teleprompt.mipro_optimizer_v2: We will evaluate the program over a series of trials with different combinations of instructions and few-shot examples to find the optimal combination using Bayesian Optimization.
2025/11/13 01:56:43 INFO dspy.teleprompt.mipro_optimizer_v2: == Trial 1 / 20 - Full Evaluation of Default Program ==
Average Metric: 0.00 / 8 (0.0%): 100%|██████████| 8/8 [00:28<00:00, 3.56s/it]
2025/11/13 01:57:12 INFO dspy.evaluate.evaluate: Average Metric: 0 / 8 (0.0%)
2025/11/13 01:57:12 INFO dspy.teleprompt.mipro_optimizer_v2: Default program score: 0.0
/usr/local/lib/python3.12/dist-packages/optuna/_experimental.py:32: ExperimentalWarning: Argument ``multivariate`` is an experimental feature. The interface can change in the future.
warnings.warn(
2025/11/13 01:57:12 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 2 / 20 =====
Average Metric: 0.00 / 8 (0.0%): 100%|██████████| 8/8 [00:12<00:00, 1.52s/it]
2025/11/13 01:57:24 INFO dspy.evaluate.evaluate: Average Metric: 0 / 8 (0.0%)
2025/11/13 01:57:24 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 0.0 with parameters ['Predictor 0: Instruction 1', 'Predictor 0: Few-Shot Set 3', 'Predictor 1: Instruction 2', 'Predictor 1: Few-Shot Set 0'].
2025/11/13 01:57:24 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0]
2025/11/13 01:57:24 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 0.0
2025/11/13 01:57:24 INFO dspy.teleprompt.mipro_optimizer_v2: ========================
2025/11/13 01:57:24 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 3 / 20 =====
Average Metric: 0.00 / 8 (0.0%): 100%|██████████| 8/8 [00:05<00:00, 1.50it/s]
2025/11/13 01:57:29 INFO dspy.evaluate.evaluate: Average Metric: 0 / 8 (0.0%)
2025/11/13 01:57:29 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 0.0 with parameters ['Predictor 0: Instruction 1', 'Predictor 0: Few-Shot Set 5', 'Predictor 1: Instruction 2', 'Predictor 1: Few-Shot Set 2'].
2025/11/13 01:57:29 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0]
2025/11/13 01:57:29 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 0.0
2025/11/13 01:57:29 INFO dspy.teleprompt.mipro_optimizer_v2: ========================
2025/11/13 01:57:29 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 4 / 20 =====
Average Metric: 1.00 / 8 (12.5%): 100%|██████████| 8/8 [00:11<00:00, 1.43s/it]
2025/11/13 01:57:41 INFO dspy.evaluate.evaluate: Average Metric: 1 / 8 (12.5%)
2025/11/13 01:57:41 INFO dspy.teleprompt.mipro_optimizer_v2: Best full score so far! Score: 12.5
2025/11/13 01:57:41 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 12.5 with parameters ['Predictor 0: Instruction 0', 'Predictor 0: Few-Shot Set 5', 'Predictor 1: Instruction 2', 'Predictor 1: Few-Shot Set 0'].
2025/11/13 01:57:41 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5]
2025/11/13 01:57:41 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 12.5
2025/11/13 01:57:41 INFO dspy.teleprompt.mipro_optimizer_v2: ========================
2025/11/13 01:57:41 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 5 / 20 =====
Average Metric: 0.00 / 8 (0.0%): 100%|██████████| 8/8 [00:10<00:00, 1.26s/it]
2025/11/13 01:57:51 INFO dspy.evaluate.evaluate: Average Metric: 0 / 8 (0.0%)
2025/11/13 01:57:51 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 0.0 with parameters ['Predictor 0: Instruction 2', 'Predictor 0: Few-Shot Set 5', 'Predictor 1: Instruction 1', 'Predictor 1: Few-Shot Set 4'].
2025/11/13 01:57:51 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5, 0.0]
2025/11/13 01:57:51 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 12.5
2025/11/13 01:57:51 INFO dspy.teleprompt.mipro_optimizer_v2: ========================
2025/11/13 01:57:51 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 6 / 20 =====
Average Metric: 1.00 / 8 (12.5%): 100%|██████████| 8/8 [00:03<00:00, 2.22it/s]
2025/11/13 01:57:55 INFO dspy.evaluate.evaluate: Average Metric: 1 / 8 (12.5%)
2025/11/13 01:57:55 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 12.5 with parameters ['Predictor 0: Instruction 2', 'Predictor 0: Few-Shot Set 5', 'Predictor 1: Instruction 2', 'Predictor 1: Few-Shot Set 2'].
2025/11/13 01:57:55 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5, 0.0, 12.5]
2025/11/13 01:57:55 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 12.5
2025/11/13 01:57:55 INFO dspy.teleprompt.mipro_optimizer_v2: ========================
2025/11/13 01:57:55 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 7 / 20 =====
Average Metric: 1.00 / 8 (12.5%): 100%|██████████| 8/8 [00:03<00:00, 2.49it/s]
2025/11/13 01:57:58 INFO dspy.evaluate.evaluate: Average Metric: 1 / 8 (12.5%)
2025/11/13 01:57:58 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 12.5 with parameters ['Predictor 0: Instruction 0', 'Predictor 0: Few-Shot Set 5', 'Predictor 1: Instruction 0', 'Predictor 1: Few-Shot Set 0'].
2025/11/13 01:57:58 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5, 0.0, 12.5, 12.5]
2025/11/13 01:57:58 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 12.5
2025/11/13 01:57:58 INFO dspy.teleprompt.mipro_optimizer_v2: ========================
2025/11/13 01:57:58 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 8 / 20 =====
Average Metric: 0.00 / 8 (0.0%): 100%|██████████| 8/8 [00:03<00:00, 2.35it/s]
2025/11/13 01:58:01 INFO dspy.evaluate.evaluate: Average Metric: 0 / 8 (0.0%)
2025/11/13 01:58:02 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 0.0 with parameters ['Predictor 0: Instruction 1', 'Predictor 0: Few-Shot Set 2', 'Predictor 1: Instruction 2', 'Predictor 1: Few-Shot Set 1'].
2025/11/13 01:58:02 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5, 0.0, 12.5, 12.5, 0.0]
2025/11/13 01:58:02 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 12.5
2025/11/13 01:58:02 INFO dspy.teleprompt.mipro_optimizer_v2: ========================
2025/11/13 01:58:02 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 9 / 20 =====
Average Metric: 0.00 / 8 (0.0%): 100%|██████████| 8/8 [00:08<00:00, 1.12s/it]
2025/11/13 01:58:11 INFO dspy.evaluate.evaluate: Average Metric: 0 / 8 (0.0%)
2025/11/13 01:58:11 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 0.0 with parameters ['Predictor 0: Instruction 1', 'Predictor 0: Few-Shot Set 0', 'Predictor 1: Instruction 0', 'Predictor 1: Few-Shot Set 0'].
2025/11/13 01:58:11 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5, 0.0, 12.5, 12.5, 0.0, 0.0]
2025/11/13 01:58:11 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 12.5
2025/11/13 01:58:11 INFO dspy.teleprompt.mipro_optimizer_v2: ========================
2025/11/13 01:58:11 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 10 / 20 =====
Average Metric: 0.00 / 8 (0.0%): 100%|██████████| 8/8 [00:04<00:00, 1.65it/s]
2025/11/13 01:58:15 INFO dspy.evaluate.evaluate: Average Metric: 0 / 8 (0.0%)
2025/11/13 01:58:15 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 0.0 with parameters ['Predictor 0: Instruction 0', 'Predictor 0: Few-Shot Set 0', 'Predictor 1: Instruction 1', 'Predictor 1: Few-Shot Set 4'].
2025/11/13 01:58:15 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5, 0.0, 12.5, 12.5, 0.0, 0.0, 0.0]
2025/11/13 01:58:15 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 12.5
2025/11/13 01:58:15 INFO dspy.teleprompt.mipro_optimizer_v2: =========================
2025/11/13 01:58:15 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 11 / 20 =====
Average Metric: 0.00 / 8 (0.0%): 100%|██████████| 8/8 [00:07<00:00, 1.06it/s]
2025/11/13 01:58:23 INFO dspy.evaluate.evaluate: Average Metric: 0 / 8 (0.0%)
2025/11/13 01:58:23 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 0.0 with parameters ['Predictor 0: Instruction 0', 'Predictor 0: Few-Shot Set 1', 'Predictor 1: Instruction 2', 'Predictor 1: Few-Shot Set 0'].
2025/11/13 01:58:23 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5, 0.0, 12.5, 12.5, 0.0, 0.0, 0.0, 0.0]
2025/11/13 01:58:23 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 12.5
2025/11/13 01:58:23 INFO dspy.teleprompt.mipro_optimizer_v2: =========================
2025/11/13 01:58:23 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 12 / 20 =====
Average Metric: 1.00 / 8 (12.5%): 100%|██████████| 8/8 [00:00<00:00, 19.62it/s]
2025/11/13 01:58:24 INFO dspy.evaluate.evaluate: Average Metric: 1 / 8 (12.5%)
2025/11/13 01:58:24 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 12.5 with parameters ['Predictor 0: Instruction 2', 'Predictor 0: Few-Shot Set 5', 'Predictor 1: Instruction 2', 'Predictor 1: Few-Shot Set 3'].
2025/11/13 01:58:24 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5, 0.0, 12.5, 12.5, 0.0, 0.0, 0.0, 0.0, 12.5]
2025/11/13 01:58:24 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 12.5
2025/11/13 01:58:24 INFO dspy.teleprompt.mipro_optimizer_v2: =========================
2025/11/13 01:58:24 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 13 / 20 =====
Average Metric: 2.00 / 8 (25.0%): 100%|██████████| 8/8 [00:03<00:00, 2.59it/s]
2025/11/13 01:58:27 INFO dspy.evaluate.evaluate: Average Metric: 2 / 8 (25.0%)
2025/11/13 01:58:27 INFO dspy.teleprompt.mipro_optimizer_v2: Best full score so far! Score: 25.0
2025/11/13 01:58:27 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 25.0 with parameters ['Predictor 0: Instruction 2', 'Predictor 0: Few-Shot Set 4', 'Predictor 1: Instruction 0', 'Predictor 1: Few-Shot Set 2'].
2025/11/13 01:58:27 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5, 0.0, 12.5, 12.5, 0.0, 0.0, 0.0, 0.0, 12.5, 25.0]
2025/11/13 01:58:27 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 25.0
2025/11/13 01:58:27 INFO dspy.teleprompt.mipro_optimizer_v2: =========================
2025/11/13 01:58:27 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 14 / 20 =====
Average Metric: 2.00 / 8 (25.0%): 100%|██████████| 8/8 [00:00<00:00, 26.53it/s]
2025/11/13 01:58:27 INFO dspy.evaluate.evaluate: Average Metric: 2 / 8 (25.0%)
2025/11/13 01:58:27 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 25.0 with parameters ['Predictor 0: Instruction 2', 'Predictor 0: Few-Shot Set 4', 'Predictor 1: Instruction 0', 'Predictor 1: Few-Shot Set 2'].
2025/11/13 01:58:27 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5, 0.0, 12.5, 12.5, 0.0, 0.0, 0.0, 0.0, 12.5, 25.0, 25.0]
2025/11/13 01:58:27 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 25.0
2025/11/13 01:58:27 INFO dspy.teleprompt.mipro_optimizer_v2: =========================
2025/11/13 01:58:27 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 15 / 20 =====
Average Metric: 2.00 / 8 (25.0%): 100%|██████████| 8/8 [00:00<00:00, 19.48it/s]
2025/11/13 01:58:28 INFO dspy.evaluate.evaluate: Average Metric: 2 / 8 (25.0%)
2025/11/13 01:58:28 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 25.0 with parameters ['Predictor 0: Instruction 2', 'Predictor 0: Few-Shot Set 4', 'Predictor 1: Instruction 0', 'Predictor 1: Few-Shot Set 5'].
2025/11/13 01:58:28 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5, 0.0, 12.5, 12.5, 0.0, 0.0, 0.0, 0.0, 12.5, 25.0, 25.0, 25.0]
2025/11/13 01:58:28 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 25.0
2025/11/13 01:58:28 INFO dspy.teleprompt.mipro_optimizer_v2: =========================
2025/11/13 01:58:28 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 16 / 20 =====
Average Metric: 2.00 / 8 (25.0%): 100%|██████████| 8/8 [00:00<00:00, 26.53it/s]
2025/11/13 01:58:28 INFO dspy.evaluate.evaluate: Average Metric: 2 / 8 (25.0%)
2025/11/13 01:58:28 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 25.0 with parameters ['Predictor 0: Instruction 2', 'Predictor 0: Few-Shot Set 2', 'Predictor 1: Instruction 0', 'Predictor 1: Few-Shot Set 2'].
2025/11/13 01:58:28 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5, 0.0, 12.5, 12.5, 0.0, 0.0, 0.0, 0.0, 12.5, 25.0, 25.0, 25.0, 25.0]
2025/11/13 01:58:28 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 25.0
2025/11/13 01:58:28 INFO dspy.teleprompt.mipro_optimizer_v2: =========================
2025/11/13 01:58:28 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 17 / 20 =====
Average Metric: 0.00 / 8 (0.0%): 100%|██████████| 8/8 [00:00<00:00, 19.39it/s]
2025/11/13 01:58:29 INFO dspy.evaluate.evaluate: Average Metric: 0 / 8 (0.0%)
2025/11/13 01:58:29 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 0.0 with parameters ['Predictor 0: Instruction 2', 'Predictor 0: Few-Shot Set 4', 'Predictor 1: Instruction 1', 'Predictor 1: Few-Shot Set 2'].
2025/11/13 01:58:29 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5, 0.0, 12.5, 12.5, 0.0, 0.0, 0.0, 0.0, 12.5, 25.0, 25.0, 25.0, 25.0, 0.0]
2025/11/13 01:58:29 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 25.0
2025/11/13 01:58:29 INFO dspy.teleprompt.mipro_optimizer_v2: =========================
2025/11/13 01:58:29 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 18 / 20 =====
Average Metric: 2.00 / 8 (25.0%): 100%|██████████| 8/8 [00:00<00:00, 20.08it/s]
2025/11/13 01:58:29 INFO dspy.evaluate.evaluate: Average Metric: 2 / 8 (25.0%)
2025/11/13 01:58:29 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 25.0 with parameters ['Predictor 0: Instruction 2', 'Predictor 0: Few-Shot Set 4', 'Predictor 1: Instruction 0', 'Predictor 1: Few-Shot Set 2'].
2025/11/13 01:58:29 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5, 0.0, 12.5, 12.5, 0.0, 0.0, 0.0, 0.0, 12.5, 25.0, 25.0, 25.0, 25.0, 0.0, 25.0]
2025/11/13 01:58:29 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 25.0
2025/11/13 01:58:29 INFO dspy.teleprompt.mipro_optimizer_v2: =========================
2025/11/13 01:58:29 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 19 / 20 =====
Average Metric: 1.00 / 8 (12.5%): 100%|██████████| 8/8 [00:03<00:00, 2.55it/s]
2025/11/13 01:58:32 INFO dspy.evaluate.evaluate: Average Metric: 1 / 8 (12.5%)
2025/11/13 01:58:32 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 12.5 with parameters ['Predictor 0: Instruction 1', 'Predictor 0: Few-Shot Set 4', 'Predictor 1: Instruction 0', 'Predictor 1: Few-Shot Set 3'].
2025/11/13 01:58:32 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5, 0.0, 12.5, 12.5, 0.0, 0.0, 0.0, 0.0, 12.5, 25.0, 25.0, 25.0, 25.0, 0.0, 25.0, 12.5]
2025/11/13 01:58:32 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 25.0
2025/11/13 01:58:32 INFO dspy.teleprompt.mipro_optimizer_v2: =========================
2025/11/13 01:58:32 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 20 / 20 =====
Average Metric: 1.00 / 8 (12.5%): 100%|██████████| 8/8 [00:12<00:00, 1.56s/it]
2025/11/13 01:58:45 INFO dspy.evaluate.evaluate: Average Metric: 1 / 8 (12.5%)
2025/11/13 01:58:45 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 12.5 with parameters ['Predictor 0: Instruction 2', 'Predictor 0: Few-Shot Set 1', 'Predictor 1: Instruction 0', 'Predictor 1: Few-Shot Set 4'].
2025/11/13 01:58:45 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5, 0.0, 12.5, 12.5, 0.0, 0.0, 0.0, 0.0, 12.5, 25.0, 25.0, 25.0, 25.0, 0.0, 25.0, 12.5, 12.5]
2025/11/13 01:58:45 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 25.0
2025/11/13 01:58:45 INFO dspy.teleprompt.mipro_optimizer_v2: =========================
2025/11/13 01:58:45 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 21 / 20 =====
Average Metric: 1.00 / 8 (12.5%): 100%|██████████| 8/8 [00:03<00:00, 2.21it/s]
2025/11/13 01:58:49 INFO dspy.evaluate.evaluate: Average Metric: 1 / 8 (12.5%)
2025/11/13 01:58:49 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 12.5 with parameters ['Predictor 0: Instruction 2', 'Predictor 0: Few-Shot Set 4', 'Predictor 1: Instruction 2', 'Predictor 1: Few-Shot Set 1'].
2025/11/13 01:58:49 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [0.0, 0.0, 0.0, 12.5, 0.0, 12.5, 12.5, 0.0, 0.0, 0.0, 0.0, 12.5, 25.0, 25.0, 25.0, 25.0, 0.0, 25.0, 12.5, 12.5, 12.5]
2025/11/13 01:58:49 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 25.0
2025/11/13 01:58:49 INFO dspy.teleprompt.mipro_optimizer_v2: =========================
2025/11/13 01:58:49 INFO dspy.teleprompt.mipro_optimizer_v2: Returning best identified program with score 25.0!
# question = "What's the name of the castle that David Gregory inherited?"
# optimized_react(context=search_wikipedia(question), question=question)
To learn more about programming with DSPy, see: https://dspy.ai/learn/
44.32. Reasoning LLMs#
This extends the Chain of Thought (CoT) approach. For a detailed look at the architecture of these models, see: https://magazine.sebastianraschka.com/p/understanding-reasoning-llms